强化学习
概念
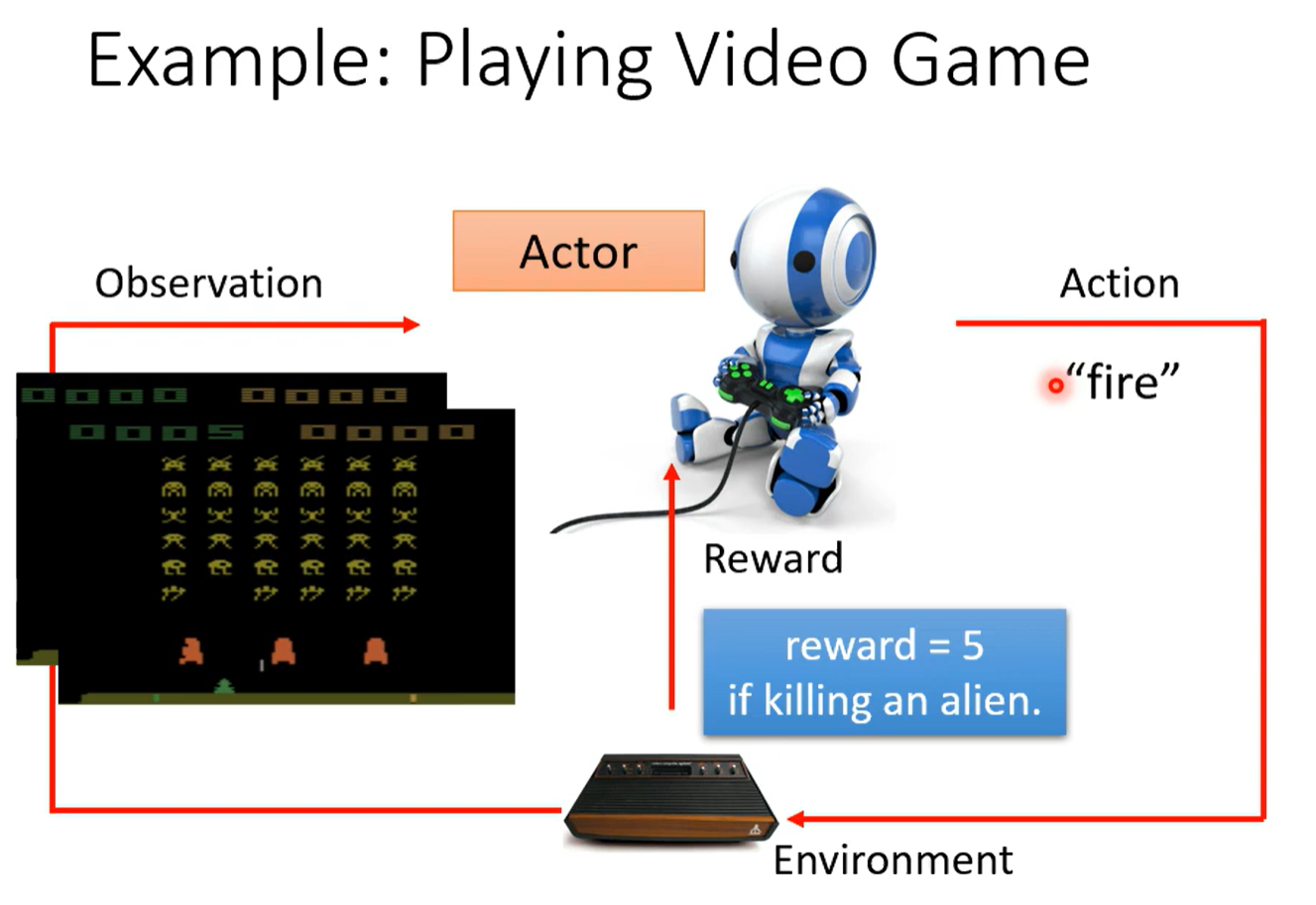
当不知道如何标注,如何获取数据时,可以使用强化学习
强化学习实现的是,找一个function,这个function接收环境的输入输出一个Action,一个Action给出一个Reward,期望所有行动Reward值之和Return最大
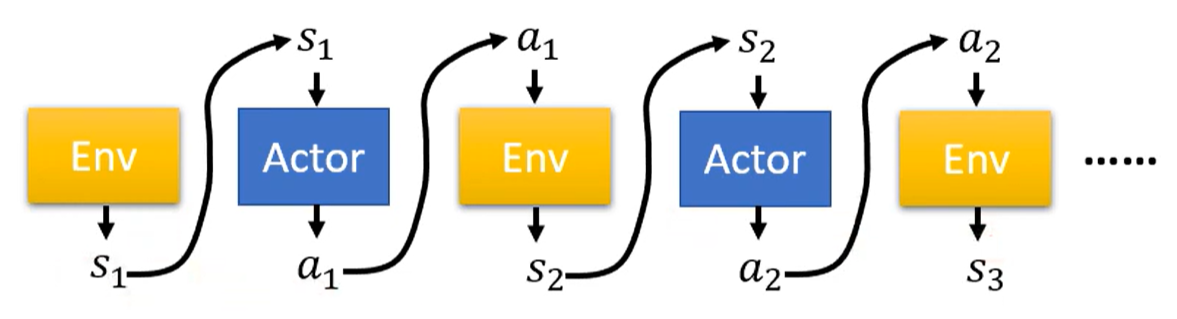
Step 实际上与机器学习无异
-
Function with Unkown 实际上就是Actor,做出下一步行动
复杂函数即神经网络,其输出为Action的得分结果,根据得分结果做权重取样采取行动
-
Difine Loss 从定义的游戏开始到结束的过程称为episode,Actor在每一步里都得到Reward,这个Reward之和就是训练的loss,要求其负值结果越大越好
-
Optimization Trajectory action与环境相互互动形成的行动序列
Reward接收环境和行动,输出一个Reward作为回应,目标是优化最大Return
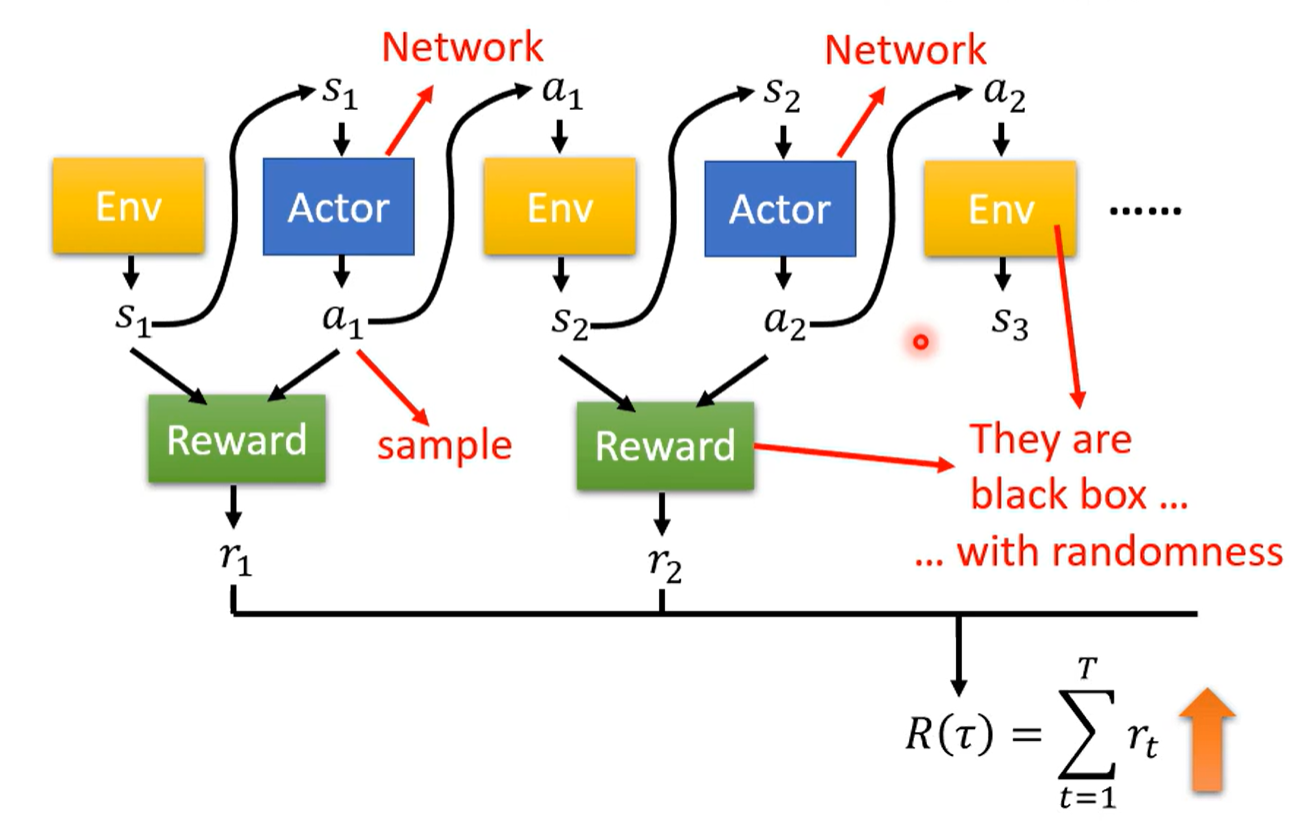
此时整个网络的输出与输入是由随机性的,环境的变化随机,行动的选择随机,导致同样的参数每次的输出结果可能不同,Loss不存在一个可导的函数表示,无法用简单的梯度下降做优化
Policy Gradient
Control actor
Classification
控制actor其实是网络参数优化问题,由于行动的类别是固定的,可以直接用行动给网络做分类
希望分类结果是预期结果,则使用预期结果与网络输出计算损失,用这个loss函数来优化参数,就可以控制actor
如果是不希望是某个行动,就用这个行动来定义负的loss,用负的loss优化网络
用诸如此类的损失叠加起来,就是控制Actor所有可能行动的Loss
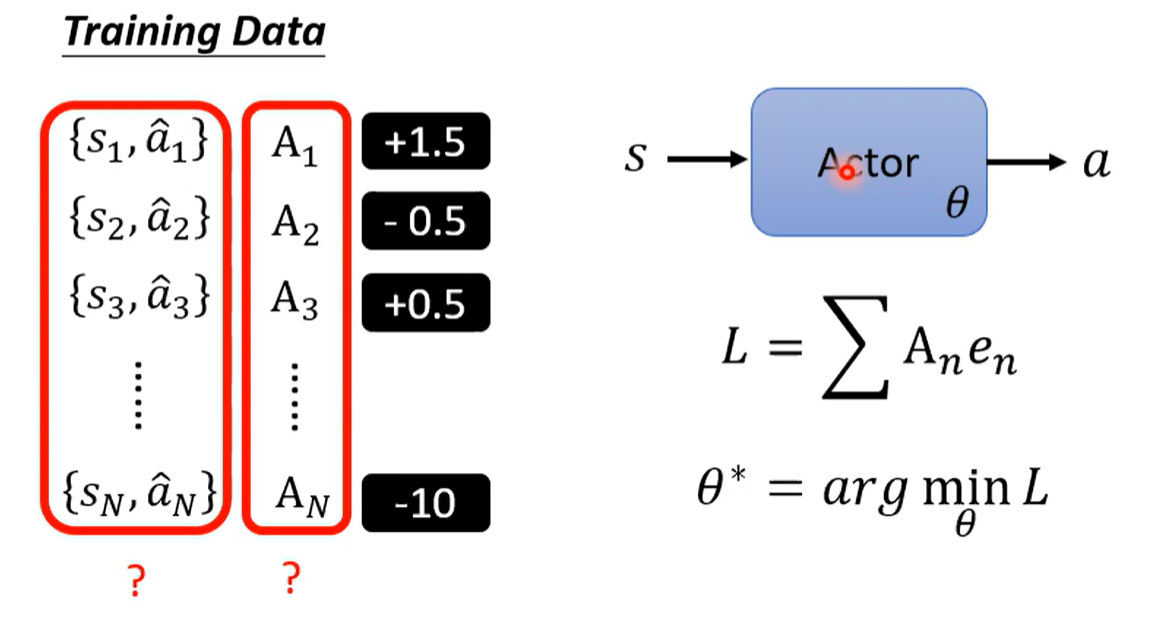
实际上与监督学习训练分类器的过程一致,问题是如何产生训练资料?
Traing Data
要得到训练的数据需要有一个初始的Actor,Actor与环境互动,得到每个环境对应的行动下Reward的大小,依据这个Reward的大小就可以定出某个环境所期望采取的行动
确定预期行动需要考虑:
- 行动产生的Reward
- Reward delay 有时候当前Reward最大并不会使全局Reward最大,需要考虑暂时选择Reward小的行为取换取最大的Reward
也就是行动的A,其实应该考虑所有执行该action行为之后引发的变化
Cumulated reward 将序列中执行该action之后,后续所有的Reward加和作为A的数值,代表在S1环境下执行行动a1使得actor得到的后续结果
直接加和并不一定合理,一段时间之后的行为不一定受当前行为的影响,考虑加权
Discount factor 定义一个权数 ,对第 i 个时间步之后的Reward乘上 作为权重,称为Discounted cumulated reward
即定义最终的A计算函数G
标准化 存在一些场景,这些场景下G可能有正有负,也可能都是整数,那尽管G的值相比其他的是属于差的一方,只要是正的就还是鼓励其去进行,这样不利于模型训练,提出减去baseline的方法,将G值缩减到有正有负
Update
关键在于前一个状态下的操作并不能用作当前状态操作的参考
在上述数据获取过程中,其实是通过在每一个状态进行尝试,尝试一个episode之后将得到的数据来训练这个状态得到下一个状态
此时一组数据只能用于产生这组数据的状态,要多次训练就需要在每个状态下获取数据
这种训练模式称为On-policy,即得到训练数据的actor和被训练的actor是同一个,反之称为Off-policy
使用Off-policy方法需要知道actor之间的差距,在差距存在的情况下进行训练;这种方法不需要每次对数据进行收集,常见的有Proximal Policy Optimization (PPO)
Exploration
随机性
训练需要一些随机性,在一定随机性下,一些从没尝试过的行为才会被尝试
Actor Critic
Actor的评价器,在接收到环境(或者包括Actor的行动)后,评价Actor能得到多少Reward
实际上就是一个评价函数,接收s为输入,经过 输出能够获得的discounted cumulated reward
Method
计算V的方法
-
Monte-Carlo(MC) 蒙特卡洛算法
让actor与环境互动,一直互动到结束,获得训练V的数据,通过这些数据来训练V
-
Temporal-difference(TD) 时序差分算法
………… 依据这样的序列作为训练的数据
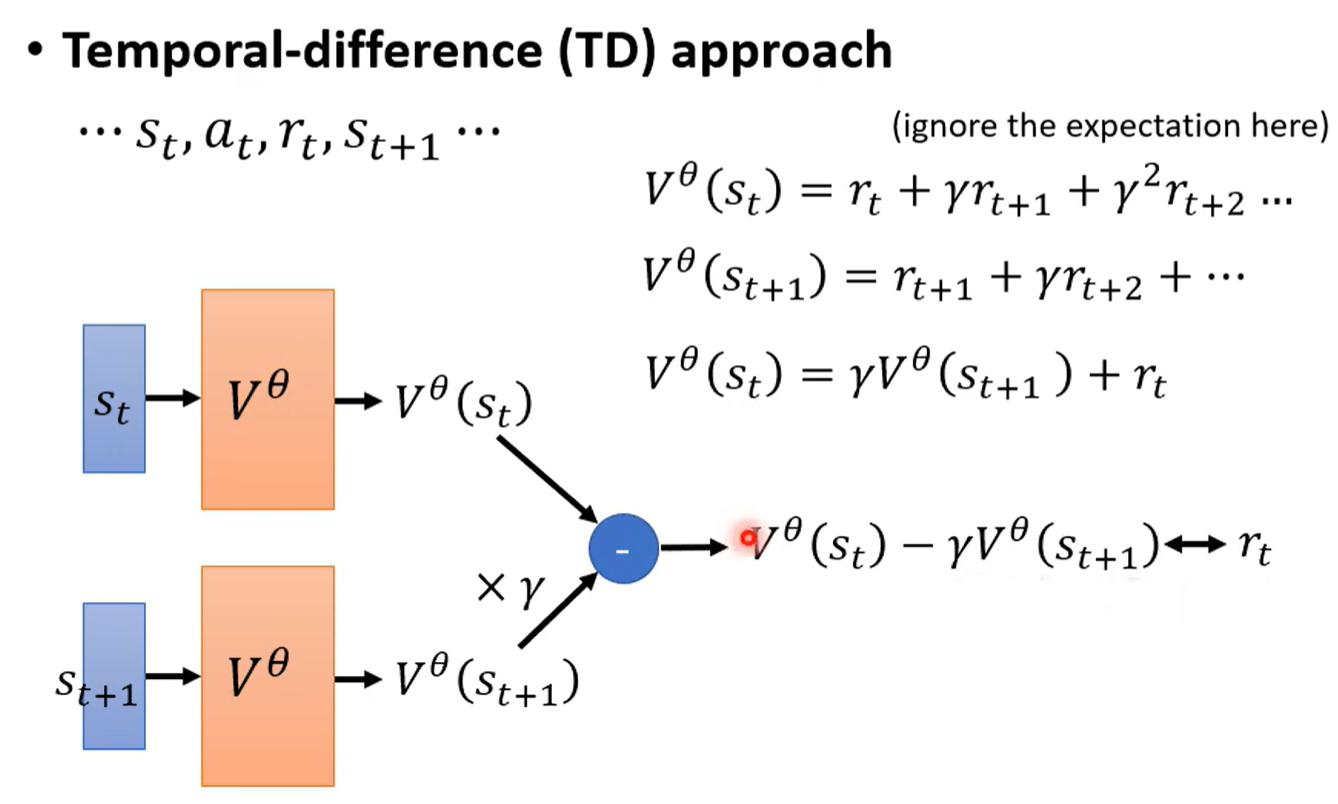
相邻时间得到的return是相关的,其应满足,能够以此进行训练
Advantage Actor-Critic
上文提及到A的计算需要减去baseline做标准化
可以选择V在该环境下的值作为baseline,即
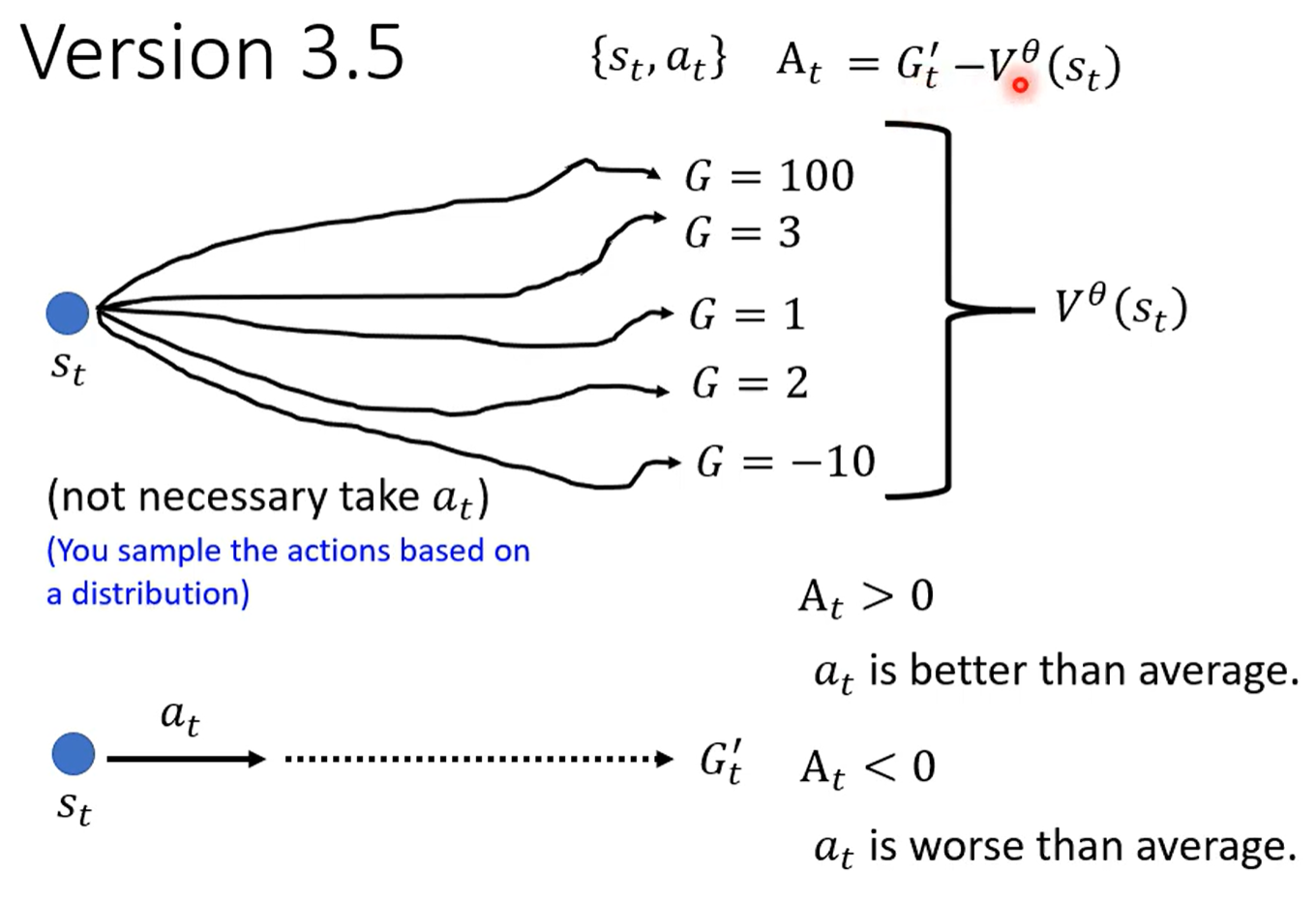
含义是 作为在该环境中一个确定随机性下所有可能性计算得到的return值; 作为采取采取 这个行动后后续一系列确定行动获得的return
也就是G是V考虑的多种可能性其中一种,以V作为衡量,如果采取当前行动之后,后续actor做出的可能性得到的值 超过 考虑所有可能的平均值,那么当前action是正的,否则是负的
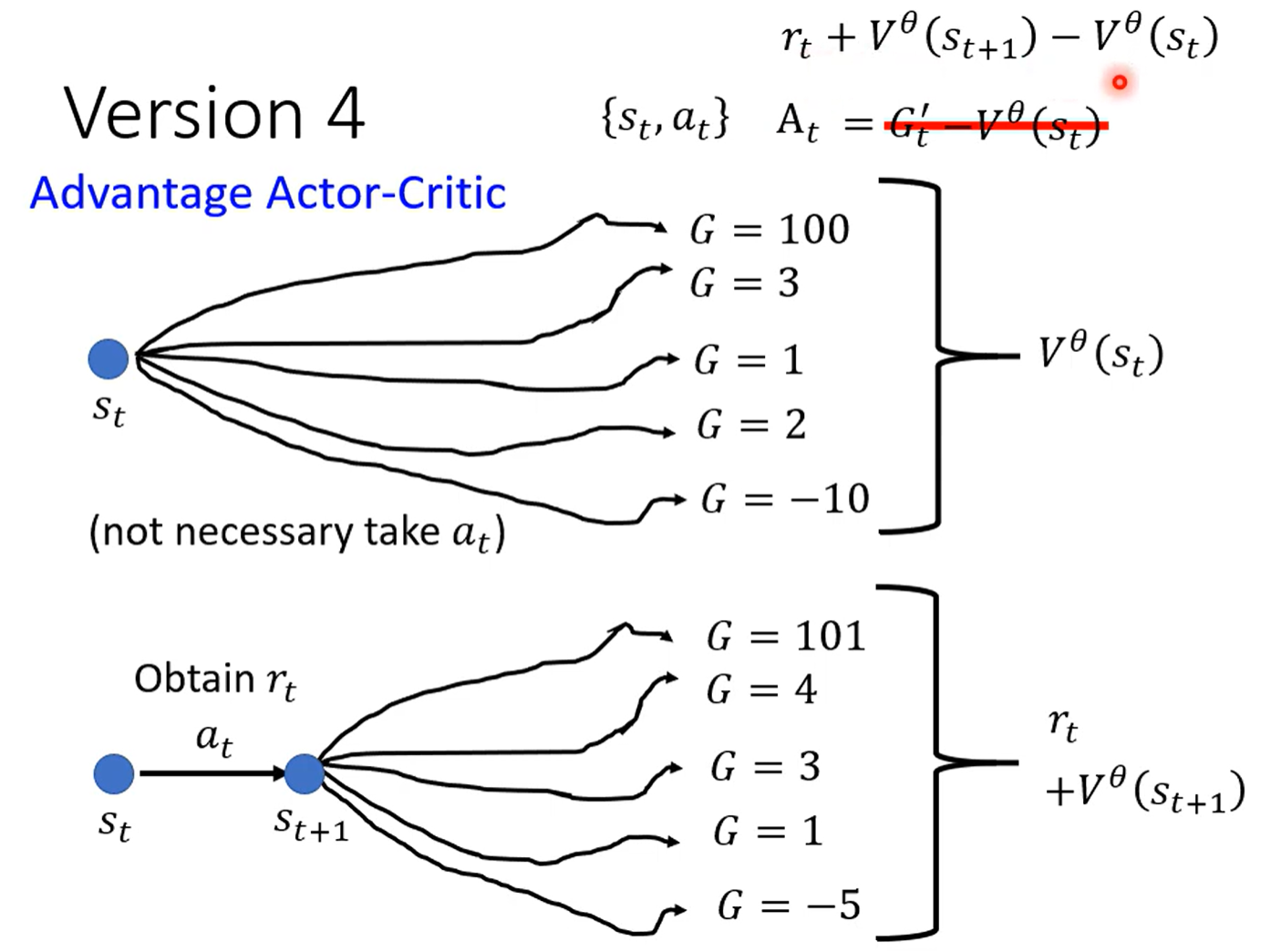
但是这样其实有不妥,因为是用一种后续可能的sample来衡量当前的行动
应该用后续所有可能情况来衡量,即用后续所有可能的情况下得到的平均值与当前所有可能情况下得到的平均值相减,得到的值与当前获得的reward比较,如果当前reward大,说明action是合理的,否则不合理
Tips
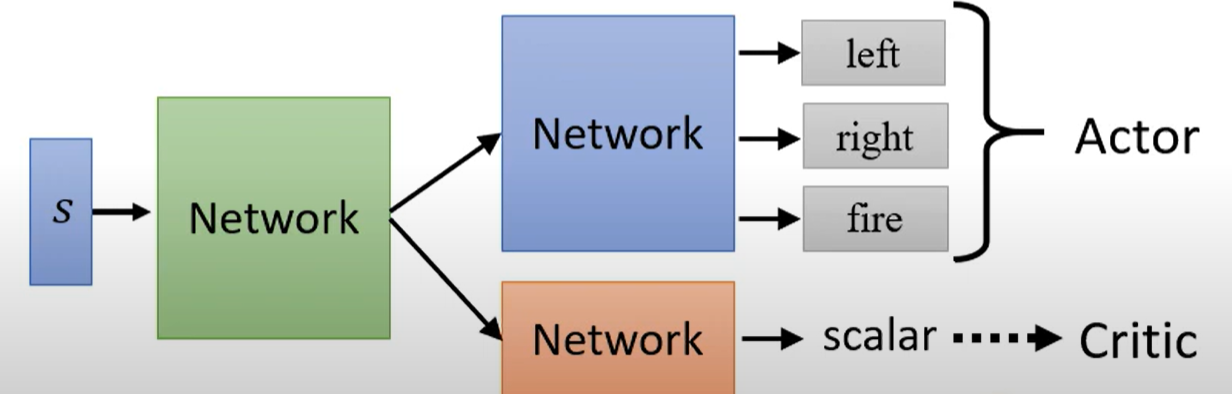
与actor的Network参数共享
Reward Shaping
Sparse Reward
有些任务Reward分散,行动不一定能得到Reward,只有在任务结束或某些特定条件下才有Reward,这样的Reward称为Sparse Reward
这个时候就需要额外提供一些Reward来指导Agent学习,这就称为Reward Shaping
Reward Shaping 依赖于人对环境的理解,对Agent行为的需求
Curiosity
好奇心学习
通过让Agent不断尝试学习新信息,看到新东西的方式让Agent学习
这种新东西需要具备意义,而不是无意义的噪音
参考:ICML2017
No Reward
在没有Reward的环境下尽管可以人为的制定Reward,但是这种Reward并非是完全合理的,No Reward learning主要是在没有显而易见的Reward情况下,让Agent学习到一些不需要人定义的合理的事情
Imitation Learning
模仿学习
为Agent提供expert的示范,例如人的示范,视频,或者人先操控Agent做示范
Behavior Cloning 直接复制示范的行为,在示范样例下,已经有环境与对应的行为,可以当作supervised learning训练。但是只是复制行为存在一些问题:
- 没见过的情形
- 完全模仿
- 能力有限
Inverse Reinforcement Learning
从expert的行为逆推Reward Function,再用Reward Function训练一个optimal actor
Teacher is always the best 以expert的行为为最佳的行为,即获得的Reward最大
- 通过模仿expert的行为获得一系列action与reward
- 以expert行为最佳的标准,定义Reward Function
- 依据Function训练一个Actor
- 依据Actor获得新的一系列action与reward
- 再依据expert行为最佳标准更新Reward Function