Abstract
论文基于神经元关联的原则、多尺度学习,提出一种保持计算量、有效利用内部计算资源的的更深的模型
Motivation
越来越多卷积方法不再依赖于更大的数据,更好的设备等,而是算法自身的效率
提升网络性能的方法最直接的就是增加模型的深度和宽度,但这需要更多的参数,同时需要更大的数据集来避免过拟合
本文的着眼点在:
- 之前方法在解决上述问题中,提出将全连接或卷积的密集连接改成稀疏连接,有文献表明,分析激活值的统计特征和高相关性输出进行聚类可以逐层构建出一个最优的网络,同时这满足Hebbian principle(一个神经元如果和另一个神经元几乎同时激活,其连接就得到加强)
- 但是现在计算机设备对稀疏结构的运算能力很差,早期使用的随机稀疏连接打破了网络的对称性、提高学习能力,但于此同时没有计算效率差,有些方法重新使用全连接层,就是为了更好的优化和运算
- 那有没有一种方法,可以达到稀疏,又能利用到密集计算的特性?有文献表明可以通过聚类方法来得到更加密集的子矩阵来提高计算性能
Method
思路:
- 可以从Hebbian principle(一个神经元如果和另一个神经元几乎同时激活,其连接就得到加强)出发,认为可以将卷积中的密集连接改为稀疏连接,对相关联的神经元做聚类,减少这个类簇与下一层之间的连接,即保证了特征的学习,去除部分冗余,还能保证计算量的减少
- 多尺度特征的学习,在上述的实现之后,局部来看:神经元比较集中,需要小尺度的卷积核来总结学习;整体来看:神经元的簇之间比较离散,需要大的卷积核来学习整合
提出Inception这种结构实现:
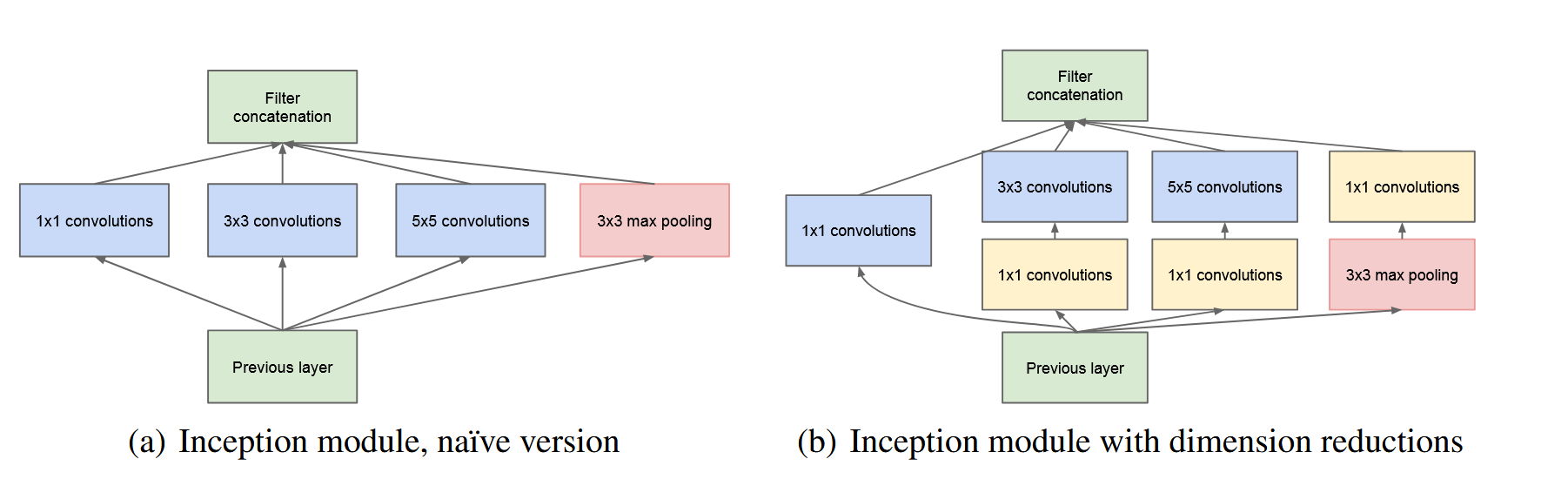
其中:
- 池化层目的是提供更多样的特征
- 卷积核的设置是为了方便对齐,只要步长都是1,padding分别是0、1、2,则可以得到相同维度的特征图,可以有效拼接
- 越到后面,特征越抽象,需要更大的感受野,也就是需要更大的卷积核,3卷积和5卷积的比例就要增加
- 其中右者是一种参数量优化,目的是通过1卷积来降维,减少通道数,同时引入更多非线性激活
Model
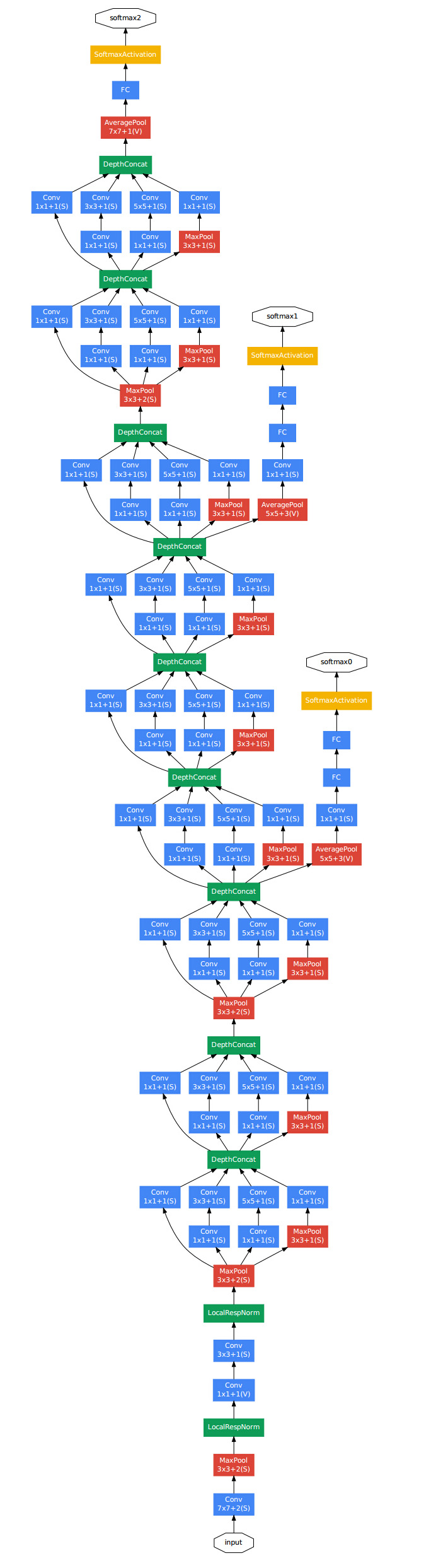
为了缓解梯度消失:中间层级其实就可以得到判别性强的特征,提出在中间增设分类层,增加损失函数,已提供新的梯度流,这按理说需要一个衰减系数(惩罚系数?)
Strategy
- Asynchronous Stochastic Gradient Descent
- 异步随机梯度下降,收到梯度就更新,但是不稳定
- Polyak Averaging
- 最终参数做平均,因为参数可能在最优解附近游荡,取平均期望能得到最好的结果
- Photometric Distortions
- 对比度增强等等
Conclusion
这篇论文提出现成的密集构建块结构近似最优的稀疏结构是一种可行的改进方法,可以提高性能又不大量增加计算量
Inception的创新相比VGG似乎更有原理可依,模型结构合理但相比更复杂,卷积核和池化层的设置没有明确的依据,可能是为了特征拼接的方便并在实验结果中证明有效
Refer
【代码实现】GoogLeNet (Inception) from scratch using Pytorch💪
【笔记参考】GoogLeNet系列解读-CSDN博客