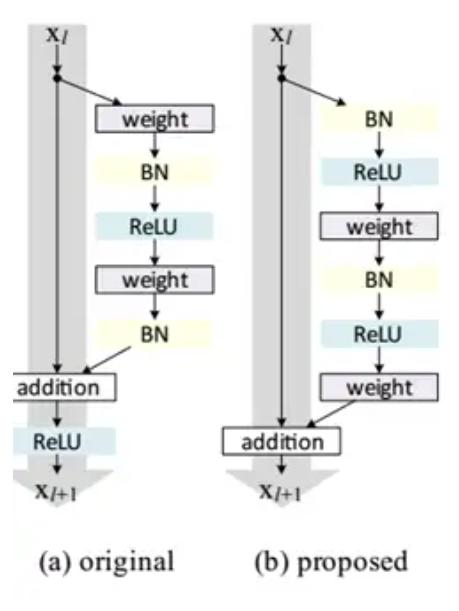
Residual Learning
首先了解退化问题(Degradation problem) 一般的模型在增加深度时会出现退化现象,即深度加深模型性能却变差
这其实很有问题,梯度消失和爆炸问其实可以通过BatchNorm等来缓解,但是退化问题依旧存在,而且被证明不是过拟合,因为其loss也随着深度上升
这很奇怪是因为,其实只要更深的层次做到恒等映射(Identity mapping),即什么都不学,直接输出,精度就不可能变差,但是现实是确实变差了
那就只能是训练的方法导致模型做不到这一点,找不到一组好的参数,所以提出残差学习
假设输入的x,学习到的特征(输出)为H(x),现在希望可以学习到残差F(x) = H(x) - x ,但残差为0时,模型只学习到x,也就是恒等变化,当残差不为0,则模型可以学到更多特征
那这和原本有什么区别?区别在于模型直接学到的只有残差,而通过短路将x同样送给输出做加和
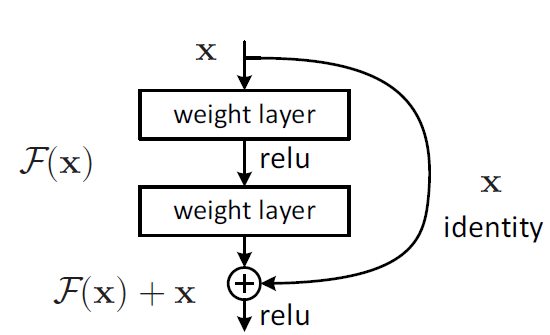
为什么学习残差?因为好学,内容少,难度小,其学习过程
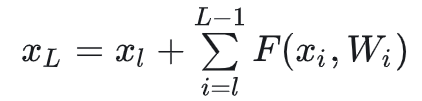
求偏导
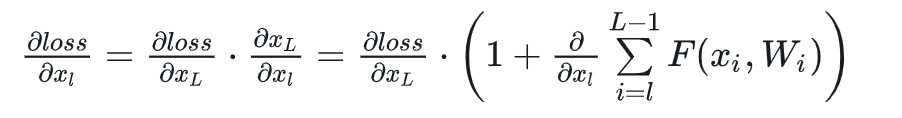 其中第一个因子,表示损失函数到达L的梯度,小括号内1表示短路传送过来的x,另一项则是残差学习项,需要经过权重计算,由于残差项不会那么巧结果是-1,也就是学习的梯度一直存在,不会消失,所以残差学习会相对容易
其中第一个因子,表示损失函数到达L的梯度,小括号内1表示短路传送过来的x,另一项则是残差学习项,需要经过权重计算,由于残差项不会那么巧结果是-1,也就是学习的梯度一直存在,不会消失,所以残差学习会相对容易
一点技巧
ResNet结构表现最好的是实用pre-activation,BN和ReLU提前