Tong Xiao Shuang Li Bochao Wang Liang Lin Xiaogang Wang 2017
Abstract
指出现有行人搜索与重识别任务都在标注训练集上训练,这不适用于现实环境,提出使用CNN网络结合行人搜索和重识别任务
提出一种OIM损失函数,拓展到多个身份的数据集
人工收集并标注了一个大规模的数据集,包含18184张图像,8432个个体,96143个预训练人物框
Conclusion
指明主要贡献在于将行人搜索和重识别结合到一个网络,提出一种新的OIM损失函数,这种函数的非参数性质使得网络更快更好的收敛,并进行了证明。
Intro
枚举文献指明行人搜素和重识别的用处、社会意义和研究现状
指明结合搜索和重识别的研究意义为:更好的贴合实际应用
介绍之前有一篇论文提出使用滑动窗口进行搜索实现行人检测,并与匹配分数相结合的策略,又由于存在人工参与的特性,该工作无法拓展
介绍联合处理搜索与识别的CNN网络架构
图片经过一个行人选择网络框选可能的行人,框出来的结果送给识别网络与目标人物进行特征对比,两个网络相互适应,联合优化
例如选择网络可以专注召回率而不是准确率,因为错误的结果可以被特征识别并删除
传统的重识别特征学习采用二元或三元的距离损失函数,低效,且样本数量少,潜在的组合多,不同采样策略影响训练,而组合数量越多训练采样就越困难
使用softmax的也会随类数增加导致计算变慢,甚至无法收敛
OIM 维护一个所有标签个体的的特征查找表,比较当前batch的样本与全部注册实体之间的距离,同时,图像中会存在一些非标记的个体,这些个体可以作为标记个体的负样本,因此可以利用循环队列存储其特征进行比较。OIM损失函数比softmax损失函数收敛更快,更好
最后再次重述了文章贡献:
- 集成的搜索与重识别网络
- OIM损失函数
- 开源数据集
Related work
将过去re-id工作的一些发展,从人工标注的特征、学习特征距离、跨相机视图的特征变换到CNN应用,二元验证损失函数,对比学习的应用
介绍行人检测的发展,从手工标注到CNN结构
Method
模型架构
输入经过Stem CNN网络提取特征,获得特征图,特征图一起用于行人选择(proposal)网络和带Rol Pooling的识别网络,经过识别网络提取L2归一化的维度为256的特征,与目标行人的特征计算距离。通过OIM损失函数训练识别网络,其他损失函数的组合训练选择网络
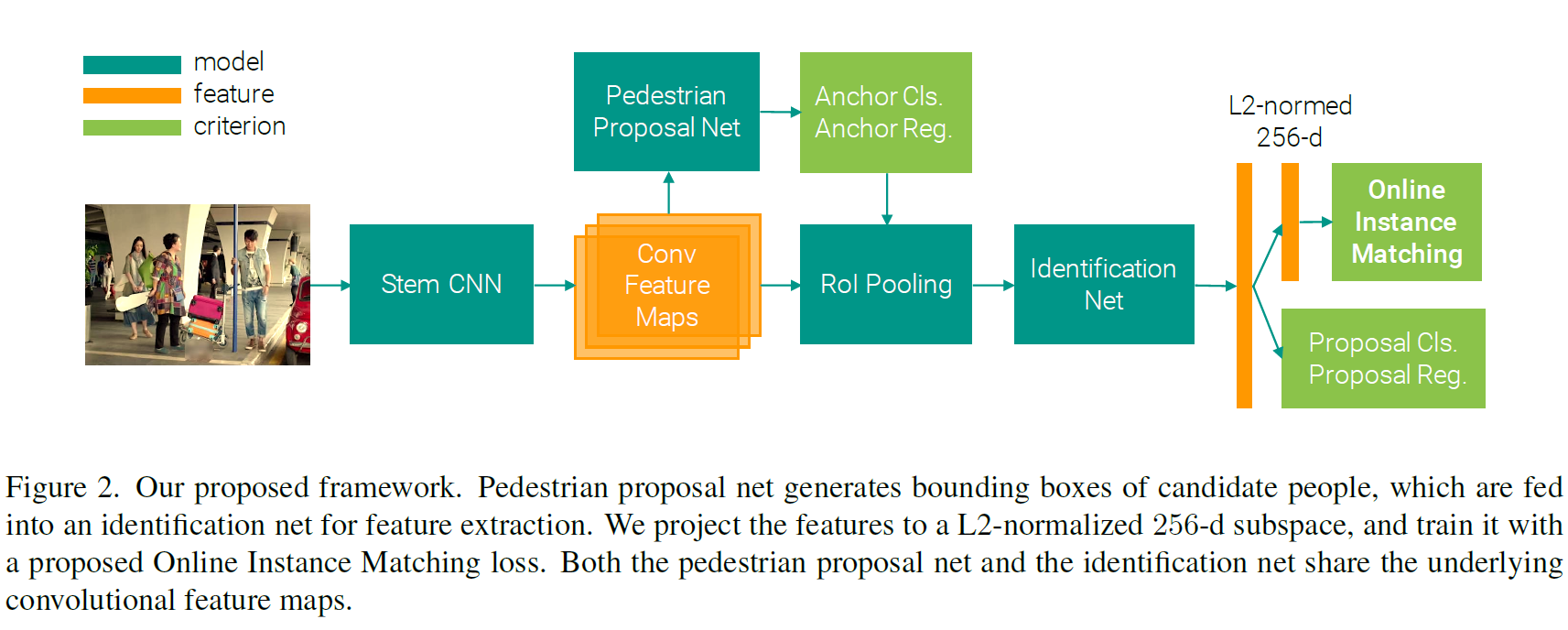
ResNet-50 使用ResNet-50作为基础模型,从conv1 到 conv4-3作为stem CNN,这样一来1024通道的特征图,尺寸缩为1/16
Person proposal Net 使用一层512 * 3 * 3 的卷积层,专门用于转换行人的特征,依据参考文献设置9个锚点,使用softmax分类每个锚点是否是行人,用线性回归调整其位置,在Non-maximum suppression 后选择128个作为最后的选择结果
Identification Net 使用RoI-Pooling layer对框选结果进行池化,再将结果送给ResNet后面几层,经过全局池化变成2048的向量,由于行人proposal的结果会无可避免的存在错报,使用Softmax分类和线性回归非行人的框选结果。将结果进行L2正则化为256维度的子空间,再计算余弦相似度
OIM损失函数
Identities 三种分类
- 标签个体
- 非标签个体
- 背景 其中,标签个体为框选到的和目标个体匹配的;非标签个体是框选到行人,但是不在目标之中;背景为错选结果
Lookup Table
目标是最小化相同个体的不同实例之间的距离,最大化不同个体之间的距离,为完成这个目标,需要存储每个个体的特征,但是这无法用梯度下降来优化。
提出额外构建一个查阅表,利用这个查阅表存储所有的标记个体,在前向传播过程中计算当前 batch 中的 sample 与所有标签个体的余弦相似度,在反向传播时,用学习到的新特征加权更新个体的向量
Circular Queue
除了有标记的个体之外,未标记的个体的可以作为负样本
使用一个循环队列存储最近在batch里出现过的未标记个体,利用这些个体计算余弦相似度,在每一迭代时,push新的向量,弹出旧向量
OIM损失函数
在有了两个数据结构之后,再套用softmax,每个个体的分类概率为
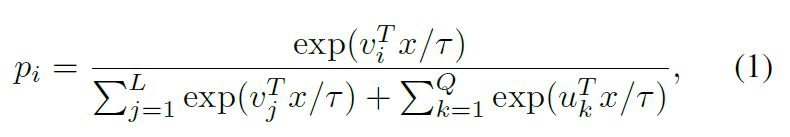
定义OIM损失函数是其对数,目标是最大化对数的期望值
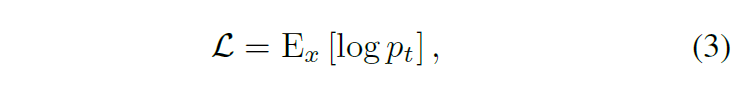
对x求偏导可得
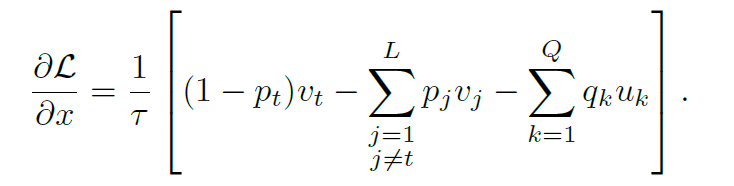
可以看到这个函数对标记和未标记个体都有考虑,驱动向量与目标向量相似,与其他向量远离
Why not Softmax
数据集中任务数量大,每个个体仅有几个实例,每个图像仅有几个个体
使用SGD优化的路线每次正样本很少,梯度方差大,适当预训练和高动量也难以学习
其次是因为数据集中没有明确的类id
非参数 OIM损失函数与Softmax函数类似,但是OIM损失函数是非参数的,是通过外部数据结构计算,更新的,不需要参数的更新迭代,学习快,但是容易过拟合,使用L2归一化可以有效降低过拟合
Scalability 个体数量增加时,计算等式(1)中的分割函数可能会很耗时。为了克服这个问题,我们可以通过对标记和未标记的恒等式进行子采样来近似分母,从而优化方程(3)的下限。
为了减少计算复杂度,作者提出了一种近似方法,即 子采样分母中的项。其基本思想如下: 1. 全量计算分子: 对分子部分,即目标身份 iii 的特征向量和当前样本特征向量的点积计算,保持不变。 2. 分母子采样 : 在计算分母时,不是使用所有 N+LN+LN+L 个特征向量,而是从中随机采样出一部分特征向量(例如,固定采样 kkk 个),用这些采样的特征向量来近似原本的和。 3. 加速计算: 通过对分母项的子采样,减少了每次计算时所需的特征向量数量,从而显著降低了计算时间。同时,由于采样过程是随机的,最终损失的估计仍然是无偏的。
Dataset
Statistics
论文作者自己收集整理的一个数据集,其中部分来自现实场景,部分来自电影画面
作者移除半蹲或姿态奇怪的热恩,同时也不选取衣着打扮变化的人;确保背景人物没有出现标记的个体
对个体在图像中的大小,和不同来源,行人和实例的数量进行分析统计
Evaluation Protocols and Metrics
将数据分为查询和库,对不同的个体,随机选取一个实例作为查询,为这个查询分配包含两个部分的库,一部分是其他实例,一部分是不包含该个体的其他个体
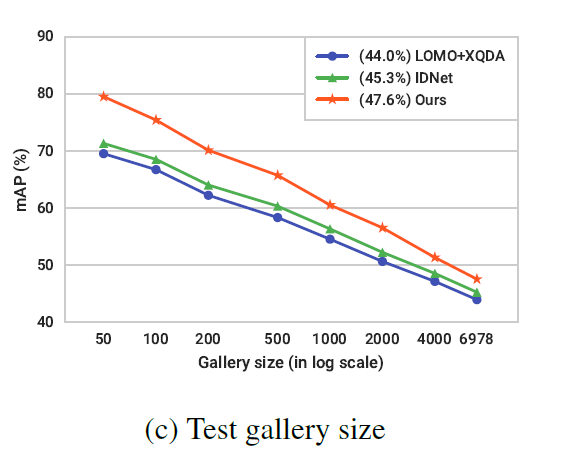
为分析图库大小对人物搜索性能的影响,设定图库大小在50-4000之间
Metrics 设置两种指标
- cumulative matching characteristics(CMC top-K) 继承自re-id任务,与ground truth的联合交集(intersection-over-union, IoU) 大于等于0.5的,如果前k个预测边界框至少有一个重叠,说明匹配
- mean averaged precision(mAP) 根据精度召回曲线计算每个查询的平均精度(AP),然后对所有查询的AP取平均获得最终结果
Experiments
Setting
三个行人检测和五个重识别模型进行对比
行人检测包括:
- CCF
- ACF
- CNN
- Gound Truth作为最佳结果
重识别:
- DSIFT
- Bag of WoW
- LOMO
- IDNet 在训练中发现图片中的背景杂讯作为一个类别可以提高结果精度,而未标记个体却不会
Comparison
论文模型的精度高以往最高高了接近几个百分点,作者认为主要高在检测和识别的联合优化,以及OIM损失函数中使用到了未标记的数据
行人检测方法对re-id的精度有一定影响,另一方面不同re-id方法的相对性能在探测器上一致
Effectiveness of OIM
对比损失函数的作用:
- Softmax
- OIM
- 预训练+Softmax 发现,没有预训练的softmax在大数据下难以训练一个大分类器;预训练之后精度变化慢;使用OIM的话开始精度差,但是变化快,不用训练一个大分类器
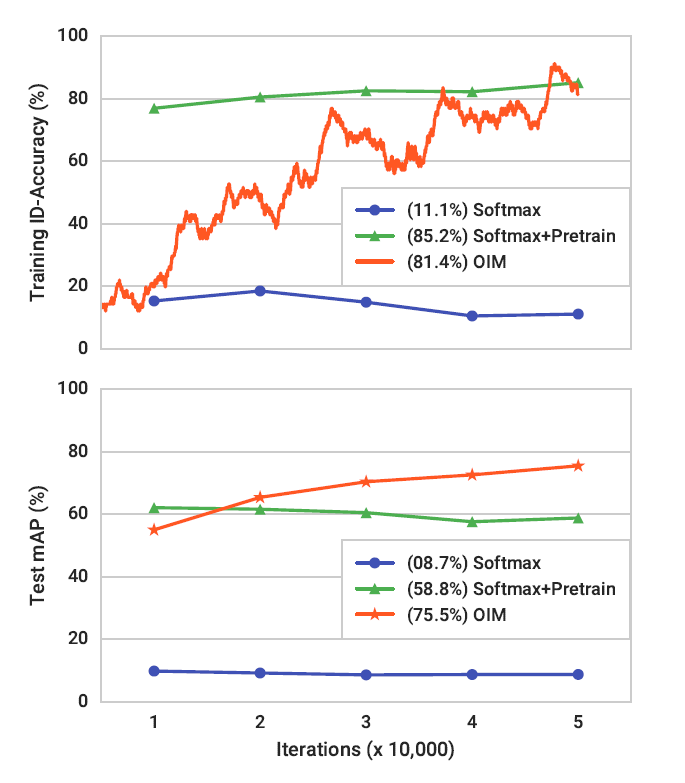
并且训练和测试标准之间的不匹配不复存在,因为都是通过L2归一化做内积计算的,具有余弦相似性
进一步使用OIM在标准的行人重识别任务,训练CNN模型与Softmax进行比较,说明OIM的优势
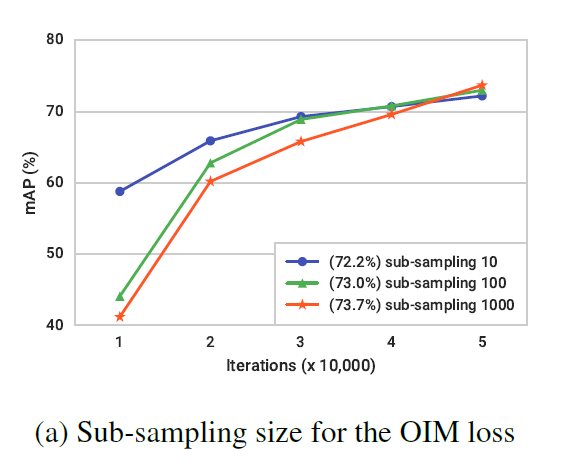
Sub-sampling 大量数据情况下,OIM的计算会成为模型的瓶颈,通过采样计算的方法减少计算量,虽然精度下降一些,但是适用于更大的数据
Low dimensional subsapace 论文还研究了L2正则化维度对模型的影响,发现如果正则化后维度太大,虽然训练集上精度高,但是测试集下降大,这说明投影到合适的低维空间对模型的训练很重要
Factors for Person Search
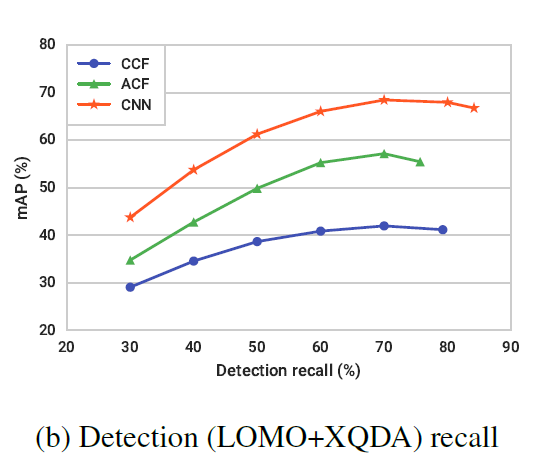
通过 LOMO+XQDA 的方法,设置不同的检测分数阈值来研究了召回率对检测的影响
发现低阈值可以减少误测,提高召回率,高召回率却不一定能够导致好的行人搜索表现
库大小也影响方法性能,小一些的库(涵盖所有图像)有更好的表现,大尺寸的库会有较差的表现,但是方法之间的精度接近,表明所有方法都可能收到一些难样本的影响,可以通过数据挖掘来提高性能