Di Chen, Shanshan Zhang, Jian Yang, Bernt Schiele
Abstract
指出行人检测和重识别的矛盾:行人搜索重在发现行人之间的共性,重识别侧重多个身份的差异,协调好二者的关系在行人检测任务里至关重要
提出规范感知嵌入的新方法,将嵌入的人分为 norm 和 angle 分别进行检测和重识别
进一步将propoal 网络拓展到像素级,辨别能力受框选的错位影响小
指明成就
Conclusion
重申方法和性能,指出在两个基准数据上跑出不错成绩
Intro
进一步说明行人检察与重识别的矛盾性,检测分类目标倾向于挤压所有人物的向量空间,不考虑身份,从而更好地与背景分离,实现检测的目标,但是这让他们与背景实例共享特征空间,限制了不同身份之间的角距,其检测与重识别性能低于单独训练的结果
Goal 轻量模型行人搜索模型
explicit decomposition 显式分解,共享行人检测和重识别的表示,分解成 径向范数(radial norm 用于行人检测,作为边界的检测置信度;角度(angle) 用于重识别,检测人之间的余弦相似性
其中嵌入范式用二元分类损失优化,角度使用 OIM 优化,将查询人的范数定为1,计算与proposal的相似度
由于嵌入规范(embedding norm)的使用,称这个方法为 norm-aware embedding(NAE)
为解决框选对齐问题,提出对框选的每个patch(逐像素) 的置信度进行重新加权,具体来说,对每个提案进行细粒的(fine-grained) 人物/背景分类,作为是否是人的置信度,用作注意力权重,可以抑制背景杂讯,集中在人物区域上
结合上述,使用了norm-aware embedding,合称NAE+
Related
简介 行人搜索 工作,指出相似度的计算方式与 CWS(Class Weighted Similarity)具有相似性,但是与其后处理的模式不同,而是显式分解,可以更好的学习特征
简介re-id,指出最新的方法并不是对所有的位置的卷积特征,而是提取局部特征并连接在一起,通常将特征图划分为水平条纹,用于细粒度高(fine-grained)的特征学习;而文中则细化到像素,重新加权计算
简介行人检测(Detection),指出文中模型基于改进的Faster R-CNN进行拓展
简介嵌入范式(embedding norm),指出之前人将其作为正则化项增强效果,文中则是明确进行应用
Methodology
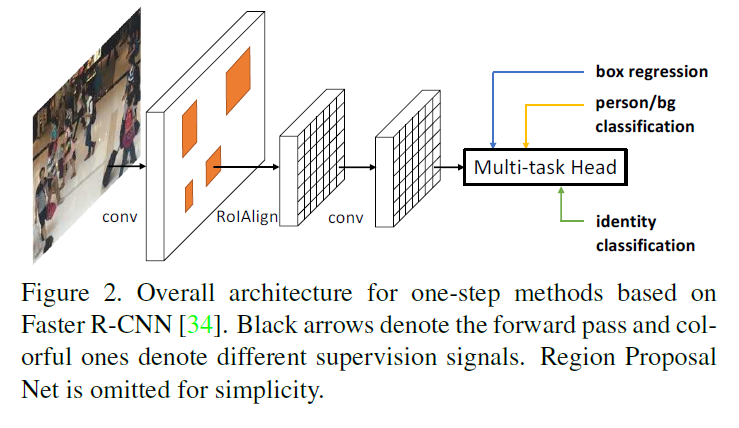
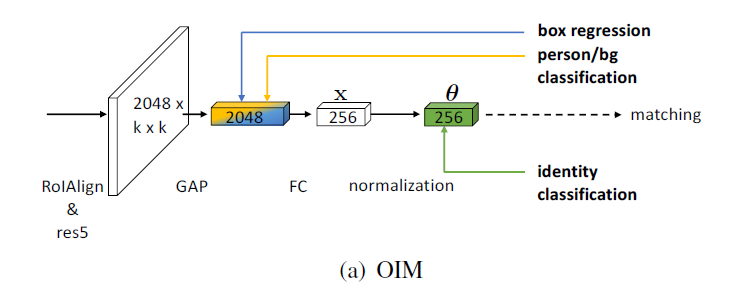
典型的端对端的行人搜索方式,基于Faster R-CNN,在顶层卷积后增加一个多任务的预测头。最具代表性的是OIM,将L2归一化全连接层与全局平均池化卷积特征相连,使用身份识别的损失函数监督全连接层产生的特征向量
相比之下,范数感知嵌入方法删除了原来在池化层上进行的区域分类,使用嵌入范数作为人/背景的分类置信度
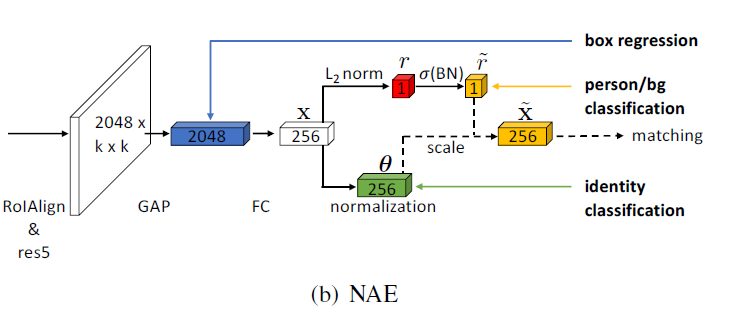
Norm-Aware Embedding
最后一层经过GAP和FC之后转化成维度为256的向量x,将x分解成 ,其各自是256d的向量
使用单调映射将norm压缩到 之间
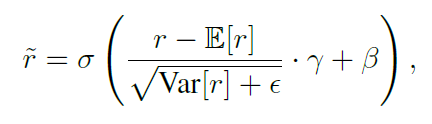
Matching 对于每个行人的查询,首先通过删除RPN模块将框选坐标(proposal coordinate)设置为给定的边界,提取,框中必有一人,并将其范数 r 预设为1,与库中行人计算相似度
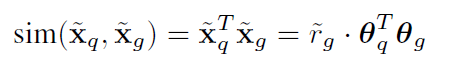
则最后的相似度就是余弦相似度,且为识别的置信度
同时使用CWS(Class Weighted Similarity)在训练过程中显式分解检测和重识别的嵌入
规范感知嵌入用于区分身份又抑制错误的检测,通过重识别和检测信号监督,将检测信息投射到范数 r 上,在二元分类的损失函数中引入,定义函数
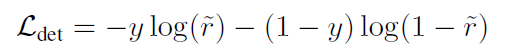
其中y是 标签,表示proposal是行人还是背景
同时使用OIM损失优化 ,对于RPN分类和box regression ,使用SGD进行优化
Pixel-Wise Extension
最后的特征图会被池化成一个向量,失去空间信息,论文认为这样一来,框选结果就会受到不对齐的区域影响,增加了数据的噪声
通过突出人体部分,并抑制背景区域来更好的利用空间信息,用1 * 1 的卷积核对顶部特征图做卷积,得到一个 256 * k * k 的张量,然后每一个位置都进行归一化和缩放,转换成规范感知嵌入,保持空间结构
每个位置的范数 r 作为这个位置的空间注意力,作为像素的重要性
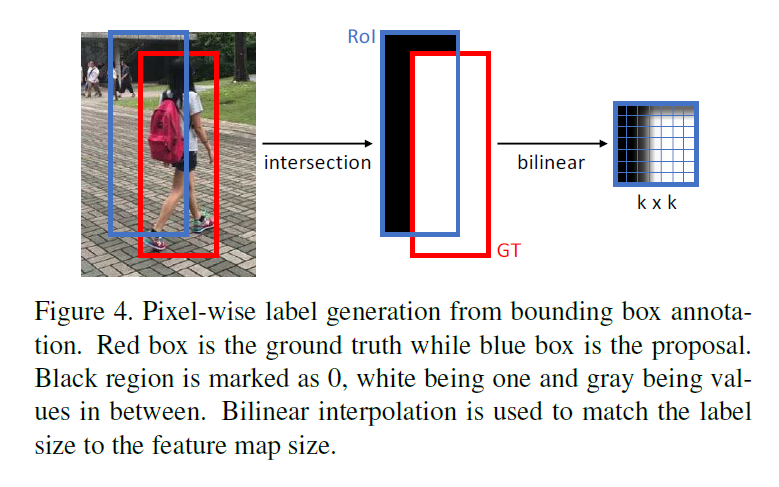
通过二元的交叉熵来监督每个像素的 r ,由于没有ground truth,需要从框选的结果中获取粗略的ground truth
对每个框选,都对其与被认定为ground truth的框选交界认定为1,其余为0,插值将RoI box的大小调整为 k * k,定义损失?
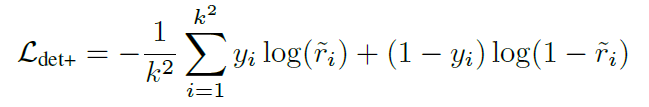
y是生成结果中逐个像素的标签,其值介于 之间
即使训练了像素的概率图,每个像素都要用于计算其置信度,直接取平均的方法会被低置信度的拉低整体的水平,可以除以最大的置信度来拓展,简单来说就是标准化,减少不同置信度的差距
Experiments
Datasets
介绍两大数据集,CUHK-SYSU,PRW,介绍评估指标除了数据集表现还有:mAP 平均精度,CMC 累计匹配特征,时间
Setting
使用ResNet50作为主干网络,前4个卷积块作为特征提取网络
遵循前人设置,设置锚点,对正面的proposal采样,下限是与ground truth 的 IoU 0.5,与负面proposals的IoU在
通过RoIAlign layer,将proposals裁剪并转换成 14 * 14 ,将ResNet第5块卷积块定为头网络,将proposals转成2048d,7 * 7的特征图,定义其他预测头进行任务的预测(box regression/norm-aware等)
初始学习率0.003,16个epoch下调10倍
Analytical Experiments
设计了四个模型,OIM-base(改进了输入图片尺寸,密集锚点,RoIAlign),OIM-base w(在OIM-base基础上增加类别加权相似度计算),NAE,和NAE w/o(无CWS)
召回率和平均精度衡量检测,mAP和top-1精度衡量重识别
Visualized Inspections
可视化输出概率图,删除了RPN(Region Proposals Network)和RoIAlign,将检测概率图用双线性插值采样,用不同颜色表示后与输出图像叠加,对检测结果进行可视化
同时对一些难样本的检测结果进行展示
Comparison to the State-of-the-arts
超过所有一步法,在CUHK-SYSU超过大部分两两步法,PRW超过所有两步法
在时间上超过最先进的两步法和一步法