InstDisc
开山经典之作
个体判别代理任务
图片的分类结果中,同一类别的图片(例如狗照片),对于不同种类的狗的分类分数都很高,对于其他的分类结果都较小,这是因为不管什么种类的狗都有一定的相似度
将每一个实例都做为一个类别,则无监督学习其实可以看成学习一种特征,这种特征可以区分每一个类别
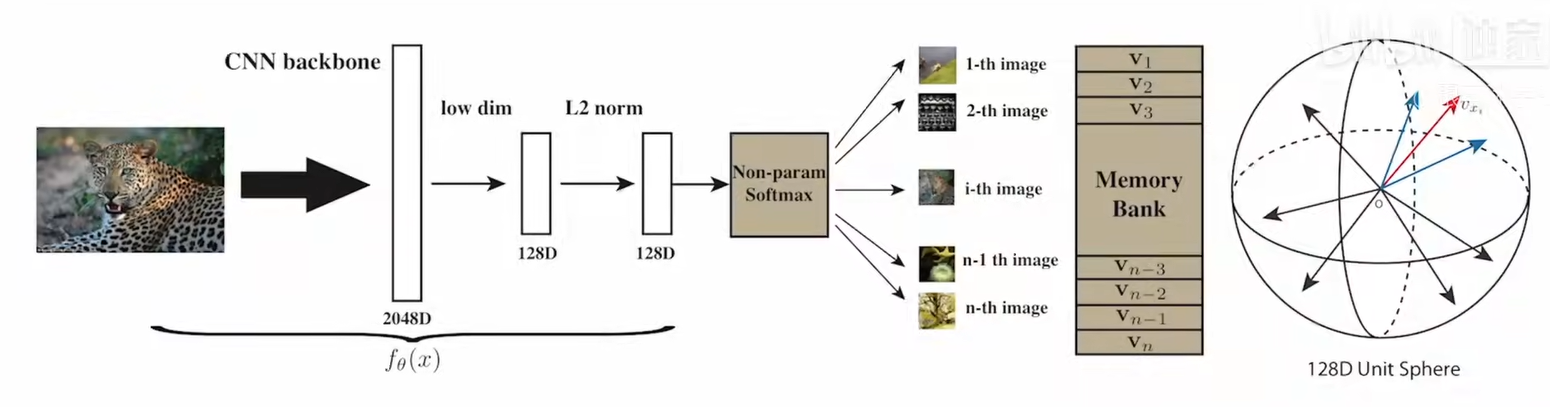
Memory Bank
InstDisc任务为将batch里的整张图片(数据增强)提取为一个特征向量,进行降维,作为正样本
从Memory Bank中取出规定数目的负样本特征,进行对比学习
学习之后的新特征再进入Memory Bank更新旧特征
最后使得不同Instance的特征有区分度
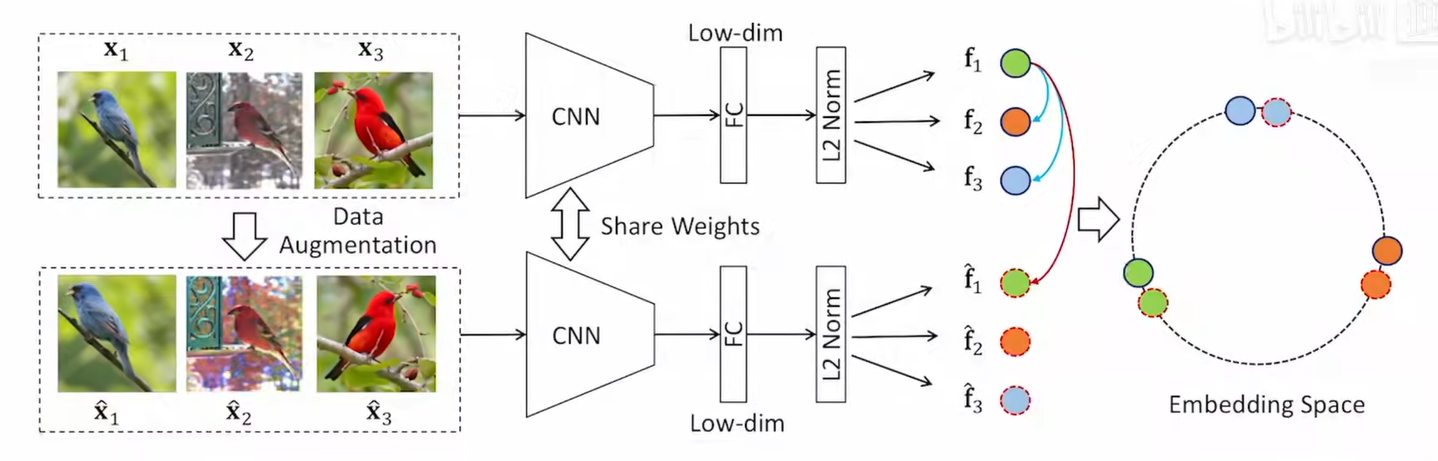
InvaSpread
不变与分散
同类图片应该相似(特征不变性),不同图片应该分散开
论文用batch中的同一张图片及其增强做为正样本,其他所有的图片及其增强都做为负样本,实现模型自行处理正负样本与学习(只有一个编码器,没有外部数据结构memory bank),实现端到端的学习
缺憾
论文没有采用大字典,对比学习的字典要求足够大,所以其结构并不够引人注目
CPC
内容与成就
通过生成器与自回归模型的组合,将生成器的输出送给自回归模型,如果自回归模型能得到不错的结果,学习到前后相关的特征的话,那就可以用自回归模型学到的特征去预测后续的输入。
正样本是后续输入经过生成器之后的输出,负样本是自回归模型的预测
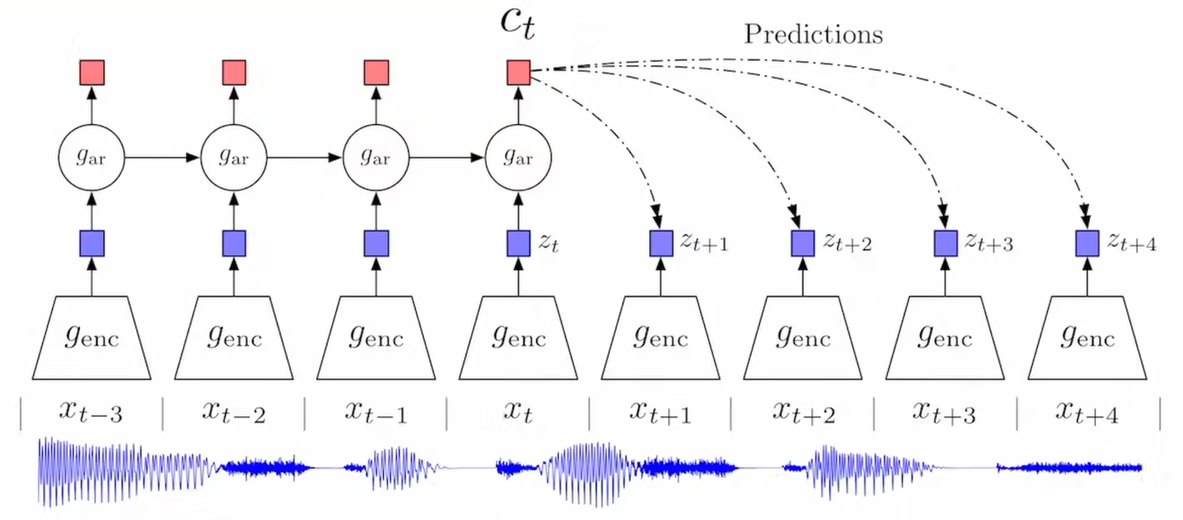
代理任务是预测
CMC
互信息
预想通过学习到不同视角下关键的互信息(各视角下相通的信息)来解决下游问题
正样本为不同视角下的同一张图片,负样本是其他任何的图片,其在特征空间应当保持正确的距离
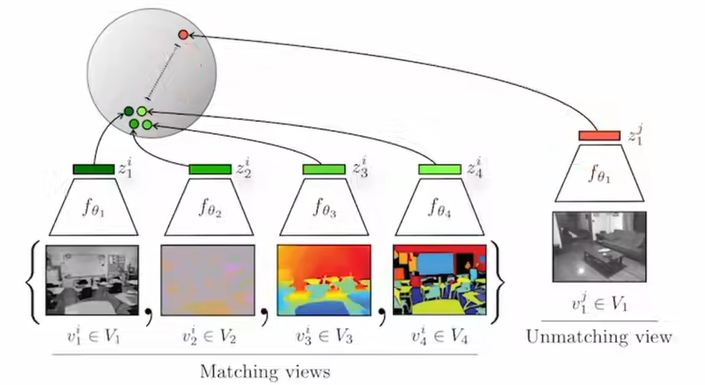
多视角
证明了对比学习灵活性,证明多模态的可行性
局限
多编码器,计算代价高
MoCo
使用动量编码器
将对比学习规整为一个字典的问题?
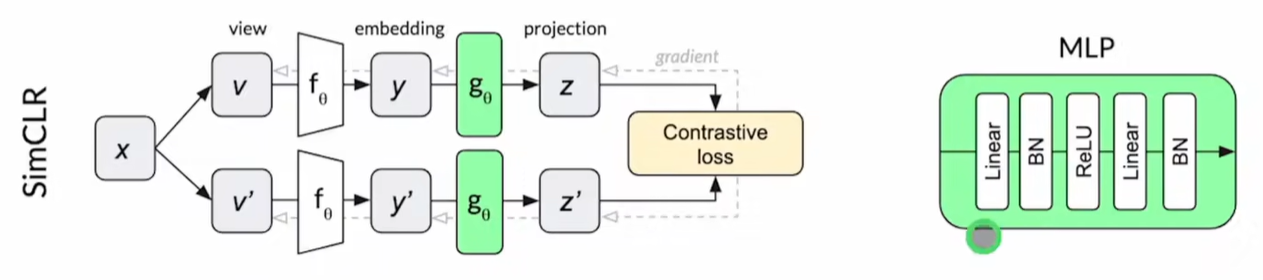
SimCLR
Projection head
总结了前人经验,使用更好的数据增强,一个编码器,外加一个MLP层,更大的Batch size 使得结果大幅提高
消融实验证明了随机的色彩变换和裁剪对最后的结果有用
证明使用大小维度(128)对对比学习的区别不大
MoCo v2
新增MLP层和数据增强
对比SimCLR,硬件需求小
SimCLR
新增三个点:
- 大模型ResNet 152和Selective kernels(SK)增强骨干网络
- MLP加深一层
- MoCo batch的动量编码器
SwAV
聚类
不同视角的特征理应可以相互预测,因为这些特征应该接近
但是直接和全部样本比数据很大,提出使用聚类的方法生成一个更合适的特征,使用聚类中心代替样本特征,缩减对比的数量
利用聚类实现类似预测的任务
Multi-crop
一般的裁剪是直接裁剪大部分的特征作为正样本,但是这样学不到更加局部的特征,提出Multi-crop,裁剪较小的总体特征,再裁剪较少的局部的特征,让局部和整体均衡,增加正样本数量,同时维持较小的计算量
BYOL
无负样本
正样本数据增强,经过编码器,投影层MLP,其中一个经过一个预测层(MLP) 生成一个新的特征,利用这个特征对另一个正样本做预测
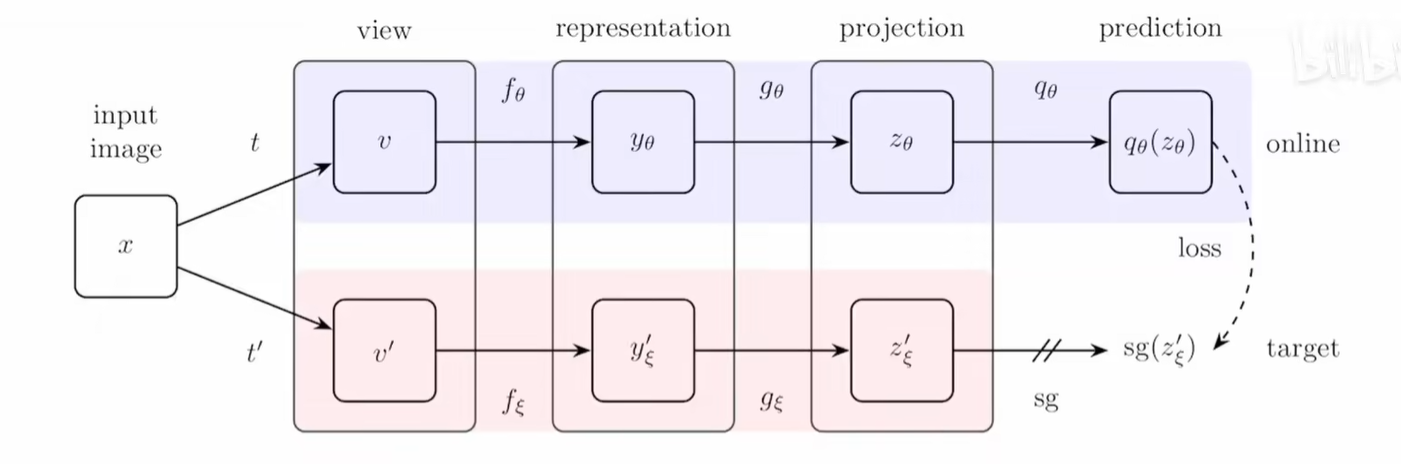
下方是动量编码器
训练之后,只留下编码器去执行下游任务
损失函数直接使用的是MSE,因为只有两个向量的差别
BYOL为什么work
有一篇博客发现在MLP层中有无BN差距很大,使用layernorm的效果也不尽人意,通过消融实验证明了BN对模型表现有很大的帮助
分析认为BN计算时考虑到了所有的样本,涉及到了信息的泄露,这部分信息泄露提供了隐含的负样本,让模型学习到正负样本,从而work
但是原作者进行了一系列论证,使用GN和WS等不涉及隐含负样本的技术,证明了只要给一个较好的初始化结果,模型还是可以训练
SimSam
孪生网络
两个编码器结构一致,参数共享,其中一个做预测,一个做参照结果,相互可预测,相互的预测结果用以计算MSE loss (negative cosine similarity),梯度回传更新网络,其中做参照的一组不更新
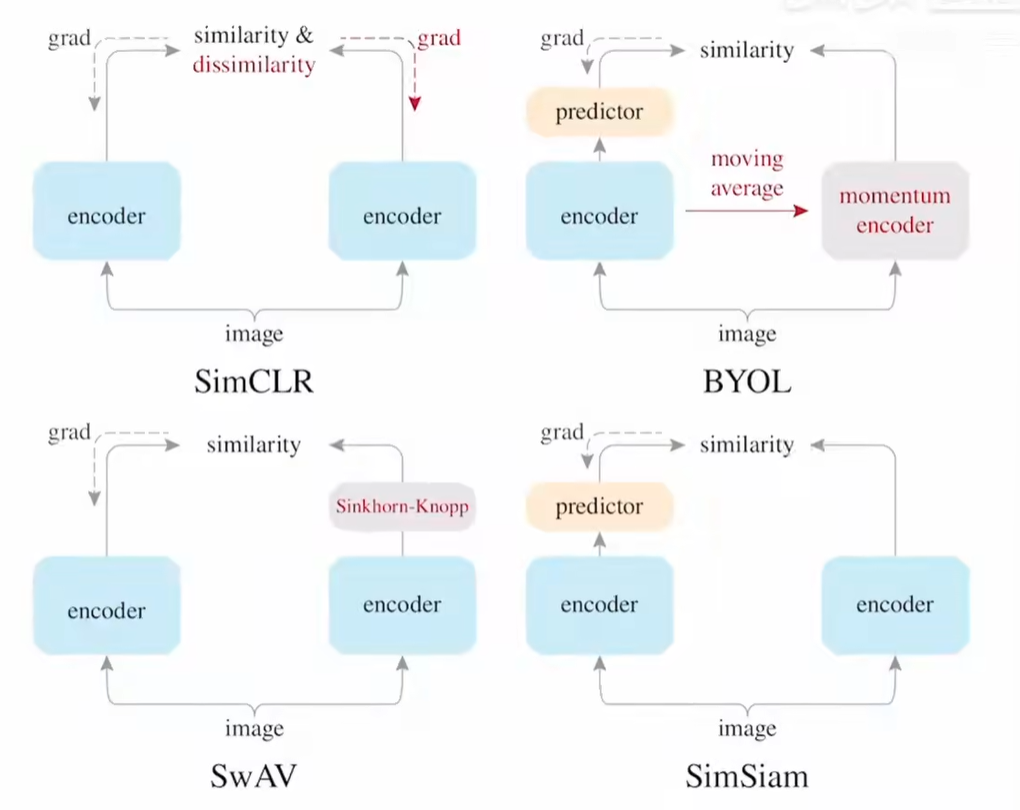
总结性工作,总结并分析了前面的几乎所有可用trick,并做了实验对比
MoCo v3
Vsion Transformer
几乎就是MoCo v2 和 SimSam的结合,encoder + proj mlp + pred mlp,使用动量编码器和温度参数等操作
在此基础上,希望采用Transformer架构替换卷积层,于是采用ViT(vision bert),发现存在精度骤降问题
通过冻结patch projection(详见Vision Transformer),解决了问题,得到平滑的训练曲线
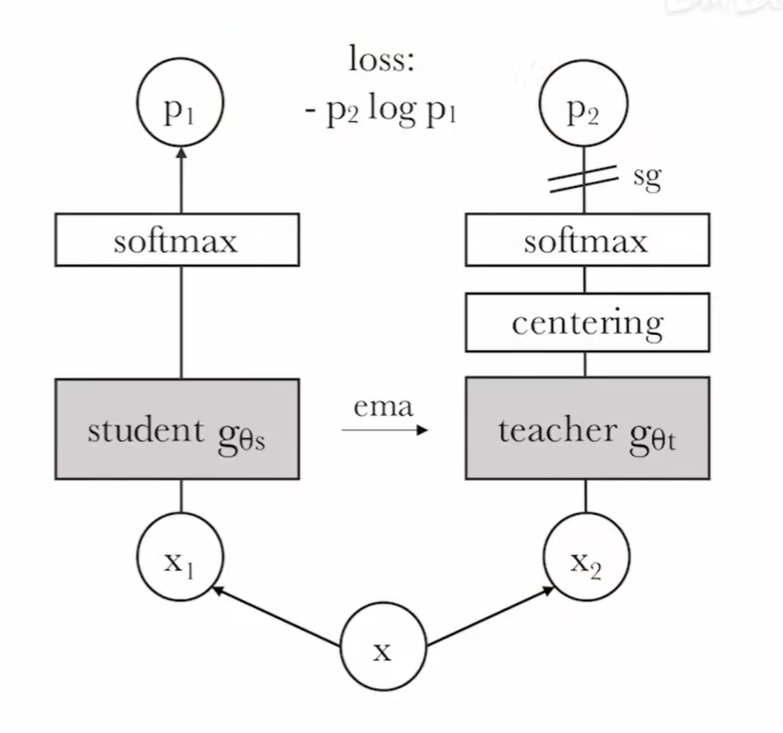
Dino
自蒸馏
自己和自己做知识蒸馏,实际上和BYOL相似
增加了centering操作,实际上也像BatchNorm操作,取了样本均值参与生成特征