元学习 学习如何学习
What is Meta
元学习是独立于机器学习的另一个学问,研究学习如何学习
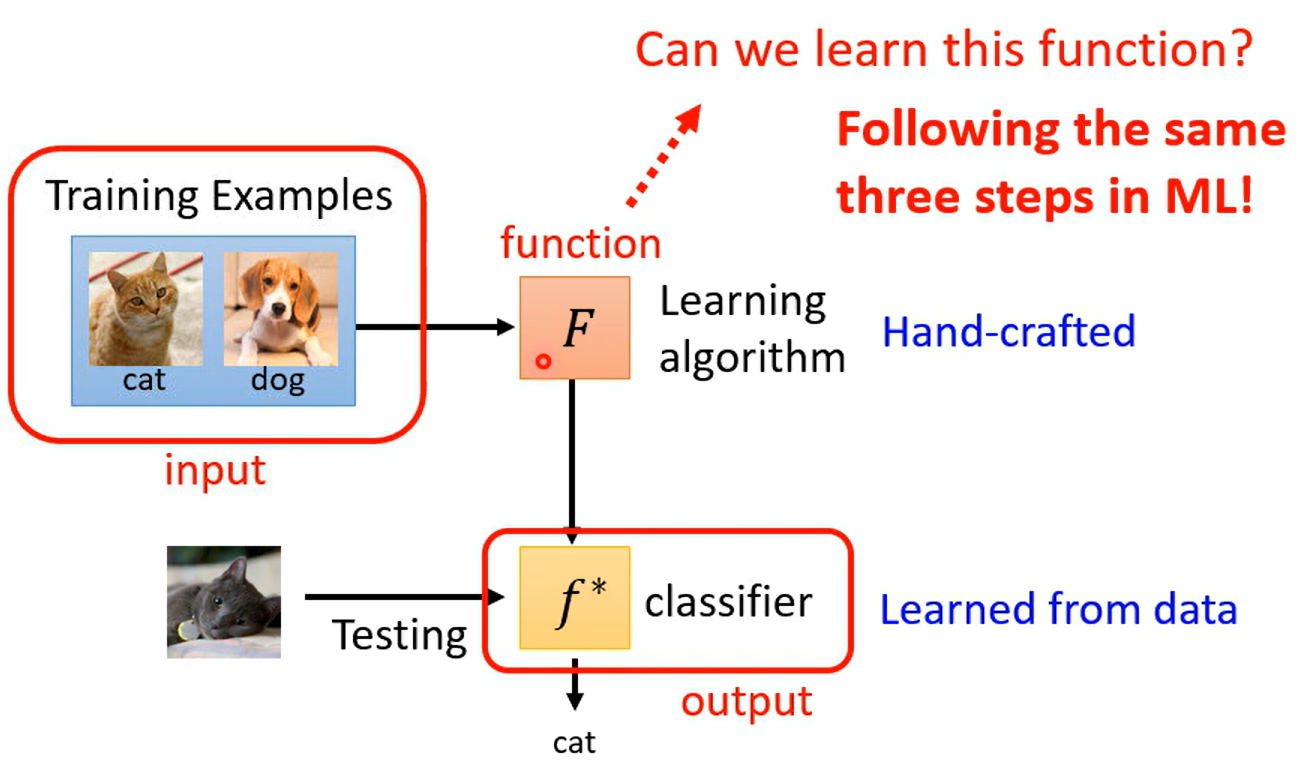
学习可以看成一个函数,学习如何学习其实就是通过学习得到一个函数(function),通过函数可以学习到另一个目标函数,目标函数产生期望的结果
也就是将学习的算法当成一个函数,学习这个函数
Step
-
明确学习函数 F 包含什么 初始化参数、网络结构、超参数等等
-
定义Loss function Loss函数要对学习函数 F 做出评判,好的函数损失小,反之成立
通过训练集(support set) 与测试集(query set) 学习loss函数,在测试集表现差的 F 认为Loss应该大
一般元学习要涵盖多个学习任务,F 得到每个任务的 f ,最终的损失函数Loss可以取多个任务下的测试集损失函数 的和
-
优化损失函数 如果参数可以数值化(连续),则使用梯度下降训练学习函数 F ,包含网络架构等无法数值化的参数,则可以用RL直接训练
Diff
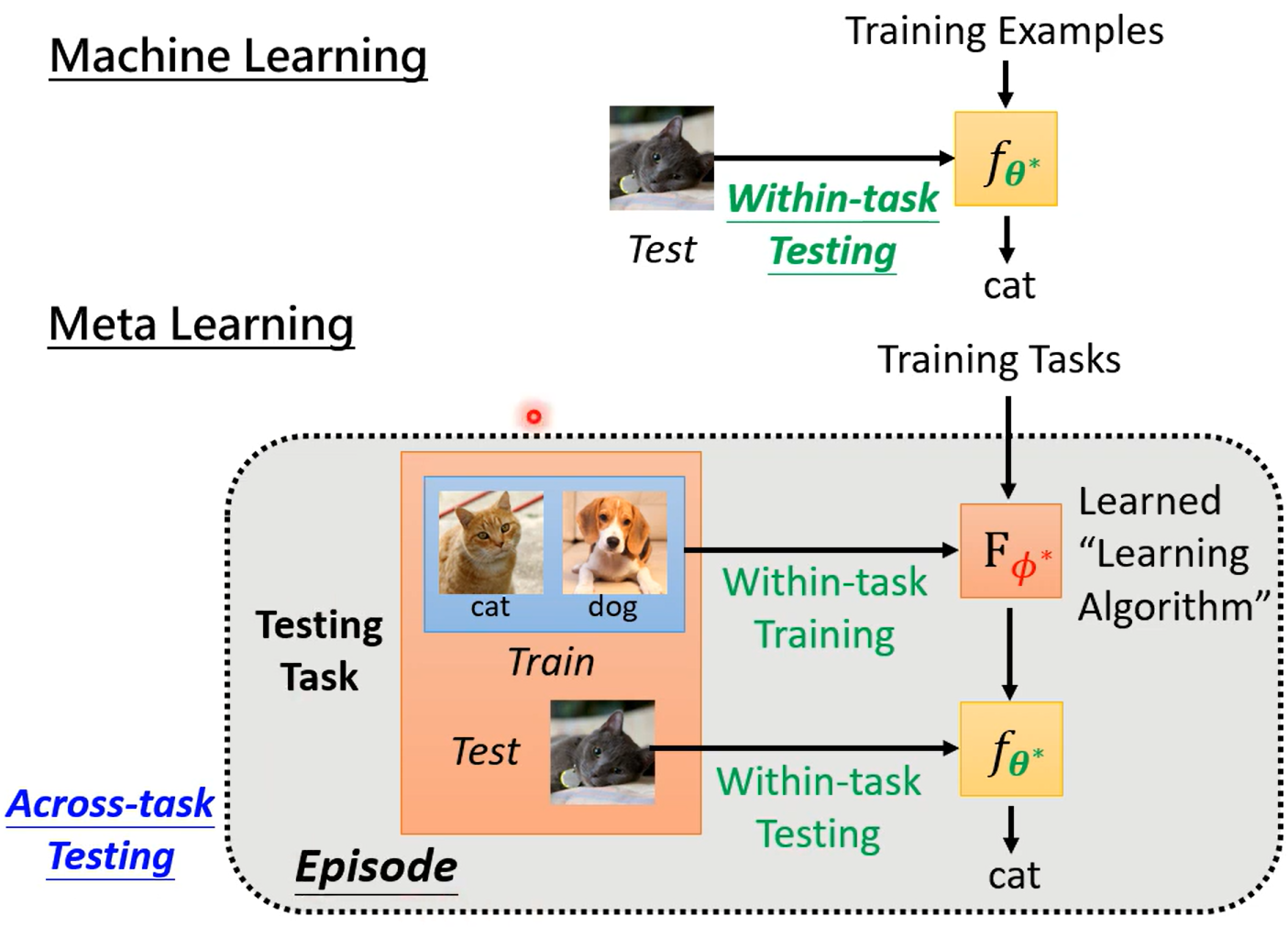
ML 称为 Within-task Training/Testing
Meta 称为Across-task Training/Testing
Learning Algorithm
-
Init
- Model-Agnostic Meta-Learning(MAML)
- Reptile
-
Optimizer
-
Network Architecture Search(NAS)
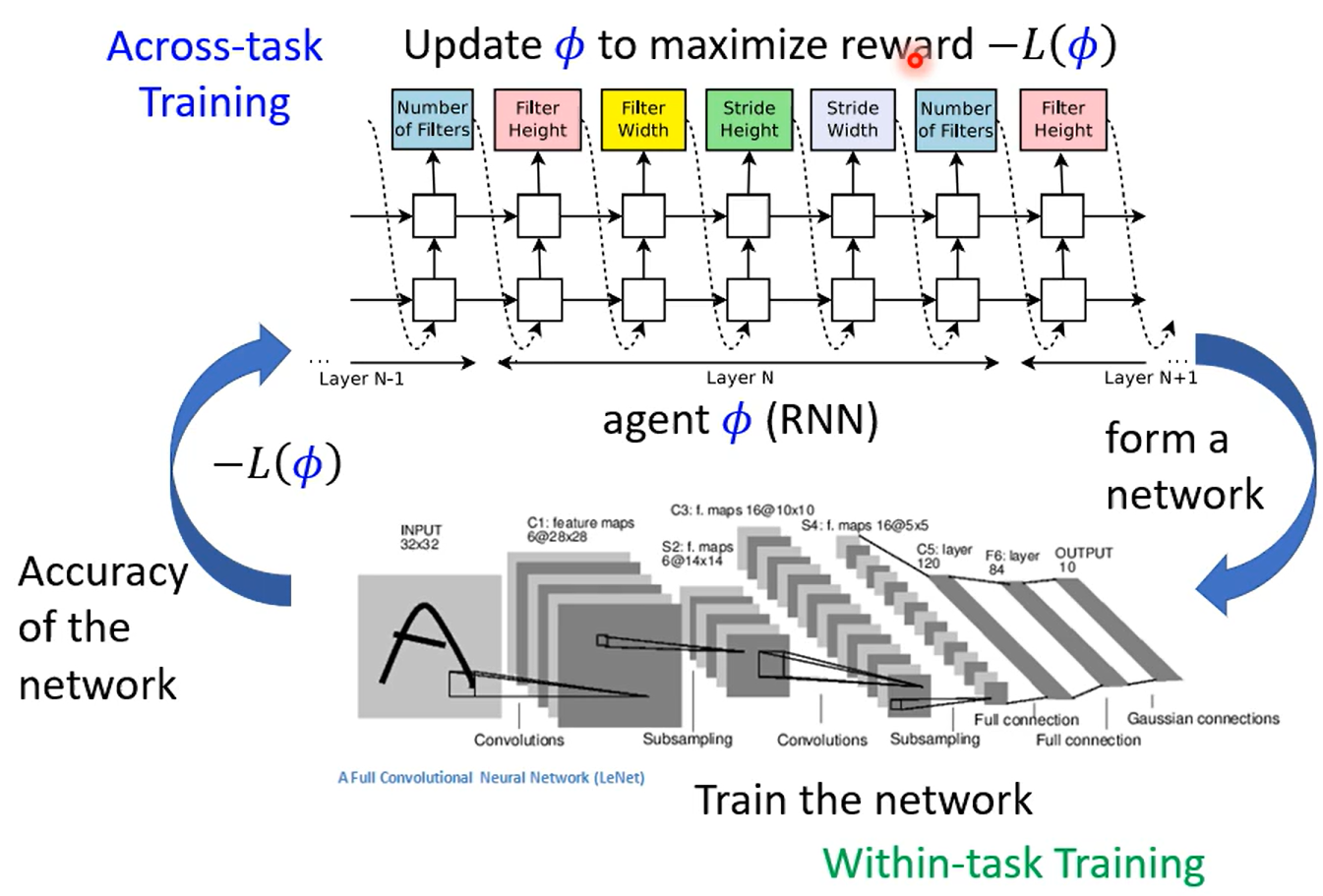
- RL算法
- DARTS算法(可微)
-
Data Processing
-
Sample Reweight 学习迁移学习如何修改参数
-
Beyond Gradient Descent 让机器学习一个算法,算法直接得到结果,不用学习过程
或者直接将训练与测试封装在学习函数中,直接输出最终结果而不是学习到参数后用参数做测试——度量学习
Few-shot
N-ways K-shot classification:N classes,each has K examples
- Training set 从训练的数据里选择N-ways,K-shots 作为一个训练任务
- Testing set 从测试数据里选择N-ways,K-shots 作为一个测试任务
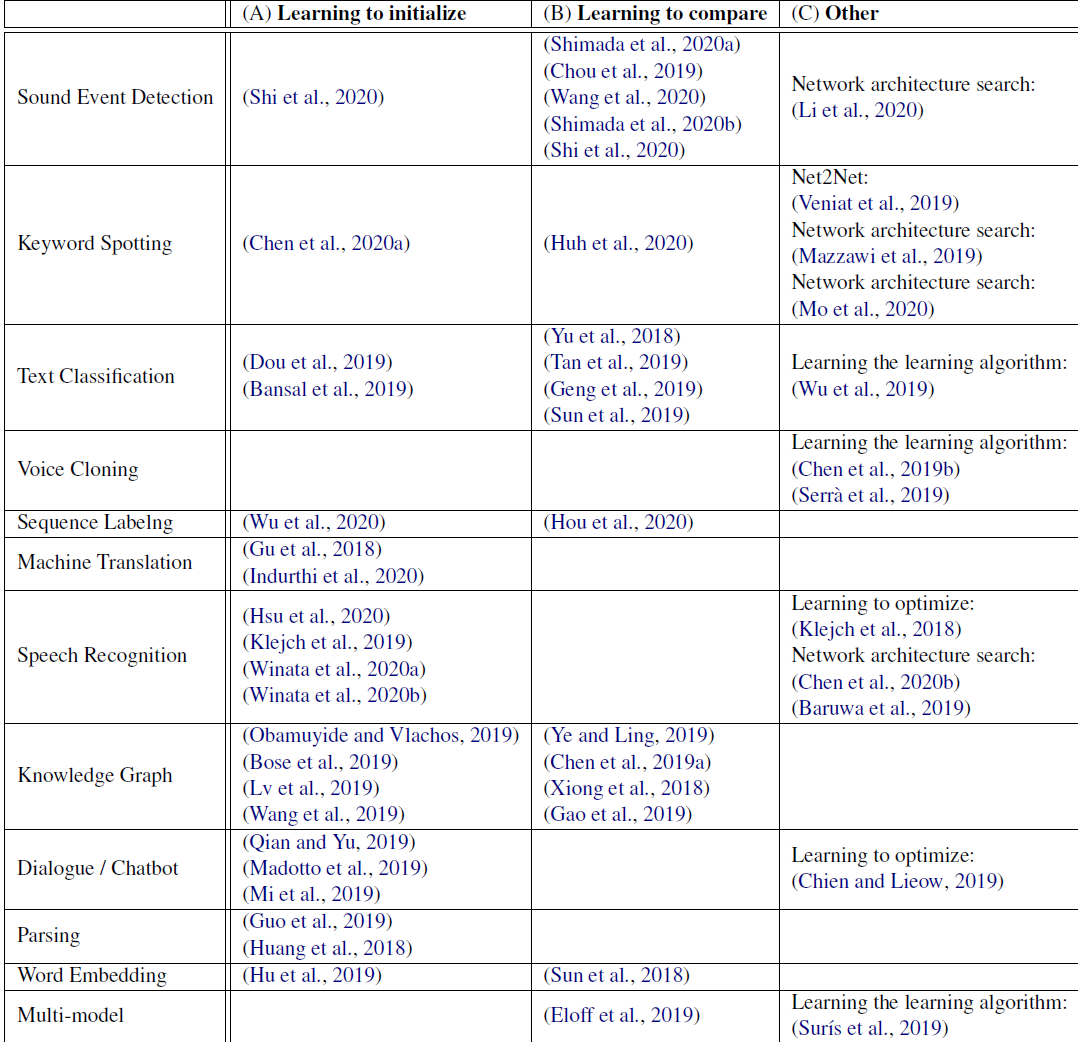
Few-shot Learning的应用
Other
vs Sefl-supervised Learning
其中MAML的目标与自监督学习相同,要寻找一个适合模型的初始化参数
不同的是,MAML找的初始化参数是适合下游任务的初始化参数,BERT一类的初始化参数不一定适用于下游任务;同时MAML是采用梯度下降来找到合适的参数,其本身需要一个初始化参数,这个参数一般采用BERT给出
结合二者在数据量少的时候会有显著的提升
vs Knowledge Distillation
并不是Teacher model精度高就可以教出精度高的Student model,一般甚至是精度低的模型教出来的学生精度高
使用MAML可以让Teacher model 学习如何教学
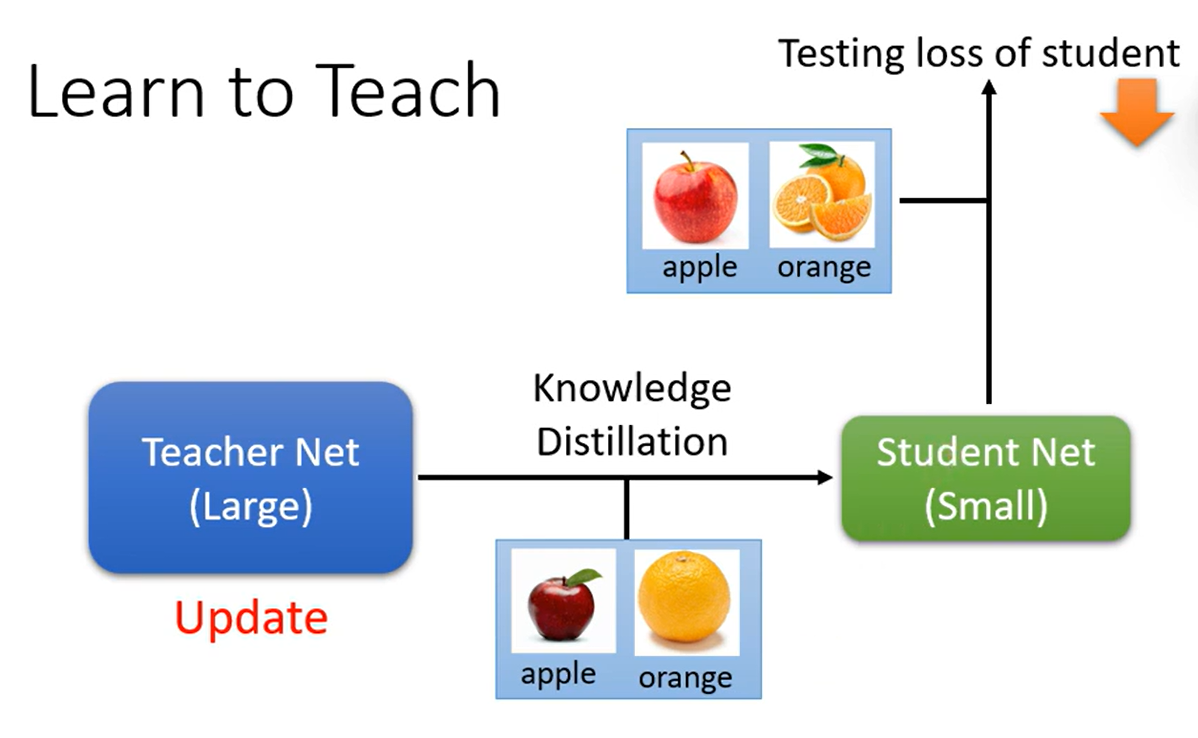
学生测试后更新教师模型,一般更新温度(temperature) ,而不是更新整个模型
vs Domain Adaptation
有标签的少量数据适用于Meta Learning,可以用 Few-shot Learning解
Domain Generalization
Domain Generalization
在训练资料中收集多种分布的数据,希望模型学会弭平分布之间的不同 详见
训练集分布只有一种,希望在测试集的多种分布上也表现出很好的效果 详见
Link to original
与Meta Learning结合就是学习一个算法,算法产生一个模型,模型应用于新的Domain做预测
但是与一般的meta learning不同,因为目标的domain是未知的,无法以这个domain为目标任务进行训练
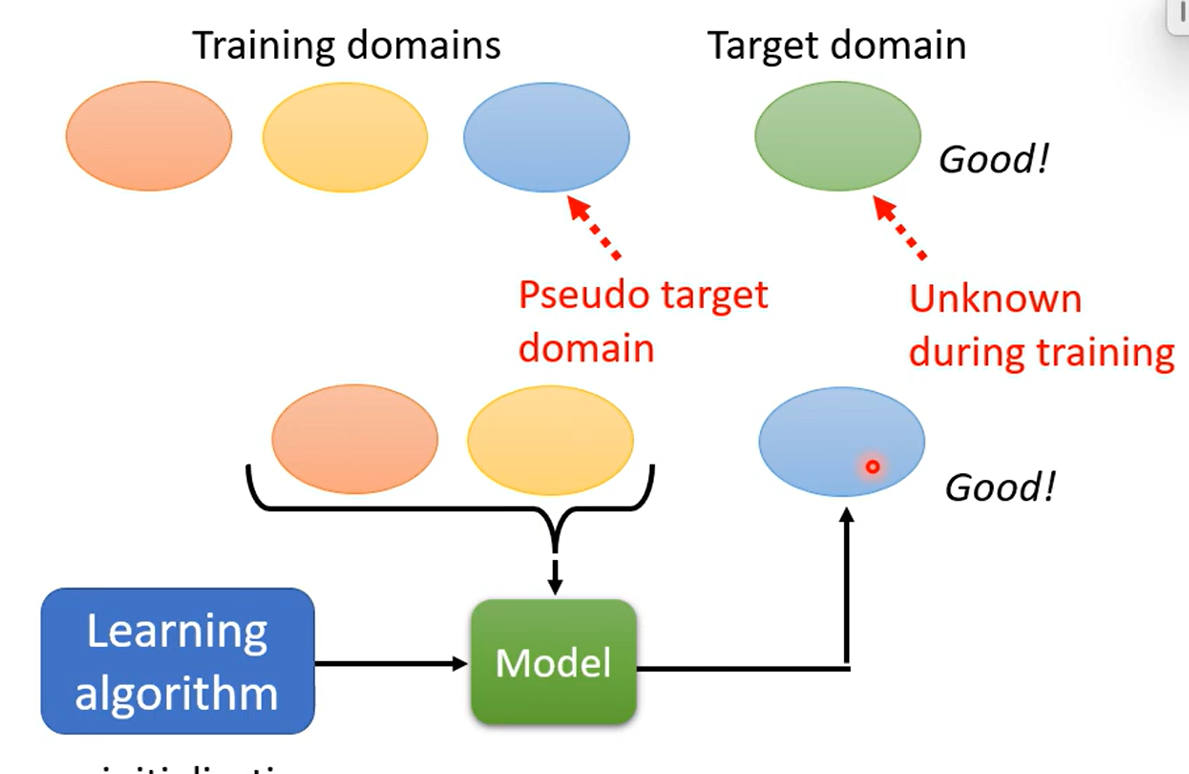
可以使用已知多个domain中的任一作为目标domain,让算法学习产生适合这些domain的模型,最终再应用在未知的domain上
Meta Learning本身也很有可能遇到Domain Adaptation的问题
vs Lifelong Learning
应用于Regularization-based
使用meta learning的方式,学习一个算法,算法找到更新参数的方式,使得新旧任务上的表现都好
Meta Learning 本身也会遇到灾难性遗忘(Catastophic Forgetting)的问题