ICCV 21 最佳论文
使用移动窗口的层级Vision Transformer
Abstract
ViT指出Transformer的可用性,但是无法证明其普适性,Swin Transformer则证明了可以使用Transformer做所有视觉任务的骨干网络
存在一些挑战:
- 图像尺寸 图像的语义信息大大小小,相同语义的车,行人在一张街景图片中可大可小,这是在NLP领域并不存在的问题
- 图像分辨率问题 传统方法中像素决定Transformer的输入,而像素信息很大,计算量巨大无法在CV领域应用
层级式Transformer 通过移动窗口实现
- 更好的计算效率,自注意力在一个窗口内计算
- 层级区分,上下层之间有跨层次的交互(cross-windows),使得计算灵活,复杂度随图像线性增长而不是平方极增长
存在分层次的特征,在下游任务有不错的应用
Intro
模型结构
层级结构 用层级结构来理解,ViT是进行以此16x下采样之后保持不变的层级变换,而且其自注意力始终是在全局进行计算的
其复杂度是图像尺寸平方级别的增长,且对多尺寸特征的提取比较一般
窗口式的设计借鉴卷积设计,固定窗口大小,自注意力计算局限在窗口内,复杂度一定
图片尺寸变大,窗口大小不变,用窗口为单位,其数量与尺寸成线性增长关系而非平方级别增长关系,窗口内计算复杂度确定,所以整体的计算复杂度随尺寸为线性变化
同时利用了Locality的 归纳偏置(inductive biases),用local的自注意力理论上来说式足够的
同时参照池化层设计patch merging层,合并小patch,增大感受野,提取多尺度特征
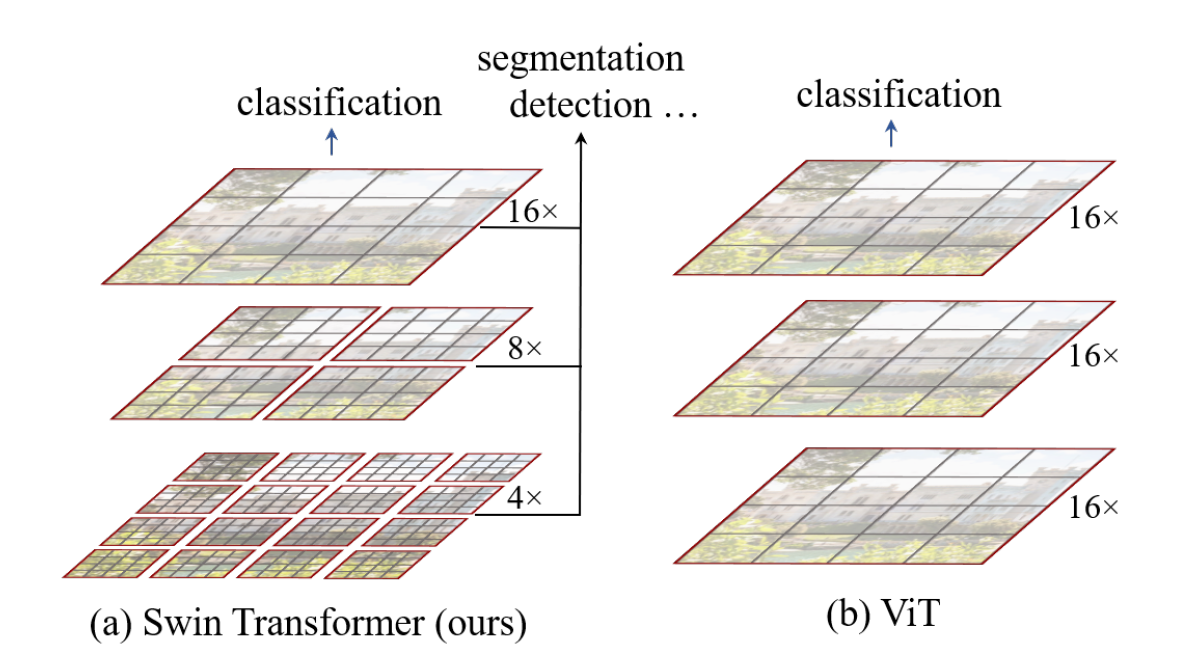
这样一来,提取到多尺寸特征的Swin Transformer就可以连接多种网络,利用这部分特征实现不同的任务
方法
具体设计
移动窗口
如果单单是固定的窗口,那么由于窗口是固定的,在其内部做自注意力就无法注意到不同窗口內部信息,所以需要有窗口移动的操作
具体是在某一层将图片等分为多个窗口,每个窗口包含49个patch(4x4),往右下角移动这些窗口,使得窗口部分出去,新的窗口部分进来,通过这个移动来让窗口之间产生交互
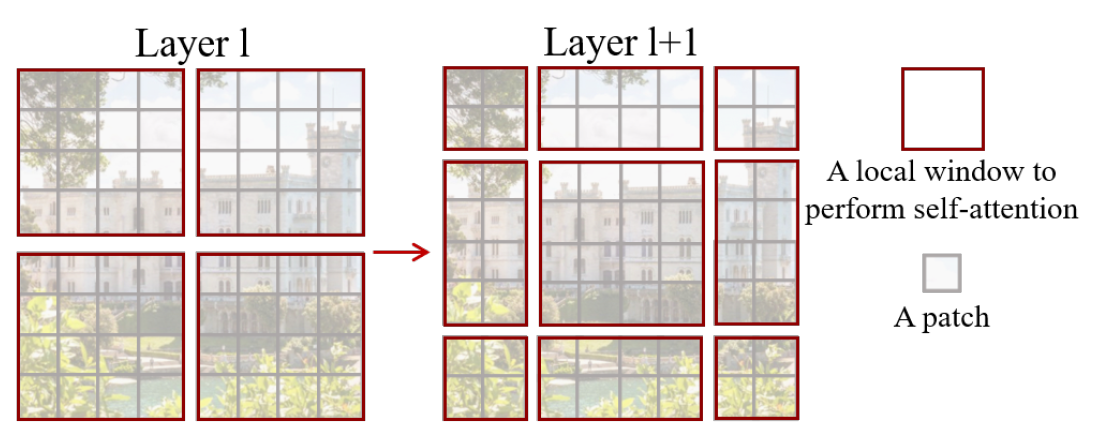
这就是隔层之间的cross-window connection
Method
Architecture
输入是 的图片,其中H,W是尺寸,3是通道数
经过一个patch划分,变成,因为划分为4x4的patch,所以除以4,48是因为一个patch是
在输入Transformer层之前,需要将输入转换成Transformer要求的输入,所以经过一个线性层转换为
经过Transformer模块之后,输入输出尺寸没有变化,其中 拉长变成一维,使用窗口自注意力机制,在49大小的窗口内计算自注意力
Patch Merging 为了实现多尺度的特征,,会对patch进行编号,编号相同的patch会排在一起组成的patch,这一层将patch下采样两倍,再通过降低H,W来获得更多的通道数,其组合而成的新patch在通道维度组合,增加通道数为原来的4倍,但是增加这么多并不满足希望通道数翻倍的设计,所以再次使用 1 * 1的卷积核在通道维度进行卷积,减少到两倍,及最终的输出为

之后的步骤都是经过Patch Merging再经过Transformer
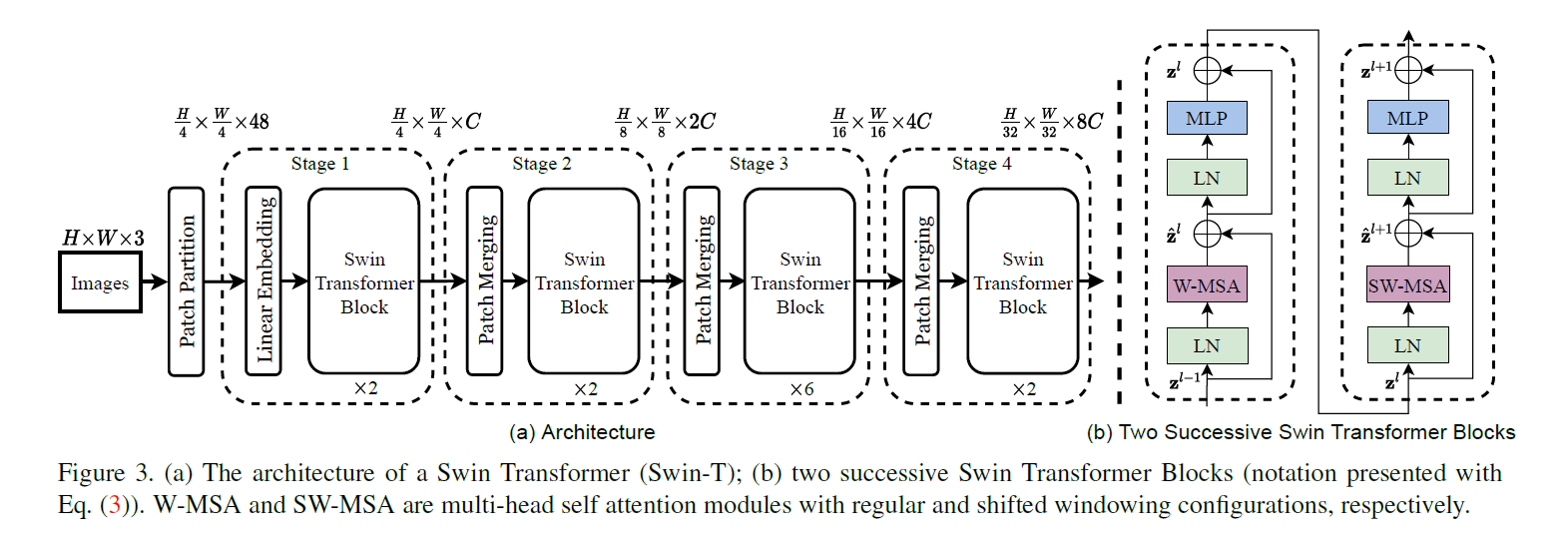
最后可以通过全局池化,再进行分类等任务
Shifted Window based Self-Attention
一个窗口包含7 * 7 个patch,自注意力计算基本单位是patch
计算复杂度
如果是全局多头自注意力机制,计算复杂度如图
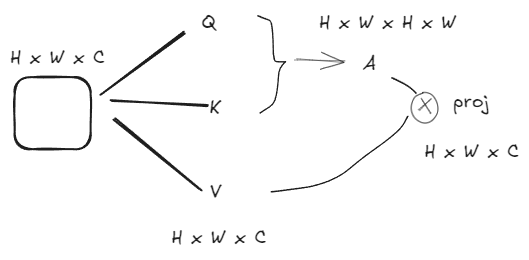
初始矩阵H * W * C,乘上C * C的矩阵,加权计算Q,K,V三个同样尺寸的矩阵,Q和K转置计算自注意力,尺寸为HW * HW,A再与V计算得到最终矩阵,因为是多头自注意力,最后会经过一个投影将结果投影成合适的维度
计算复杂度
增加移动窗口之后,计算单位矩阵尺寸变为 M * M,计算 H / M * W / M 个窗口,及结果是
只用窗口的话会使得窗口之间没有信息交互,没有全局信息,提出移动窗口
论文中采用先做窗口的自注意力计算,经过LN和MLP之后,再进行SW-MSA的即移动窗口的自注意力计算
掩码机制优化
移动窗口计算上实际上存在一些问题,移动后图像中存在大小不一,形状各异的窗口,这不利于模型进行计算
如果通过padding填充图片,则会发现这样一来计算复杂度会增加,因为窗口数量增加
如何局限窗口数量,提出使用掩码机制,先将图片各窗口进行拼接(循环位移),拼成设定的窗口的形状划分图片,再计算自注意力
此时拼接到一起的图片不应该有所关联,因为其本来在图像中距离很远,所以这样的窗口不合并计算自注意力,使用掩码机制,一次计算出各小窗口的自注意力而不相互影响
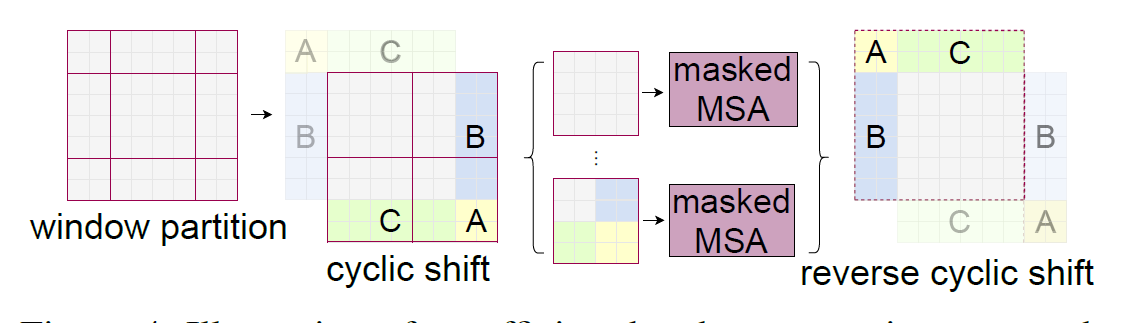
计算之后将拼接的窗口还原到原有的位置,保证多次移动窗口时图片不会被破坏
Mask 通过分析自注意力计算之后,得知自注意力矩阵A中要掩盖掉哪些部分,设计计算模板用同尺寸的掩码矩阵做相加,对要掩盖的位置加-100,其余加0,计算之后,要掩盖位置的自注意力就非常小(负数),再经过Softmax之后就变为0
这样一来就只需要计算有限且固定的窗口,减少计算复杂度
Variants
介绍不同体量的变体
- Swin-T(tiny)
- Swin-S(small)
- Swin-B(base)
- Swin-L(large)
Exper
Classification
预训练
- Image-1k
- Image-22k
与Google 和 Facebook在ResNet架构上搜出来的结构做对比
Object Detection
在CoCo数据集上做目标检测,用同体量的Swin-T与Res50对比其作为骨干网络的优势
Semantic segmentation
ADK20k数据集提了3个点