与unsupervised learning
实际就属于无监督学习,只是其中的一个部分
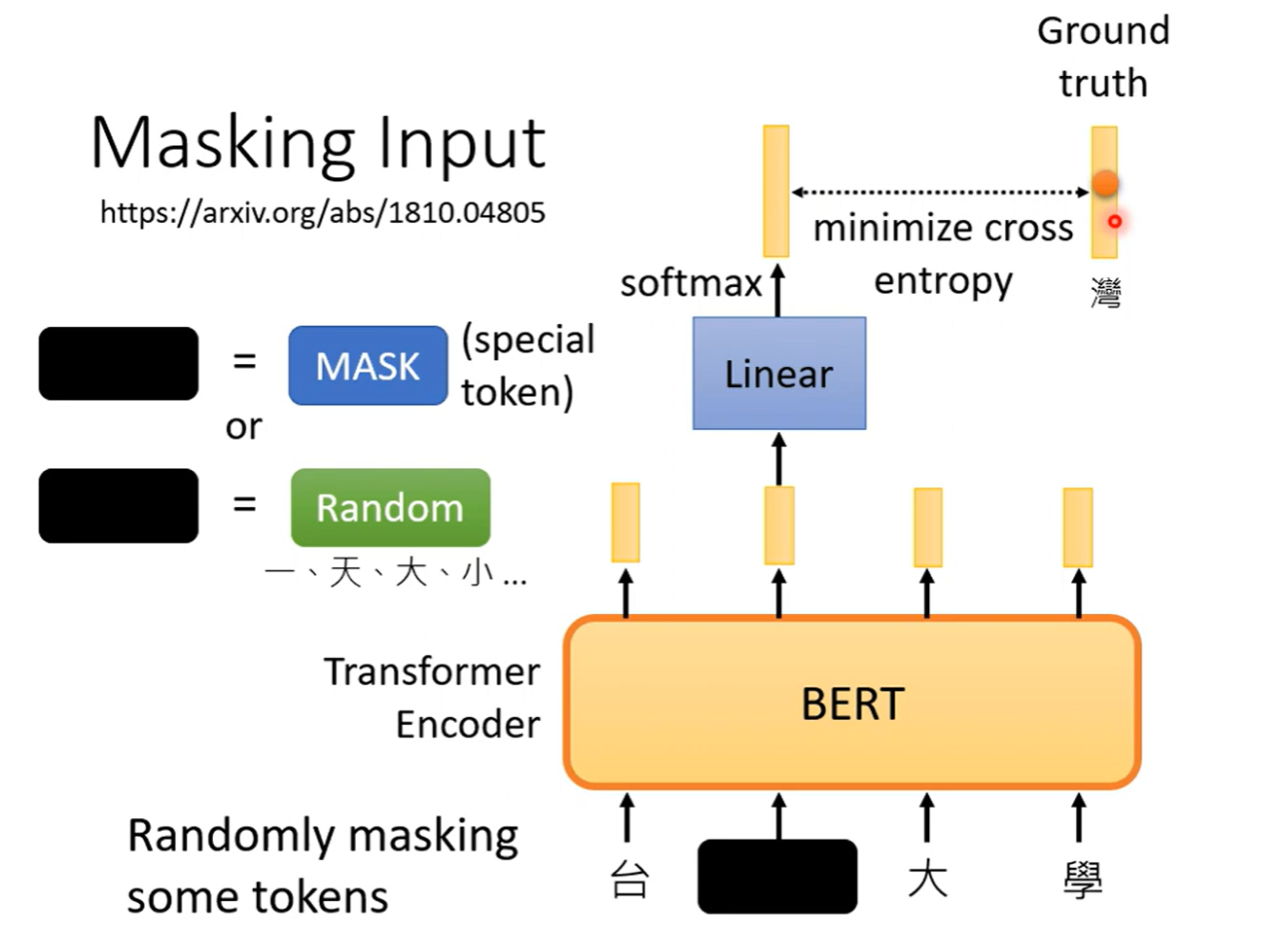
Bert
任务
文字预测训练
输入一段文字,其中某些token被掩盖(或直接盖住,或给出无用其他文字),要求输出理应对应的文字
下游任务 Downstream Tasks
真正的感兴趣的任务,相当于模型的应用任务
这种模式就是Pre-train,预训练产生模型,再针对下游任务进行微调
GLUE Genneral Language Understanding Evaluation
这类模型的评价指标(资料库),包含多个任务,利用模型实现这些任务评分取平均值,得到模型的表现得分
实际应用
需要给出一定的标注数据,实际就是半监督学习(semi supervised)
BERT+ Linear
-
情感分类 使用BERT预训练模型 组合 线性层 做序列的分类任务,其中线性层的参数是随机初始化的
-
词性分类 多个Linear
-
自然语言推论(inference) 给出两个句子,判断是否前提可以推出结论
-
Extraction-based Q A 给一篇文章,提出问题,其中问题的答案在文中一定有出现
模型输出两个正整数,即答案的始末位置
给出两段文字,同时给出CLS,SEP(问题和文章的分割符),利用两个随机初始化的矩阵与模型的输出做内积,得到答案的起始位置和结束位置
why does BERT work
实际上可能是在填空训练时学习到了从上下文学习语义的能力
也可能是因为预训练后参数适合训练
有趣的是 BERT可以实现多语言的任务,甚至不用微调就可以适应不用语言的任务
李宏毅团队发现,其实不同语言经过BERT产生的向量存在一定过的差距,将这个差距加到预测结果中,BERT就可以输出对应语言的结果(有一定偏差)
GPT
工作原理
得到一个输入,预测这个输入的输出,像Transformer的Decoder,每次预测是掩盖后续输入,让模型训练,预测下一个输出,也就是把一句话补完
实用
给模型任务的样例,例如 train =》 训练 然后给出 learning =》 让GPT给出结果
称为 “In-context” Learning
没有梯度变化,没有训练 可分为 “Few-shot” Learning(给出一些例子),“One-shot”(给出一个例子)”Zero-shot“(给出任务要求,没有例子)
其他应用
语音自监督模型的五种训练方法
Generation
-
Masking 盖住声音信号中的某些部分,要求模型学习预测这些部分
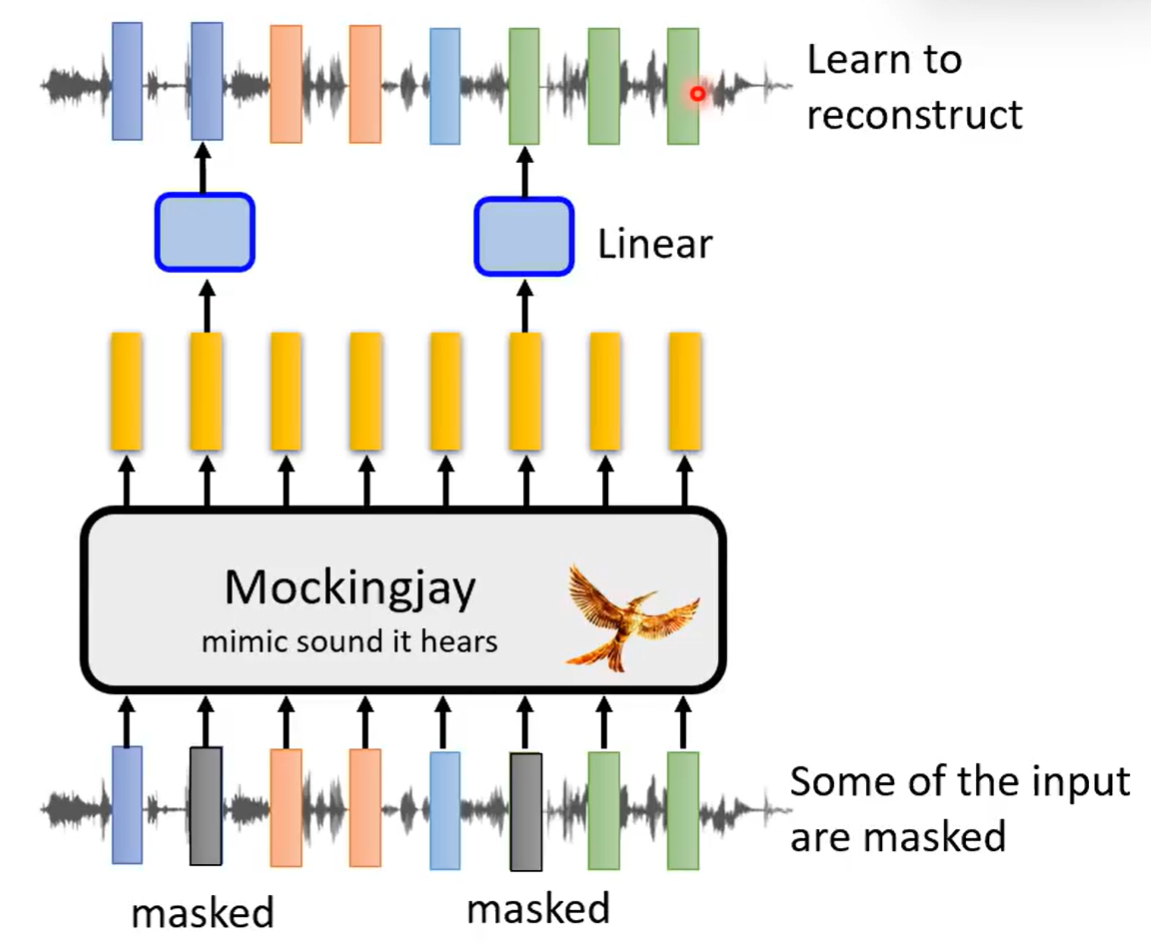
由于声音信号相比文本有更大的相似性,应该盖住更大的一片区域,问题才足够难,模型才能学到真正的特征
-
Predicting GPTs式预测,同样需要将问题变难,当预测第n>3之后的的向量时,模型才真正在学习
这些同样可以应用在影像上,但是声音和影像的信息太过复杂,生成式要求生成一样的内容很难
Predictive
简单任务代替复杂任务
- 图片旋转 让模型判断图片是否旋转,旋转了多少度
- 内容预测 将图片(声音)局部分割,让模型判断局部的相对位置信息
- 简化任务 将复杂的信息向量做聚类(Clustering),再让模型做预测
Contrastive Learning
对比学习
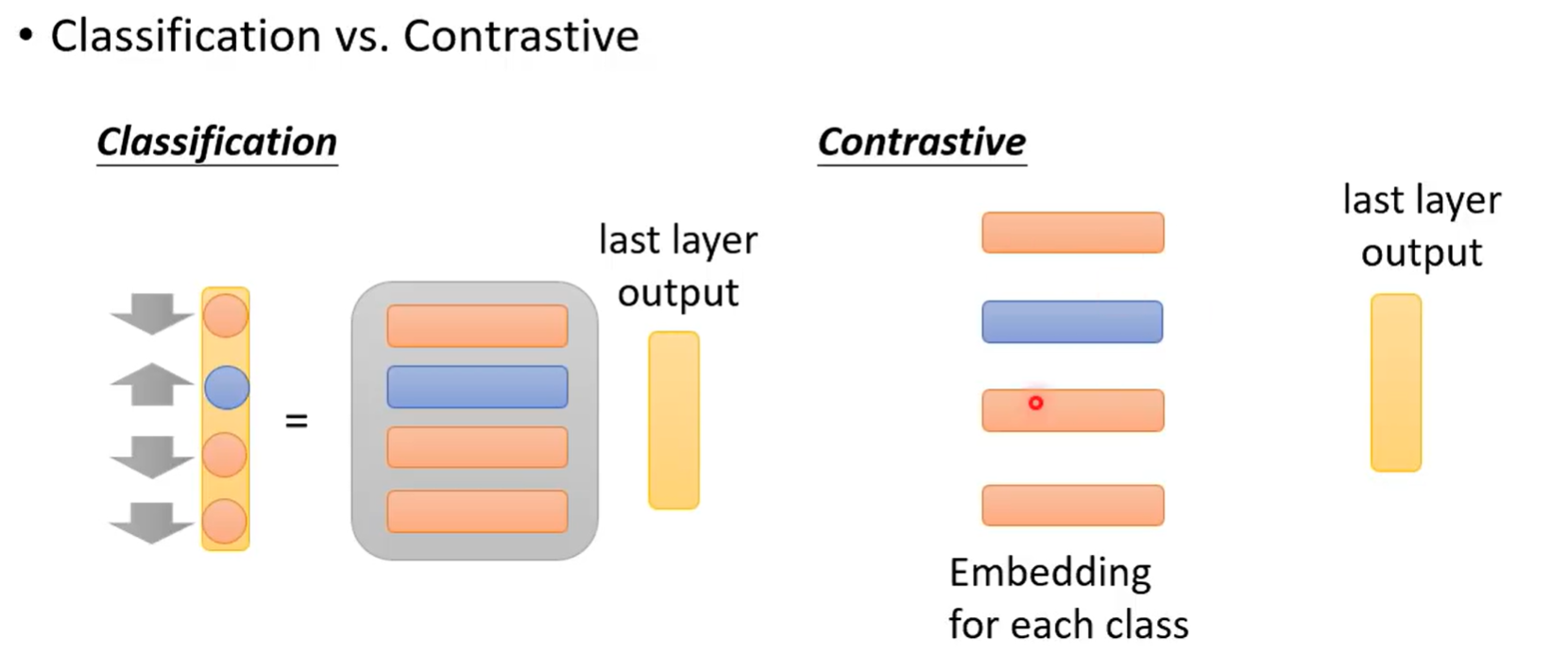 分类和对比学习相似,当分类数量极大时,采用对比学习的思路可以减少类别,达到不错的效果
分类和对比学习相似,当分类数量极大时,采用对比学习的思路可以减少类别,达到不错的效果
文字的负样本有限,但是语音的负样本可以无限 所以可以采用clustering等技术,离散化声音信号来让负样本有限
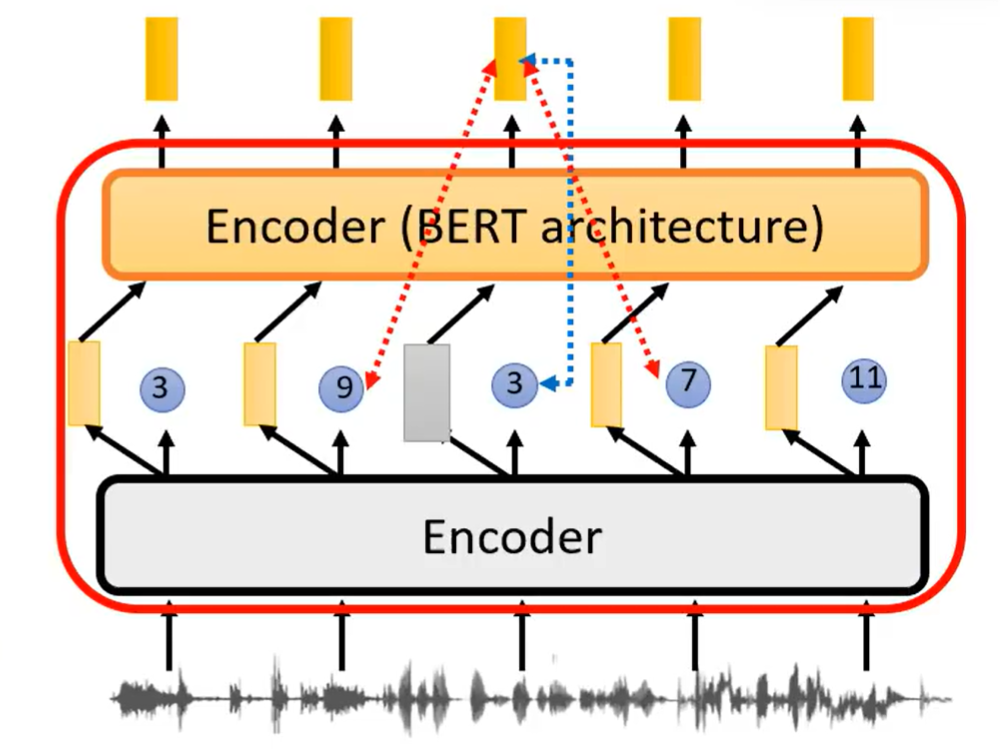
对比学习的难点在于正负样本的选择,需要有一点的难度,但是又不能过于困难
Bootstrapping
自举网络
只使用正样本而不使用负样本
- 左右模型架构不一样
- 只更新右边
- 更新一次后用右边的encoder更新左边
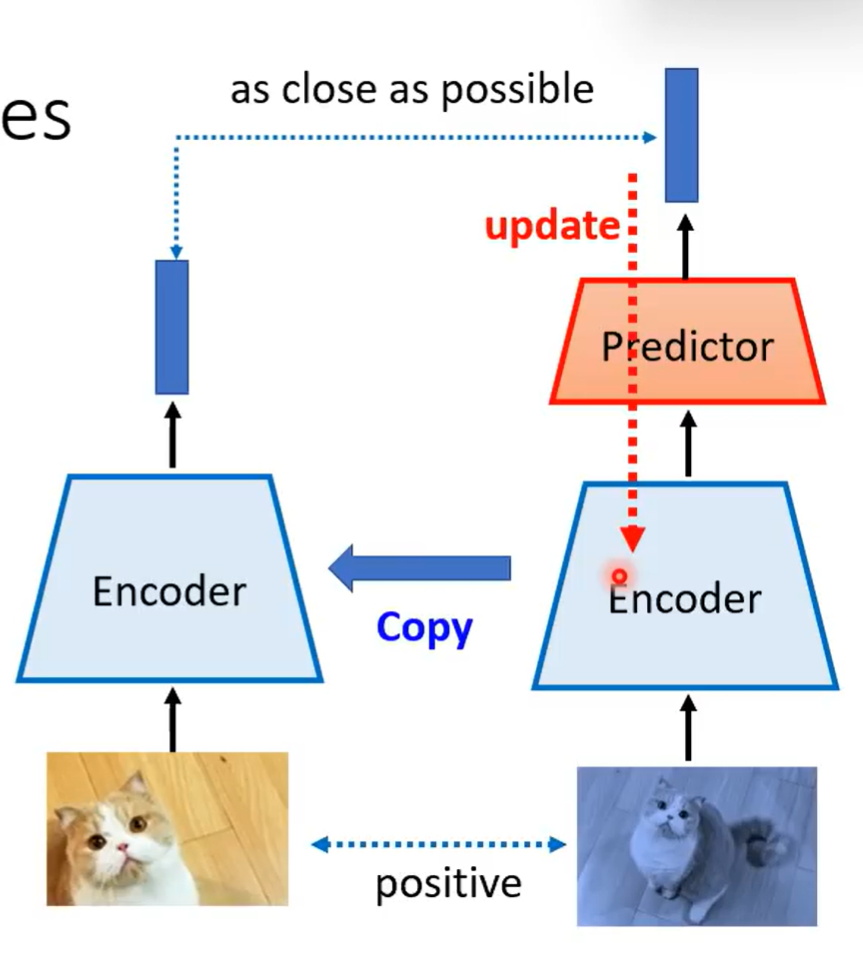 这其实类似于知识蒸馏模型
这其实类似于知识蒸馏模型
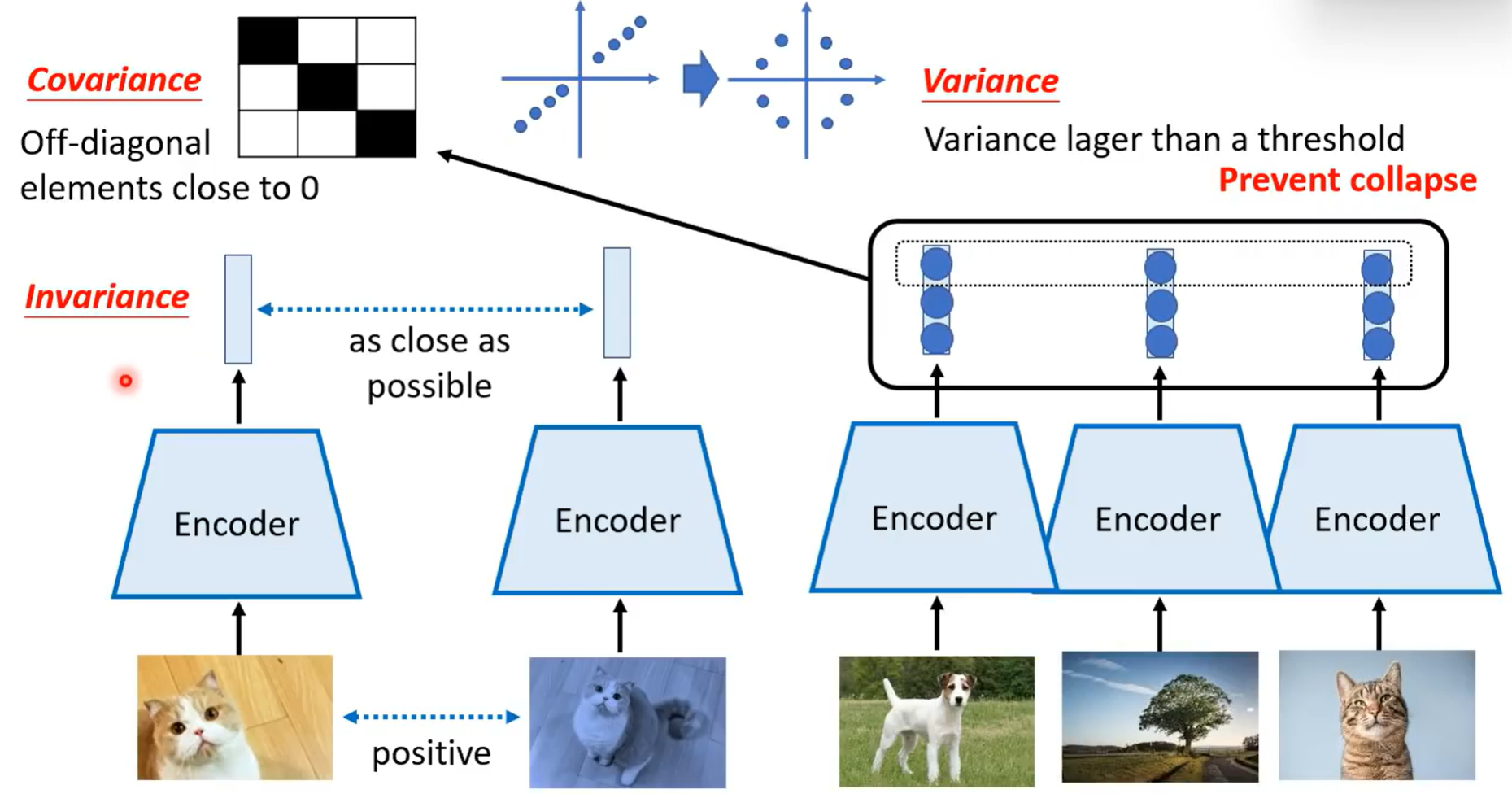
Regularization
只是用正样本
- 要求二者特征相近 仅仅如此训练会导致模型坍塌
- 所以要求每每维度之间要保持不一致
- 添加斜方差可以让效果更好
Auto-encoder
概念
将图片(长向量)编码降维,再通过解码升维还原,训练最终结果与初始输入结果越相似越好
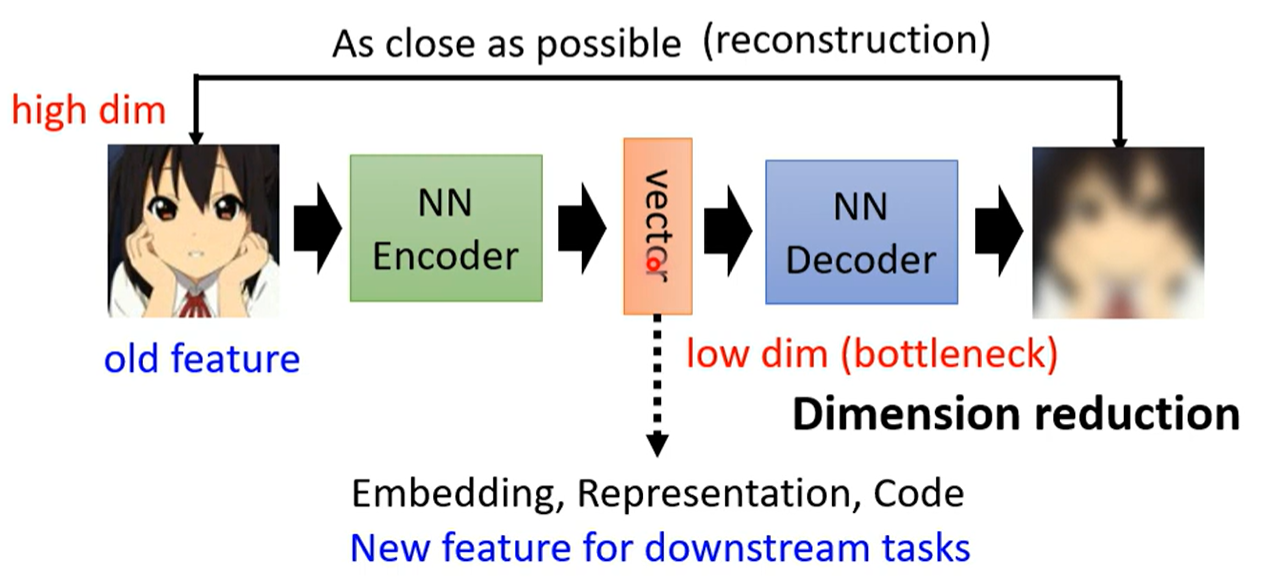
无需标签的学习,类似Cycle GAN,训练之后用编码器进行下游任务
因为两端大,中间小,也称为瓶颈层 bottleneck
为什么有效
为什么降维后再升维可以得到原来的输入?为什么可以通过低维度得到高维度的结果?
因为图片的分布其实是有限的,并非所有的分布都会是图片
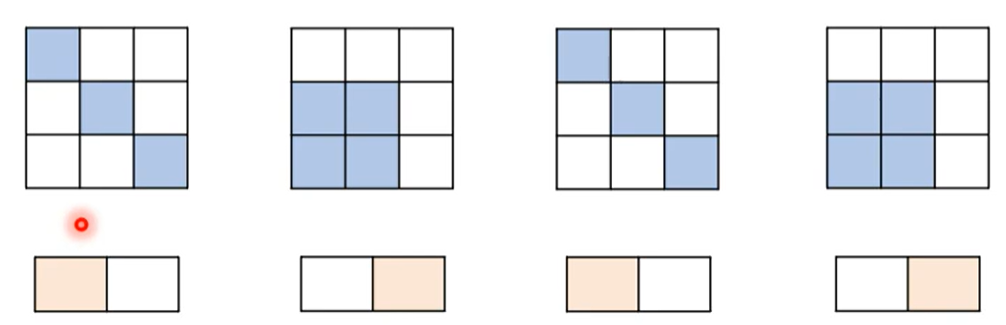
De-noising auto-encoder
在原来auto-encoder的基础上增加噪音,让原本输入的图片上存在噪音,经过编码译码之后还原没有噪音的图片
实际上与BERT的训练类似(mask 就是增加的噪音)
Feature Disentangle
特征解耦
概念
在做Auto-encoder的时候,编码得到的特征是多维度的,但是其哪些维度代表了哪些特征(例如语音内容,声调,音色)是不清楚的,所以提出特征解耦的技术,希望分清维度代表的信息
应用
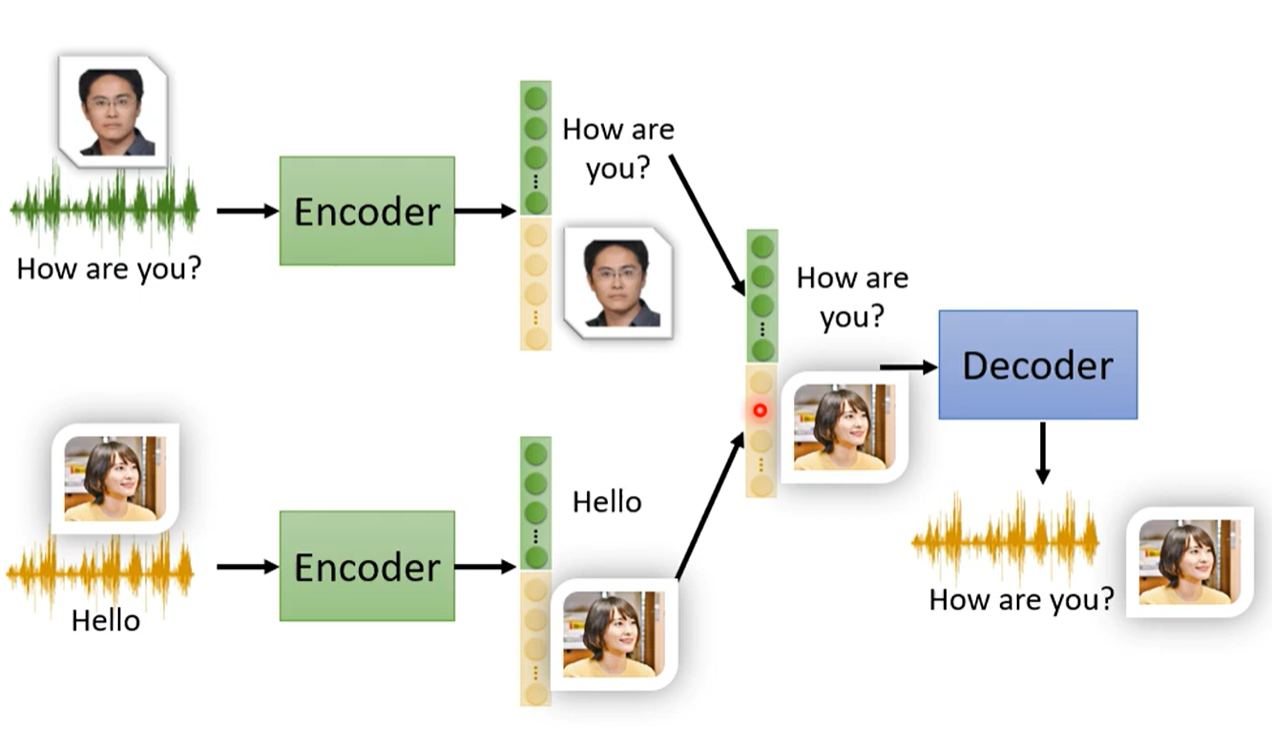
- 语音转换
做特征解耦之后,将音色信息互换
Discrete Repersentation
离散化特征
将编码后的特征向量离散化,例如Binary或One-hot,来表示某些特征的有无或属于某种类别等
应用
-
VQVAE 训练得到向量的字典(codebook),即一系列向量,再将encoder得到的特征向量与这些向量做Q & K查询(计算相似度),找到最相近的向量,用该向量做为decoder的输入
这样就做到离散化原向量,使得特征向量只有已知的数量有限的选择
More
-
Generator 将decoder作为生成器使用 例如VAE
-
Comperssion 压缩,用encoder做压缩
-
Anomaly Detection 异常检测,检查输入是否与训练的输入相似
并非普通的分类问题,因为有时候会仅有的单一类别的数据(异常数据难以获取),称为one-class分类问题
通过输入与输出的差距,检测当前输入是否与训练时相似,如果差距大,证明并不相似,利用这种机制做到异常检测