Abstract
最大的发现是小的卷积核可以将深度推到16-19,并取得十分良好的效果
Key Issue
卷积方法深得人心,已有不少改进:
- 更小的感受野和stride
- 尽可能多的图片和尺度
但未对深度有更多尝试,本文尝试从深度角度入手,证明更深的模型的可能性。
Method
深度是网络性能的关键
本论文固定卷积核设置等参数,不断加深网络深度,并达到十分显著的效果。
具体来看:
- 固定卷积核3 * 3
- 两层接一个池化层
- 全连接层缩减通道并softmax分类
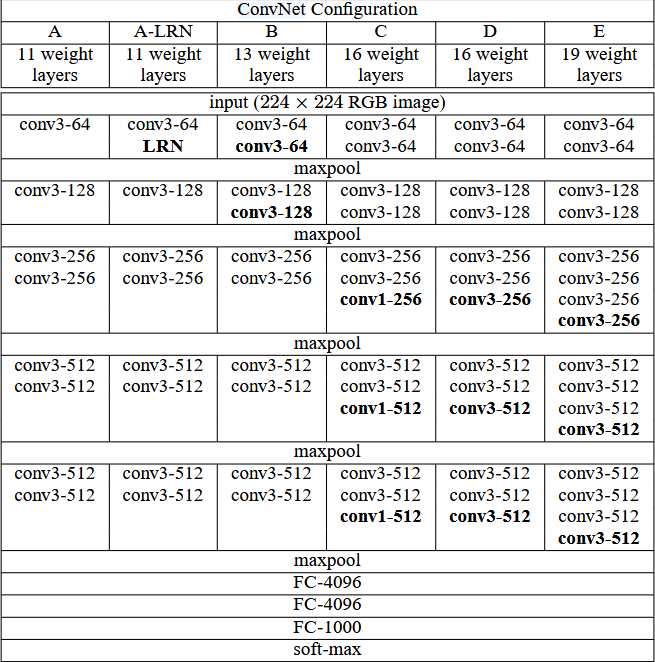
Training
- 学习率初始化0.01,以十倍虽验证精度变化
- 预初始化参数,预训练简单模型并用其初始化其他模型,减少训练时间、提高收敛速度
- 水平翻转,随机颜色偏移,图片缩放(有两种方式,多尺度和单尺度)
Testing
- 密集预测(dense ConvNet evaluation), 全连接层替换成卷积,生成预测图,即1000通道的特征图,每一个像素的各个通道代表了对应类别的概率值,并平均池化,得到的是和全连接层的输出维度一致的分类向量,作为整体图像的预测结果
- 多重裁剪(mluti-crop),多次裁剪预测取均值,追求更高精度,属于集成测试
Why it works
小卷积核
- 小的卷积核可能有隐式正则化的作用,相比同样感受野的大卷积核,小卷积核和更深的网络有更好的效果,多层卷积提供更多次非线性的特征提取,强迫大的感受野分解成多次学习
- 更小的参数量和计算量,促成了参数的正则化
更深的网络 文章最大的点就在于证明了深度是有效的,更深的网络确实达到了更好的效果,主观来看,文中提出的小卷积核策略提供的正则化可能减轻了网络加深所遇到的梯度问题,促成了更深模型的构建
优秀的处理策略 作为比赛模型,各种集成策略、初始化策略、增强策略等是文章最终结果的助力
Conclusion
文章提出使用小的卷积核来构建深度网络,证明了深度的有效性,这种模型在分类任务上精度显著增强,其泛化性也足够支持其运用在更多的任务和数据集上
在当时使用了预训练来初始化权重,但作者后来发现实际上不需要依靠与训练,而可以通过一种合理的初始化方法来一定程度避免梯度问题,这说明确实是深度有效,而不只是其策略的作用
Refer
代码实现(参考):VGG16-pytorch implementation
Com
为什么的卷积可以代替的卷积
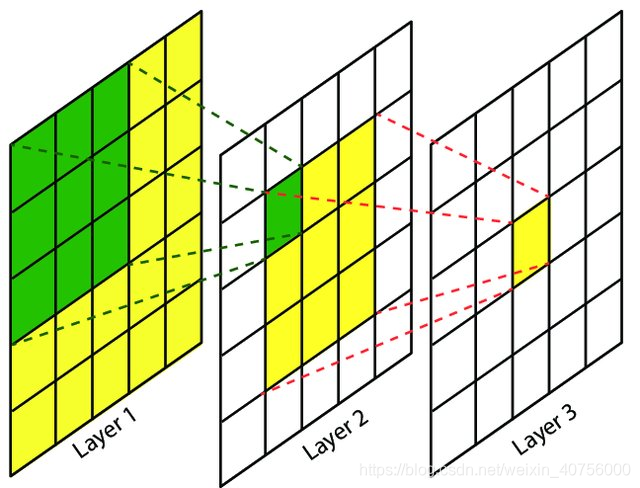
如图其实就可以说明,layer3的感受野即两层卷积核的感受野,也可以是一层卷积的感受野,layer2是单层卷积核的感受野
两层的卷积实际的感受野是第一个卷积核遍历得到的特征图时扫过的像素个数,第一个卷积要能得到的特征图,在步长为1的情况下,要遍历大小的像素,这与单独的一个的卷积感受野相当
感受野计算公式见下方
隐式正则化
论文里提到:“This can be seen as imposing a regularisation on the 7 × 7 conv. filters, forcing them to have a decomposition through the 3 × 3 filters (with non-linearity injected in between).”
将大卷积拆分成小的卷积,也就将原本一次的特征提取变成多次,原本一次的非线性变换过程变成多次,将原本的参数量计算 即 ,可以视为一次正则化
感受野计算
其中:
- 是第i层的卷积核大小
- 是从输入层到第i层的步长乘积
参数量计算
VGG中:
特别的:对于全连接层,可以看成是目标通道数的1 * 1个卷积来计算参数量
严谨来说,stride为1时:
其中:
- 是输出通道数
- 是输入通道数
- 是卷积核的宽,高
- 1是bias
其中,BN之后bias可以去掉
计算量则是:
其中:
- 是输出图的尺度
计算量一般忽略偏置项