TODO
- v1
- v2
- v3
- v3+
Deeplabv1
Key Issue
文中提到并总结了DCNN在密集预测任务上的缺陷:
- DCNN中依赖下采样来保证大感受野,但是导致的分辨率下降,失去了细节信息,上采样时再恢复,无可避免的丢失部分信息
- 空间不变性(平移不变性)DCNN为分类开发,其要求物体的位置不影响其类别,这种性质意味DCNN物体定位上存在先天不足
Motivation
- 下采样问题:既然下采样会丢失信息,那就想一个办法既能保证大感受野,又能保留分辨率
- 空间定位问题:空间定位上DCNN存在先天不足,不如引入一个新的概率图模型,一种额外的定位方法,再结合多尺度的特征,保留更多细节
Method
dilated convolution
这个图似乎画得一般
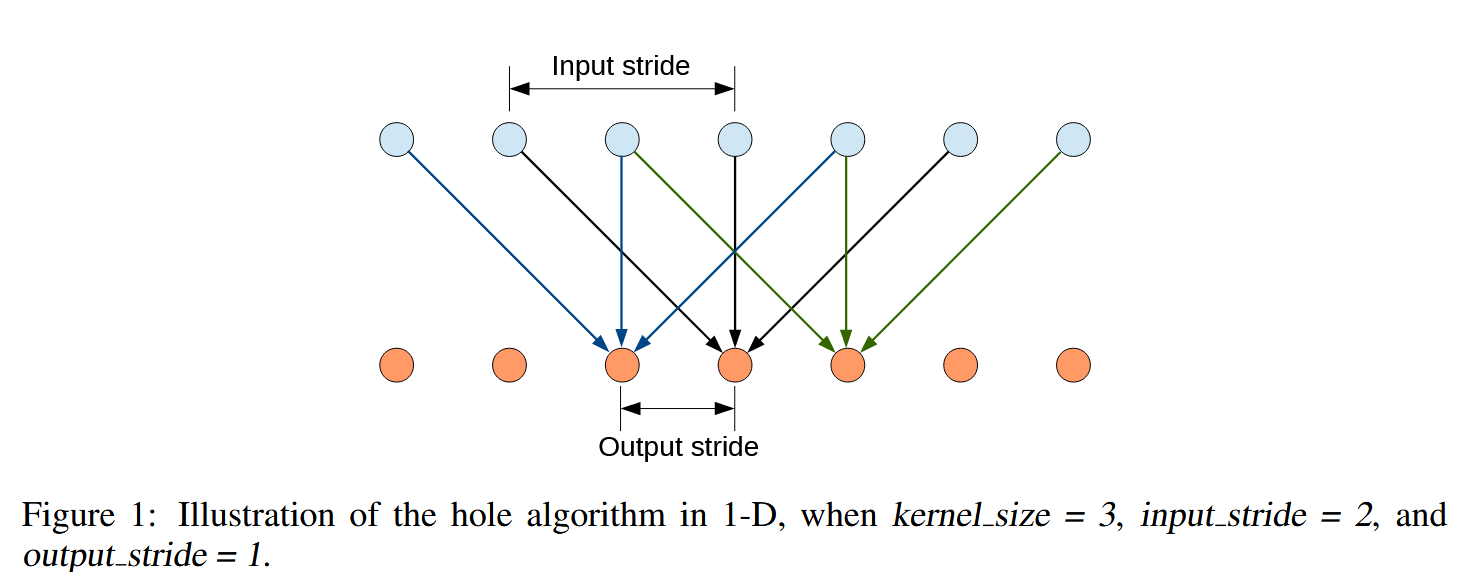
上面是输入,下面是输出,可以看到每个输出其实间隔得来自上面得输入,这就是空洞卷积的含义
原始论文中:
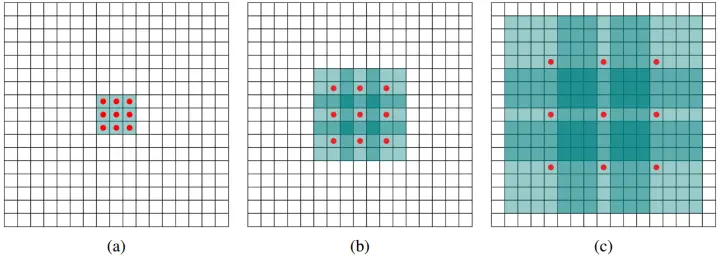
空洞卷积的理解可以变相扩大卷积核的感受野:
- a图含义是只有3卷积,空洞率为1
- b图空洞率为2,理解上就是对于一个7patch,只有9个红色的点有效,其余都是0权重
- c图同理,空洞率为4,跟在空洞率为1、2的两个卷积之后,那这九个点其实来自15的感受野
这样就实现了扩大感受野,但是分辨率不降低,在文中的实现其实有些设计,并没有用空洞卷积完全代替下采样,依旧保留了部分像素变小的操作,目的应是保留这些分类DCNN对高层次语义的提取能力,需要一定的下采样
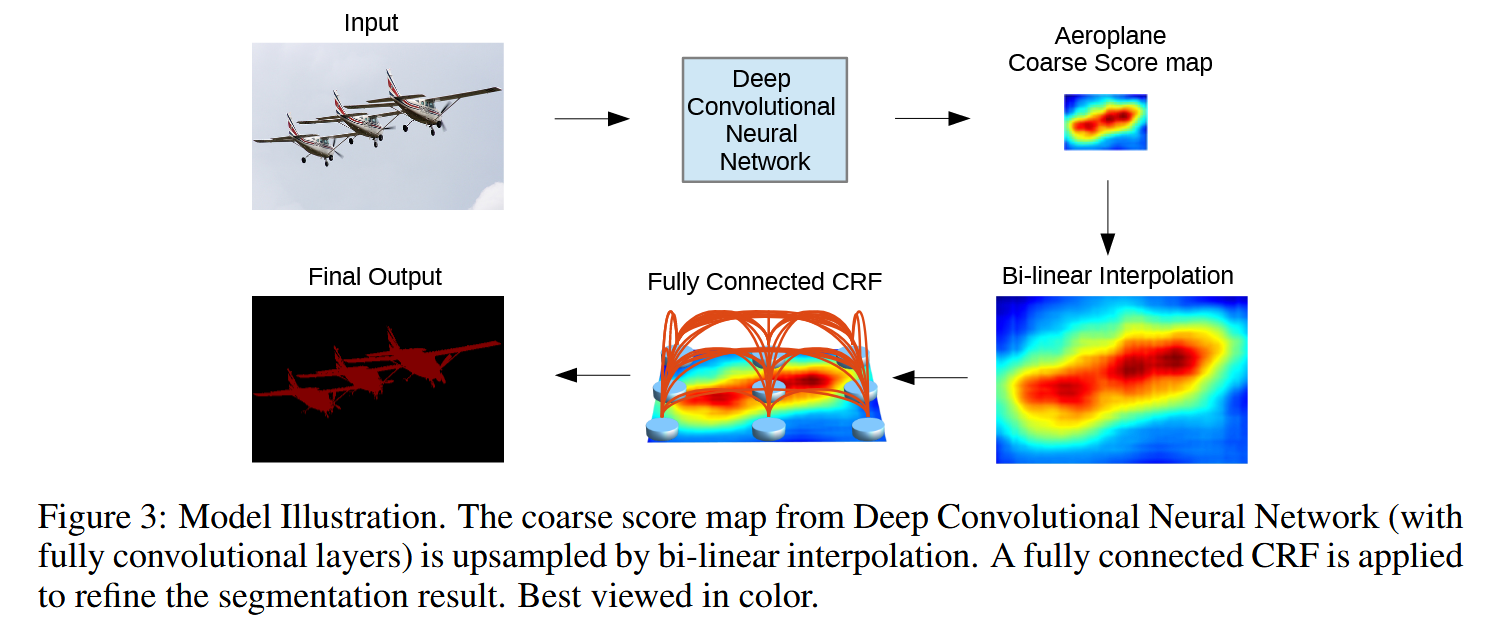
得益于模型输出的score map足够平滑,后续采用双线性插值,而不需要反卷积,减少复杂度,加快计算
Conditional Random Field, CRF
几乎独立的模块,将概率图的概念引入到卷积方法,构建函数:
其中,
其中:
- x指的是像素分配的类别
- 代表DCNN输出像素属于x的概率,第一项称为一元势,含义是如果概率大,那损失就小,否则损失大,要求x选择DCNN概率大的类别
- 只有当 时才是 1,也就是像素预测结果不同,施加约束,其中k如下:
其中:
- p代表像素,I代表得分图中强度
- 就是说如果像素靠的近,强度差得少,那第一项就大,此时如果像素预测不同,说明有问题,损失增大
- 第二项就是单纯考虑像素之间的距离
所有像素都两两参与计算,称为全连接,这个CRF训练独立于DCNN的训练,先训练DCNN再对CRF的参数进行搜索,得到最好的参数
Multi-Scale
将四个池化层和一开始的输入相结合(用卷积MLP控制维度),增加最后结果的通道数,再softmax输出,得到得分
实际就是通过多尺度的输入来提供更多细节,加到通道之中
Reslut
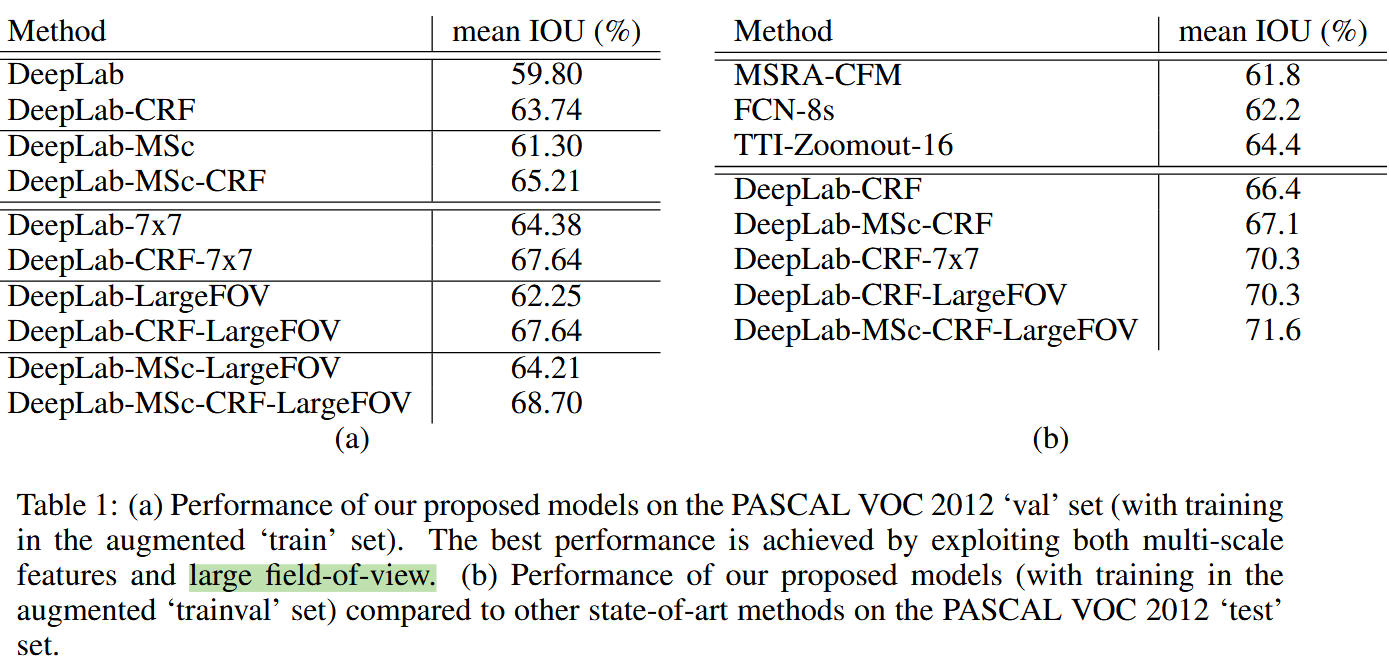
最后实验验证,CRF效果很好,多尺度也还行,空洞卷积实现的广视野可以有效降低参数量,同时提高精度

Conclusion
文章创新点在于将空洞卷积应用于密集预测任务,用来解决下采样带来的分辨率问题,又保留大感受野,全连接CRF也的提出极大提高精度,在设计上很巧妙
但是文章其实没有对模型做很多改进,基本的策略均在之前有见识过,CRF并不是一个对模型的改进模块,也没有对损失有什么影响,而像是一个额外的创意
DeepLab v2
Optimized atrous convolution
提到空洞卷积的两种实现方法:
- 直接用0填充扩充卷积核
- 先模拟空洞卷积,子采样成个子图,然后用标准卷积
之前使用的第一种方法计算量大,本次提到用第二种方法,先采样,卷积再拼接成目标尺寸,这样一来可以使用集成的高效卷积实现来提高计算效率
Atrous Spatial Pyramid Pooling(ASPP)
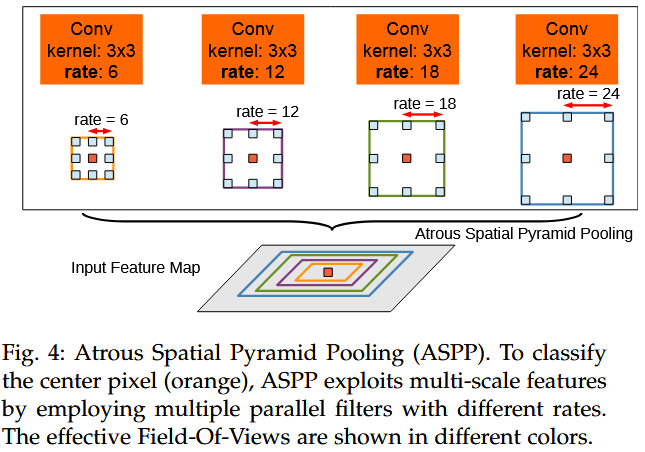
参考R-CNN中提到,不同卷积可以对同一尺度图进行学习,并有效获取特征
使用并行的不同感受野的空洞卷积来获取不同尺度的信息,并通过两个1卷积降维,统一维度后融合
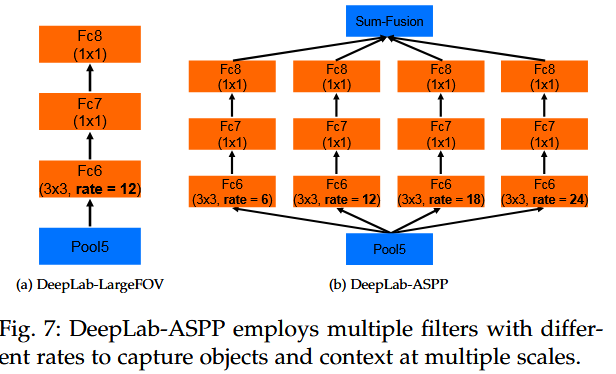
DeepLab v3
Multi-grid Method
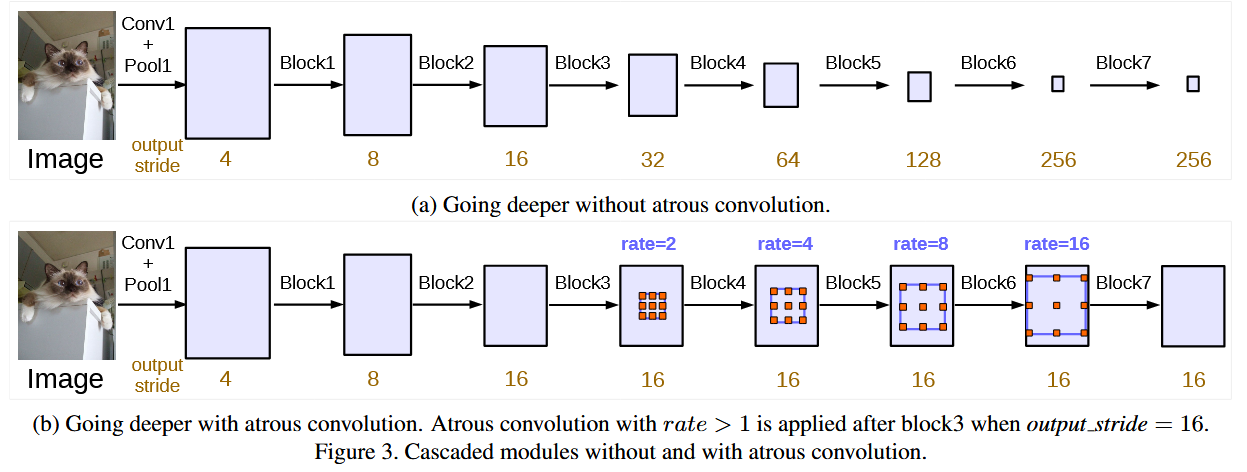
提到连续的striding对导致信息丢失,所以用空洞卷积,同时要扩大感受野,所以提出多网格方法
实际上是将ResNet中block4-block7中卷积换成空洞卷积,且按一个序列变化其空洞率,例如,形成一个卷积层序列逐步扩大感受野
Atrous Convolution Optimization
在这个版本中发现一些问题,空洞卷积如果空洞率太大,其中有权重的卷积部分可能会无法匹配到有效的像素,导致卷积退化,只有一部分卷积有效,这说明其在大范围信息处理上受限
解决方法是将ResNet输出的结果(图像级特征)平均池化后经过1卷积,再插值到目标维度,全局池化引入了全局的信息,解决大范围的特征学习问题,再经过设计好的ASPP
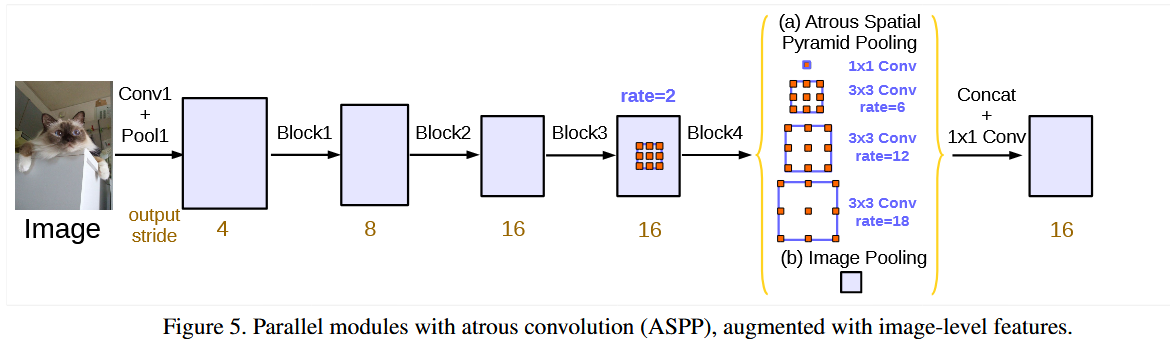
这个ASPP相比之前,其通道数固定为256,且使用了BN层,应该是在步长和padding上有设计,保证了最后输出的尺寸一致,用于拼接,最后在过一层1卷积得到最后的logits
DeepLab v3+
Encoder-Decoder
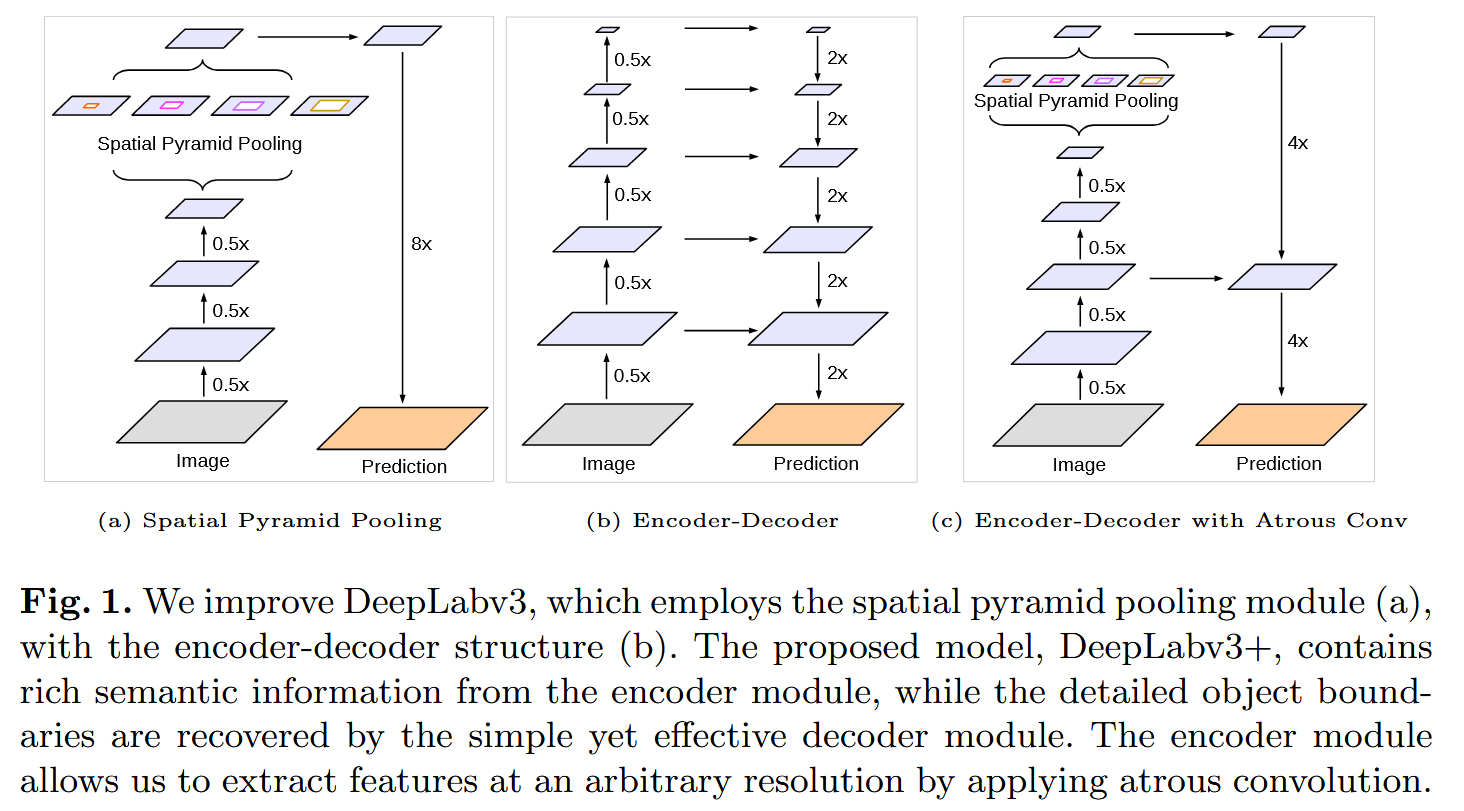
动机:目前用空洞卷积来代替下采样,但事实是受限于模型和GPU,空洞卷积不能一直使用,要保证分辨率而过多使用空洞卷积反而引入大量的计算,而encoder-decoder的设计可以即保证边界细节信息的保留,又保持计算量
所以设计了一个由DeepLab v3来做Encoder,增加一个简单的Decoder来完成部分上采样的方法,以此减少空洞卷积的使用,同时保证细节信息的学习
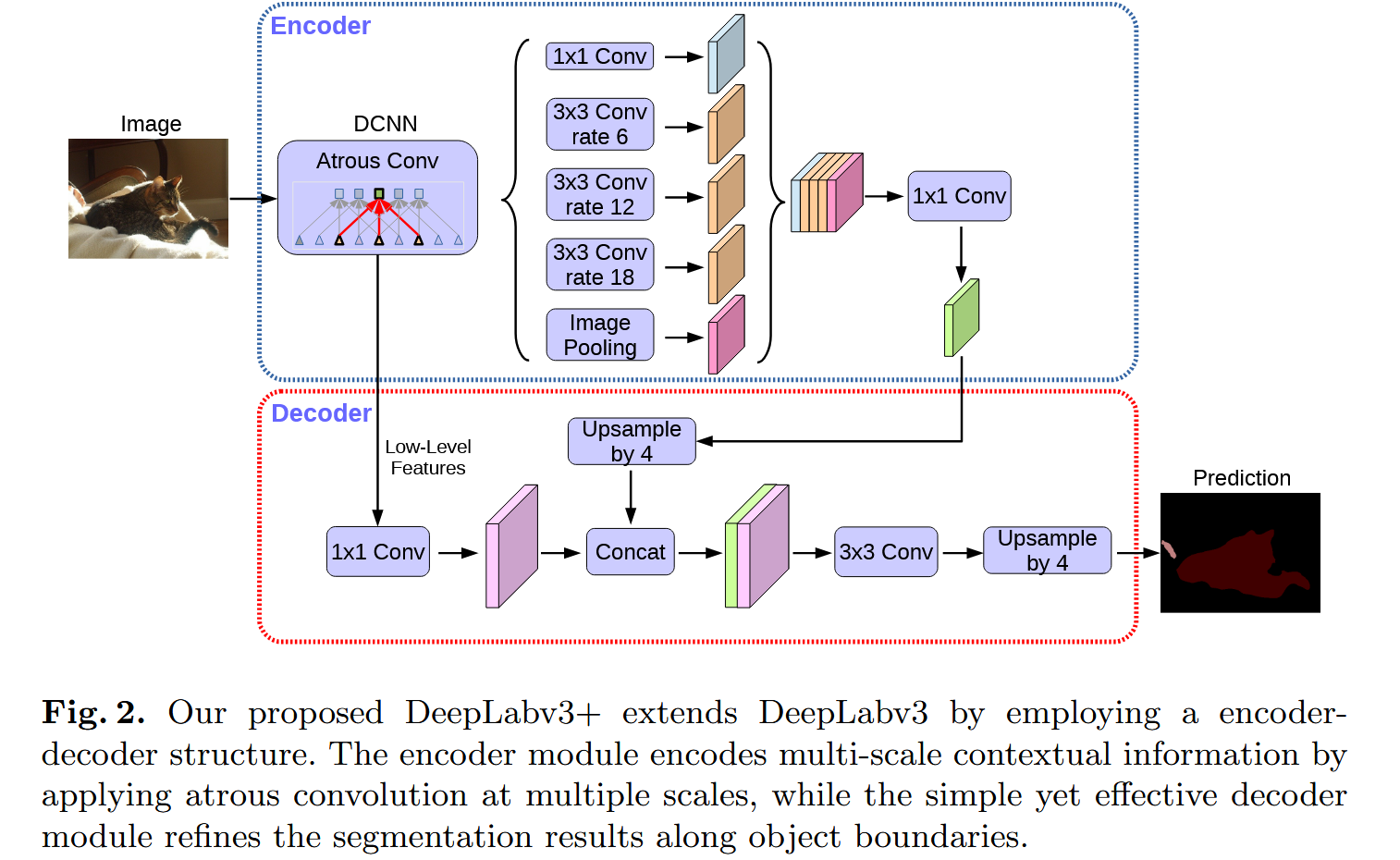
其具体实现为:
- DeepLab v3基本保持不变,其最终输出被上采样4倍输给Decoder
- DCNN的输出用1卷积减少维度(否则维度过大,模型训练受阻),用来与放大4倍的特征图拼接,再通过卷积后,上采样4倍
这样最后达到16倍(也有8倍,效果更好,但是计算量更大)
这样细节信息保留,且计算量得以保证
Atrous depthwise conv
深度可分离卷积,其含义如下:
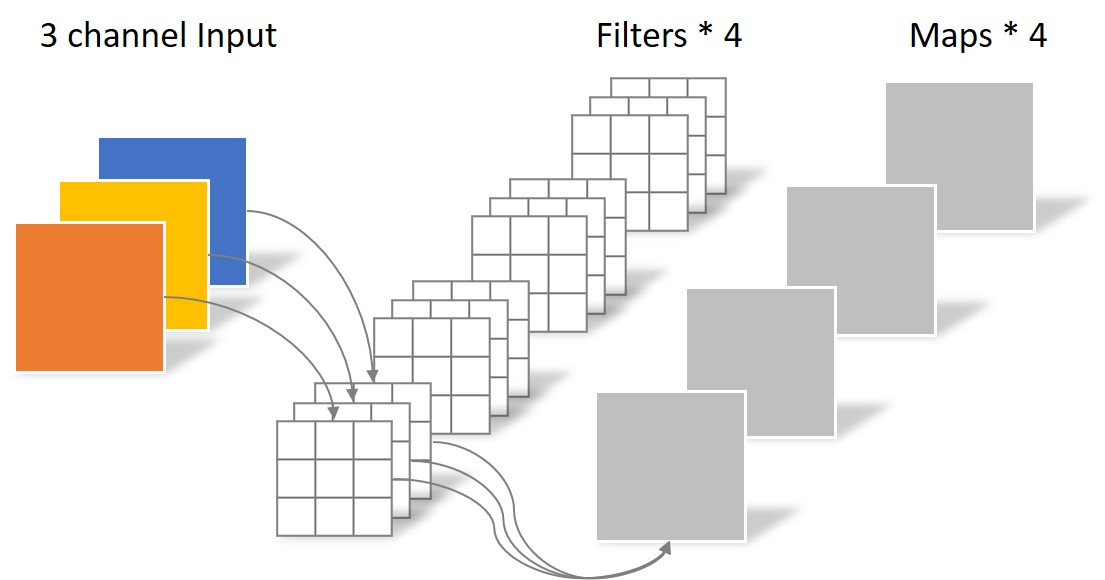
普通卷积,每个核对应输入通道数,核数对应输出通道数,将输入通道经过核后形成一张单通道图,多核组成多通道,参数量
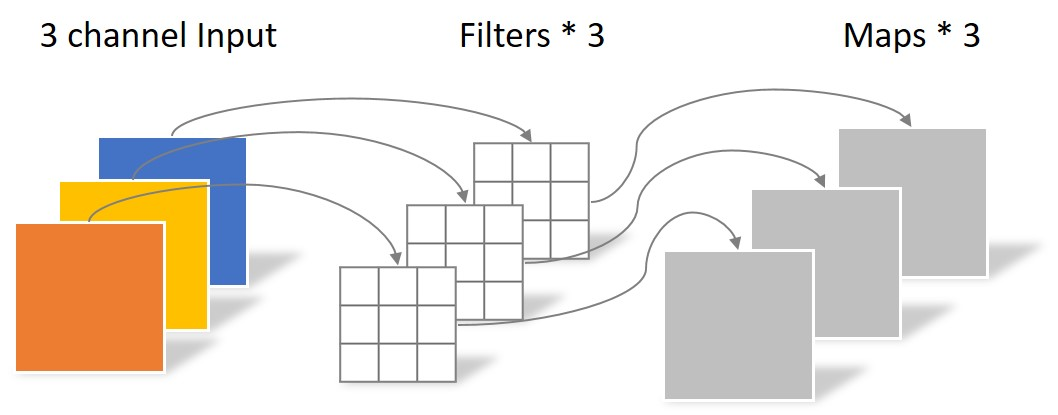
深度可分离卷积分为Depthwise卷积和Pointwise卷积
其中,Depthwise卷积核数与通道数相同,一对一进行单通道卷积,没有通道之间的信息,参数量为
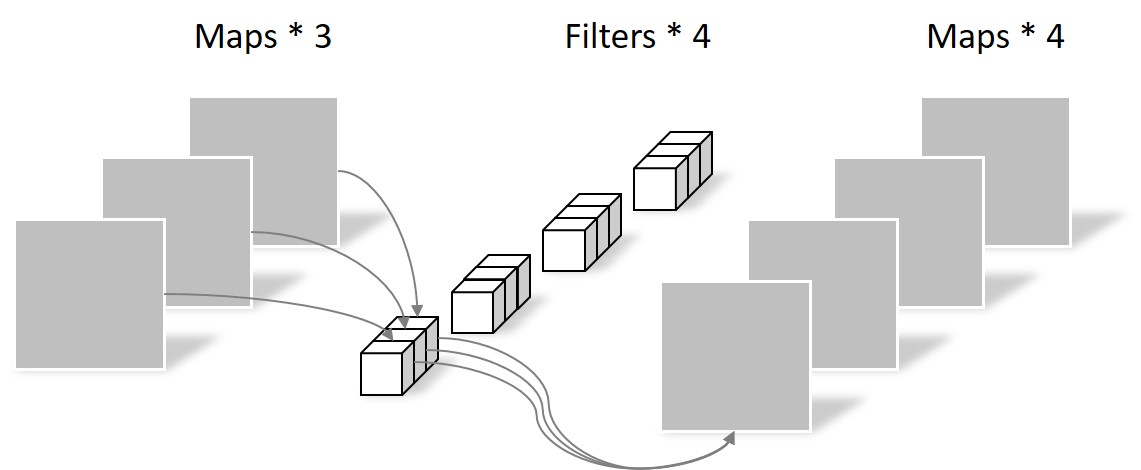
由于没有通道之间的信息,所有要再做一步Pointwise卷积,其卷积核为 ,对一个像素的所有通道做卷积,参数量为
总参数量为
在论文中使用空洞卷积来做Depthwise卷积,进一步优化了深度可分离卷积
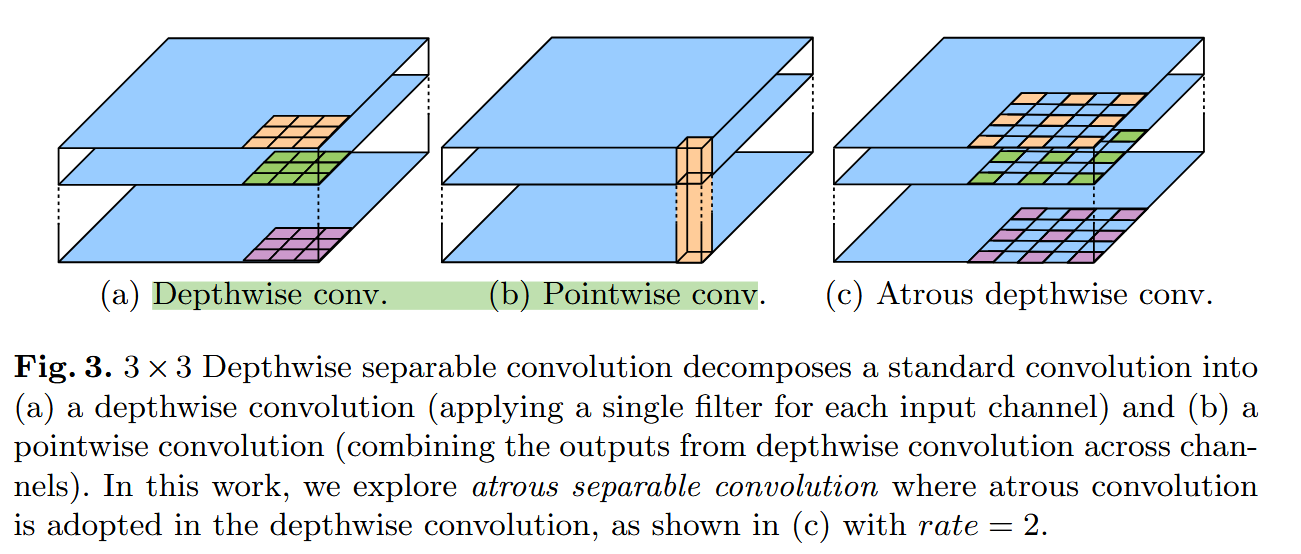
通过运用空洞卷积,分辨率,感受野可以有所调整,取决于设备性能
Conclusion
DeepLab系列的模型针对两个问题提出一系列的改进:
- 下采样导致的细节丢失
- DCNN的平移不变性导致的定位问题
v1:
- 提出空洞卷积
- 使用CRF
v2:
- 换用ResNet
- 空洞卷积优化,结合多尺度信息,提出ASPP
- 保留CRF
v3:
- 更改模型结构,使用Multi-grid Method扩大感受野,结合空洞卷积减少下采样
- 发现空洞卷积在空洞率过高时存在退化问题,只能学习局部范围的信息,所以多一步全局池化,来得到全局信息,再过ASPP(增加BN层)
v3+
- 深度可分离卷积
- Encoder-Decoder结构,新增一个解码器,结合DCNN的输出,保留细节信息
- 二者都用于解决单纯使用空洞卷积代替下采样计算量大的问题
这一系列都是逐步优化之前的结构,并逐步更新使用的DCNN模型,其设想都是可复用的模块,用很好的拓展性
Refer
【参考】
【代码】