Abstract
指出主要方法,模仿Bert使用掩盖后预测掩盖patches的方法 提出两个主要方法:
- 不对称的编码-解码网络,只对没被盖住的编码,解码得到完整的图像
- 75%的掩盖迫使模型学习更多图像的表征,实现自监督学习,此时训练同时因为编码的patch数量减少而变快
模型结构图
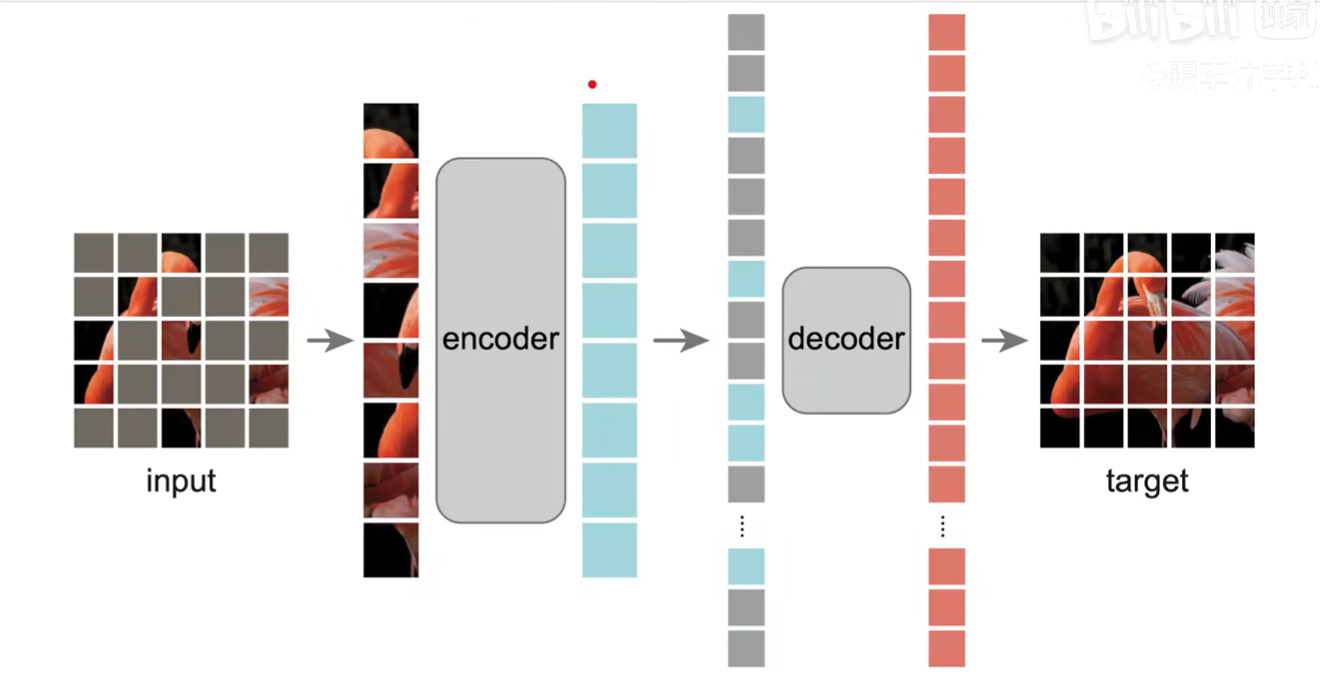
Discussion and Conclusion
提到NLP,提到模型优点:
- 相比ViT计算更少,模型简单
- 自监督效果好,说明Transformer能学到不错的隐藏语义表达
社会性影响(Broader impacts):
- 生成式图片,可能造成一定的社会影响
Intro
尝试回答自监督在CV的应用落后于NLP
-
mask在CNN中的应用会缺乏其位置的边界信息
-
相邻文字的语义填补很难,但是图像的相邻的像素相似性很大
提出: 去掉相邻的块,也就是去掉一大块让剩下的块之间相似度很小
-
自编码的解码的难度较大,像素级别的输出比文本分类难
提出: 非对称(看到的信息大小不一致,编码只看到没有掩盖的,解码要输出完整的图片)的编码-解码器
在迁移学习的效果十分不错
Related Work
BERT GPT相关工作
CV上自编码器的应用
- DAE 传统加噪声的自编码器
- iGPT image GPT
- BEiT 每个patch给了label,更像BERT一点
自监督学习
Approach
自编码器 不对称的编码解码
Masking 随机采样,少量快剩下的全部盖住
Encoder 输入做一个Linear projection,增加位置向量,再经过一系列Transformer Block
Decoder 对掩盖的块,使用一个共享的、待学习的向量进行表示,同时增加位置信息再进行解码;解码部分同样是Transformer block,直接还原像素
Target 使用线形层做重塑,将向量重塑成图片
Loss 损失函数和BERT 一样是MSE,只在mask的patch上计算
Implementation 位置信息与patces向量组成输入向量,随机打乱后取前25%进行encoder;
之后再进行Decoder,unshuffle回原来的位置,在掩盖位置增加可学习的向量信息,再增加位置信息
Exper
在ImageNet-1k上做自监督训练,再做有监督的训练,对比分析优势
监督训练分为:
- end2ed的微调
- 线性探测,修改线性层内容
Baseline 使用ViT-Large做基线模型,事实证明在数据量并不多时,可以增加正则化手段来让结果更稳定
消融实验
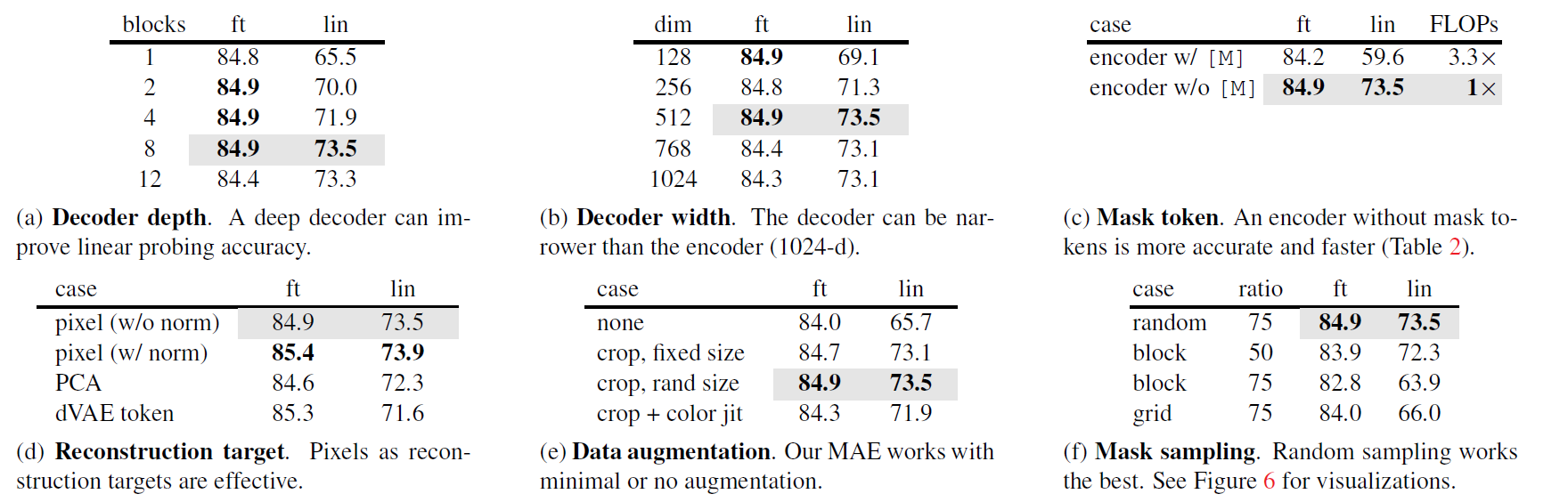
图说明掩盖范围对精度的影响
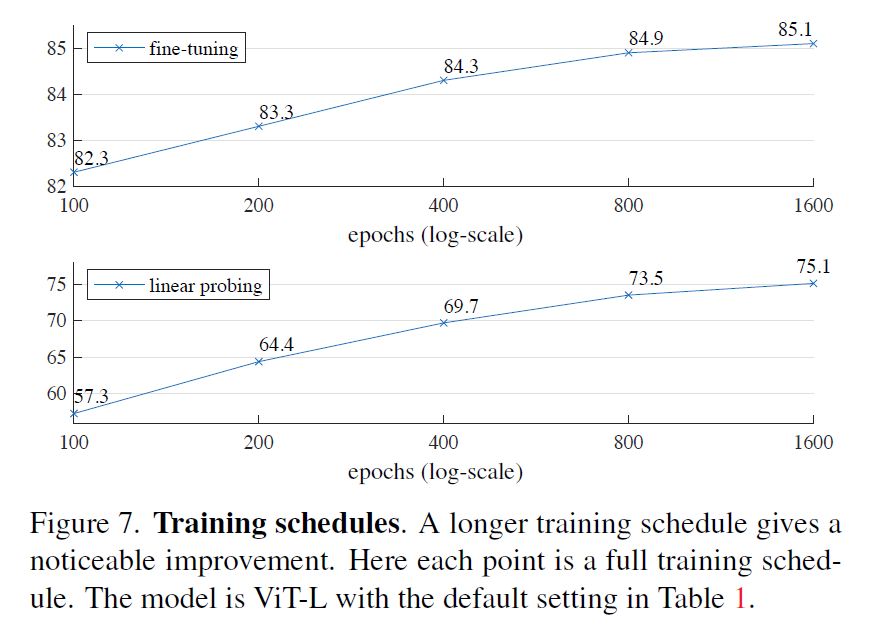
接着各种比较,秀肌肉
讨论了微调与线性探测的区别,微调的效果比线性探测好很多,其中微调的层数有讲究
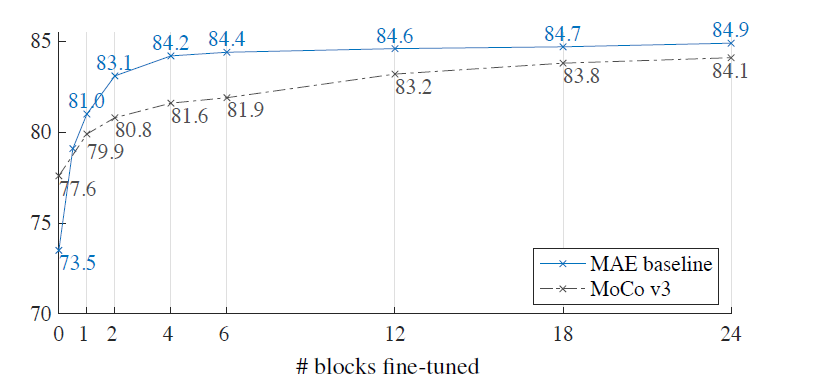 调不同数量的Transformer层会有不同的结果
调不同数量的Transformer层会有不同的结果
Tranfer Learning
迁移学习上的成果
- COCO目标检测和分割
- ADE20K语义分割
- 重构像素/tokens 下,不同模型与MAE的精度对比
总结
简单的想法,不错的故事性,优异的成果
MAE只是在ViT的基础上提出简单的两点:
- 更大的掩盖
- Transformer的解码层,并进行像素直接还原
实现了CV领域在较小数据集上使用Transformer
文章详细的实验和训练分析可以借鉴学习