Domain Adaption
领域自适应
Domain Shift
分布不同 训练集和测试集有不同的分布,例如训练集是黑白的,测试集是彩色的,在训练集表现很好的模型在测试集上就会表现很差
概率不同 训练集与测试集中,类别出现的概率大不相同
标签不同 图片相同,对应的标签不同
Domain Adaptation
少量Target Data
在对Target Domain有一定了解的情况下,有小部分的图片和标签
用在训练数据(Source Domain)上训练出来的模型在这小部分数据上做微调,跑小几个epoch,模型就会对target domain有一定适应
由于数据量很少,过拟合现象容易发生
大量Target Data
在target domain上有大量的资料,但是这部分没有标注
没有标注的资料无法直接用于训练,但是这类情形是较为现实的情形
在这样的情形下,提出一个想法:
利用一个特征提取器(Feature Extractor),提取出两类图片的基础特征,要求过滤到(不考虑)不相同的部分,再用这些提取到的特征进行分类的训练
在实际操作中,就是在特征提取器的输出中,两类图片的特征向量分布要相同
实现的技术称为Domain Adversarial Training
Domain Adversarial Training
输入两类图片,经过特征提取器分为两路,一路将特征送给Label Predictor做预测,一路给Domain Classifier做二元分类
将Predictor的损失定为L,Classifier的损失定位Ld,要求特征提取器提取出不区分分布的特征,所以将Feature Extractor的损失函数定为支持L(正),对抗Ld(负)的函数,做梯度下降
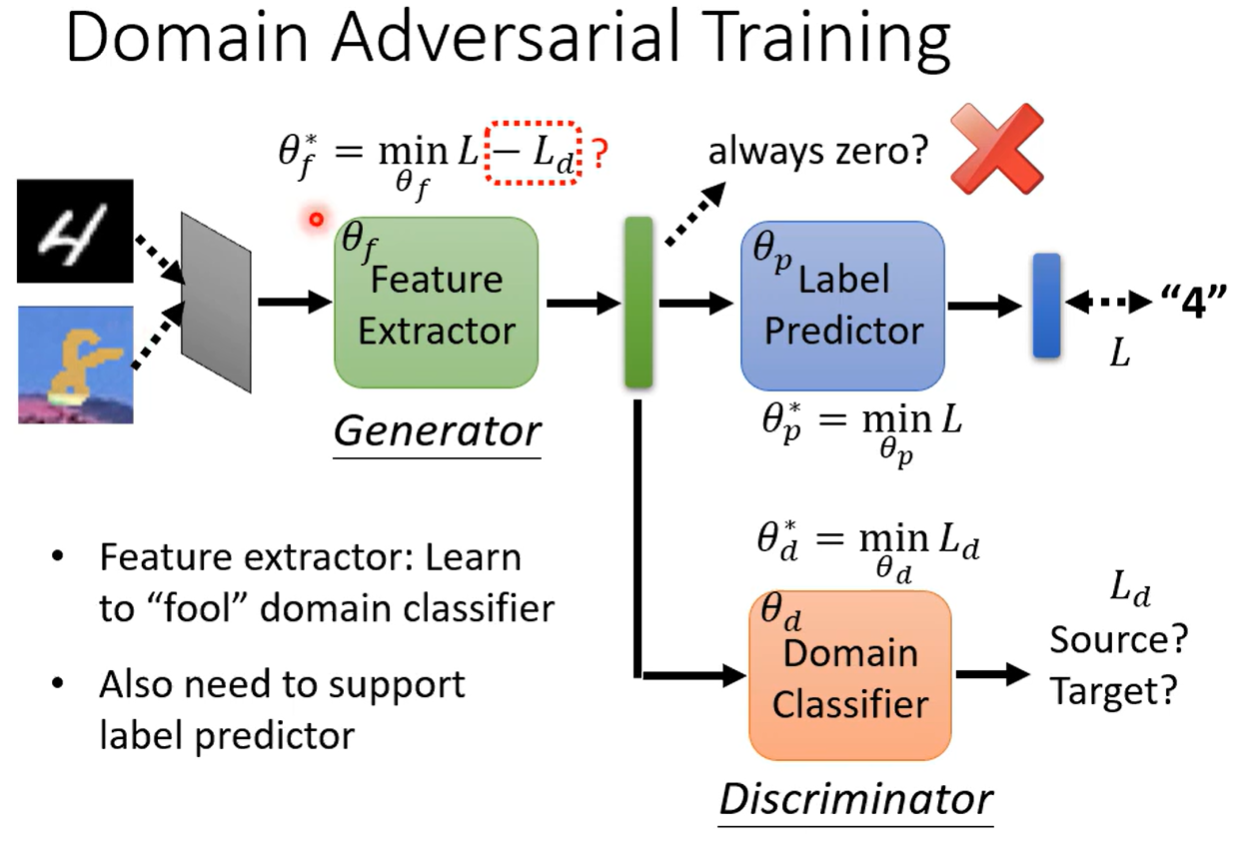
上图做法存在问题,Exractor的损失函数定义可能造成,通过颠倒两种分布的分类结果来让Ld变大的结果,这与我们希望的”两种分布看不出不同“不一致,有改进空间
与GAN类似,可以将Extractor看为生成器,Classifier堪为判别器,两者对抗,故称为对抗性训练(Adversarial Training)
Limitation 对抗性训练的做法存在一部分限制,下图中两种分布,圆圈和三角代表Source分布的两个类别,其中虚线是两者的分界;正方形是Target分布
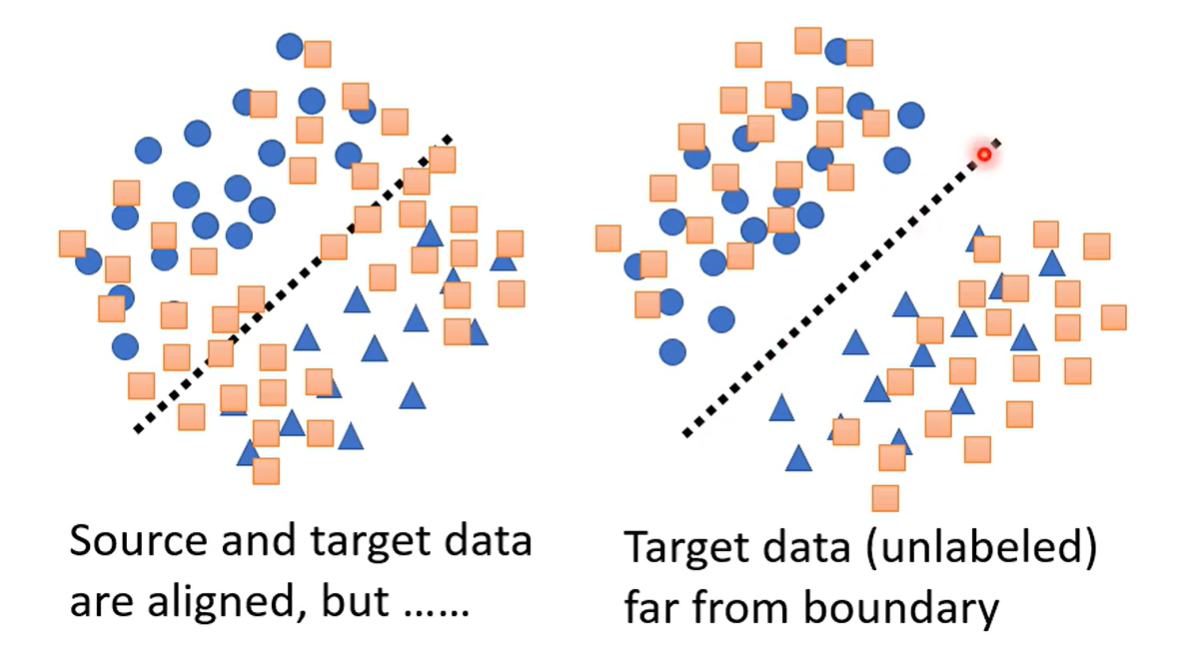
如果是左边的分布,分界的信息没有体现出来,不利于对Target Data的分类,无论结果是什么,分界线的位置上总归不存在某种类别,所以可以让分布远离分界线,提高分类精度
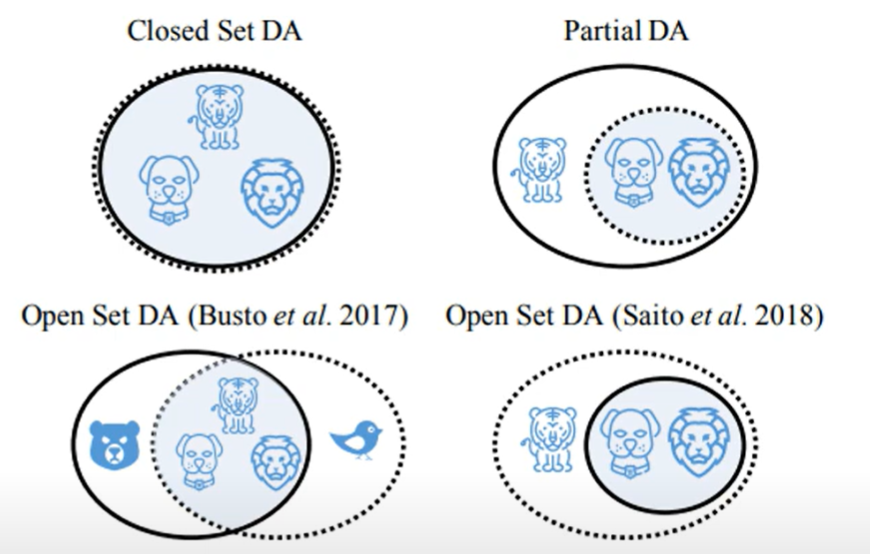
Outlook 其实分布类别也不一定相同,可能有多种情况,例如交叉重叠,分类标签不一致等等
极少Target Data
仅有一张,或极少,且没有标签
TTT Test Time Training 详见
没有Target Data
Domain Generalization
在训练资料中收集多种分布的数据,希望模型学会弭平分布之间的不同 详见
训练集分布只有一种,希望在测试集的多种分布上也表现出很好的效果 详见
How versatile Self-supervised are
自监督模型的多功能适应性
Cross-lingual
跨语言能力
指如果模型预训练的时候有多语言的数据,其在测试时尽管没有对应语言的Fine-tune,也会有不错的结果
How
模型是否能够跨越语言,将相同语义的文字识别并认为是相似的向量?
通过实验计算,将不同上下文情况下的一个词的向量取均值作为其代表向量,与对应的其他语言同义词进行比较,计算余弦相似度
再通过计算Mean Reciprocal Rank(MRR)(平均倒数排名) 分析二者的相关性
语言之间的相关性可以解释为:语言之间的向量关系
Cross-discipline
跨学科能力
在文本上进行训练,之后在目标领域中利用文本进行映射,实现用模型的文本能力实现跨学科的预测
说明模型学习到了某些更通用的特征,使其拥有对其他任务的预测能力
那这种能力是优化(optimization)的能力还是生成(Generaliation)能力呢?
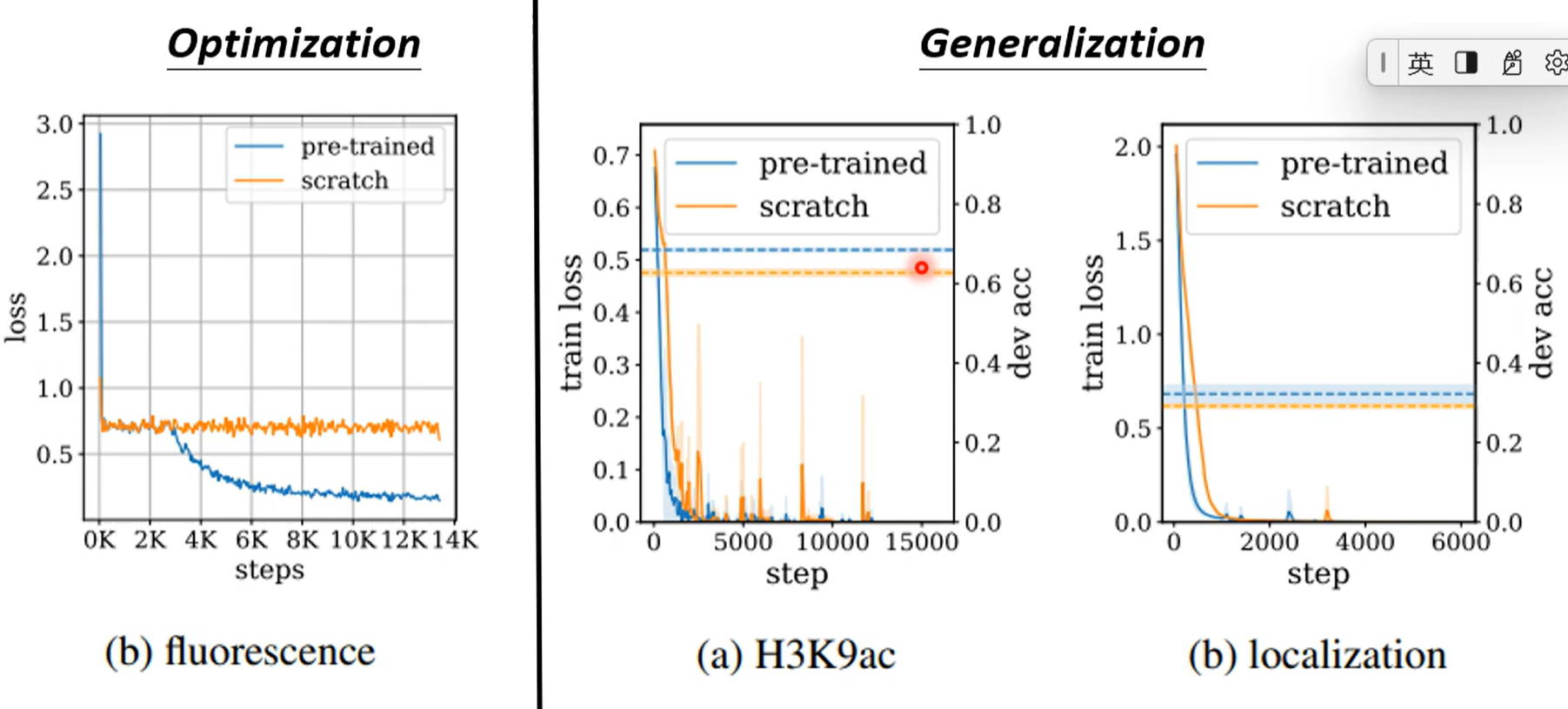
实际上分析loss,可以发现在优化任务中有预训练的loss降得快且多;在生成上loss都能降到接近0,看dev acc(develop set上的准确率,举一反三的能力)有预训练的效果好于没有的
事实证明都有提升
end to end 语音Q&A模型
在没有这些发现的前提下,实际上做不出端对端的语音Q&A模型,即输入一段语音问题,划分语音中答案的位置,以往都是需要做语音辨识再做回答
在认识到预训练的NLP模型可以做到跨领域任务后,语音信息就可以直接接入一个语音上的预训练模型提取特征,再随意将特征与文本做映射,输入到文本预训练模型进行预测
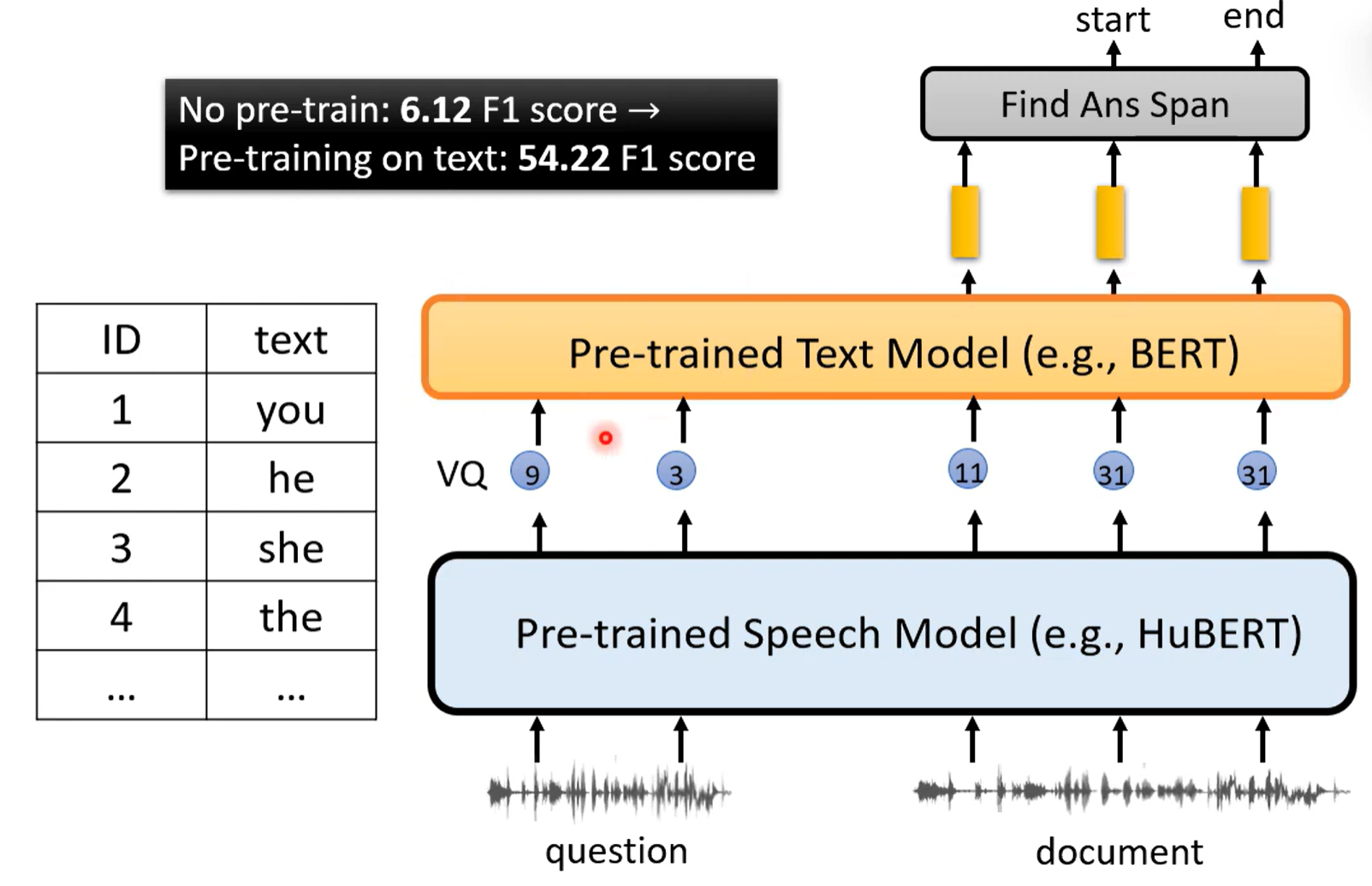
这样确实可以实现端对端的语音Q&A
Pre-training with Artificial Data
如果人工数据有用,那么模型就可以随人造资料学习不同的特征
但是并非所有的人造数据都有作用,只有一些有一定限制的数据有一定作用
- 成对数据 数据中有成对的token,即重复出现
- Shuffle 打乱顺序的token
发现:接近人类语言的数据模式(例如成对)可能有利于模型的学习;打乱顺序的数据强迫模型学习长序列,可能也有利于模型学习
相关概念
Mean Reciprocal Rank(MRR)
搜索算法的评价指标,搜索结果中正确结果排行位置记为rank,取rank的倒数,加和作为搜索的分数,越高说明搜索的正确性越大