Why deep
深度与宽度
为什么用深度而不是宽度
- 更精确
- 效率更高(参数少,训练数据少,不容易过拟合)
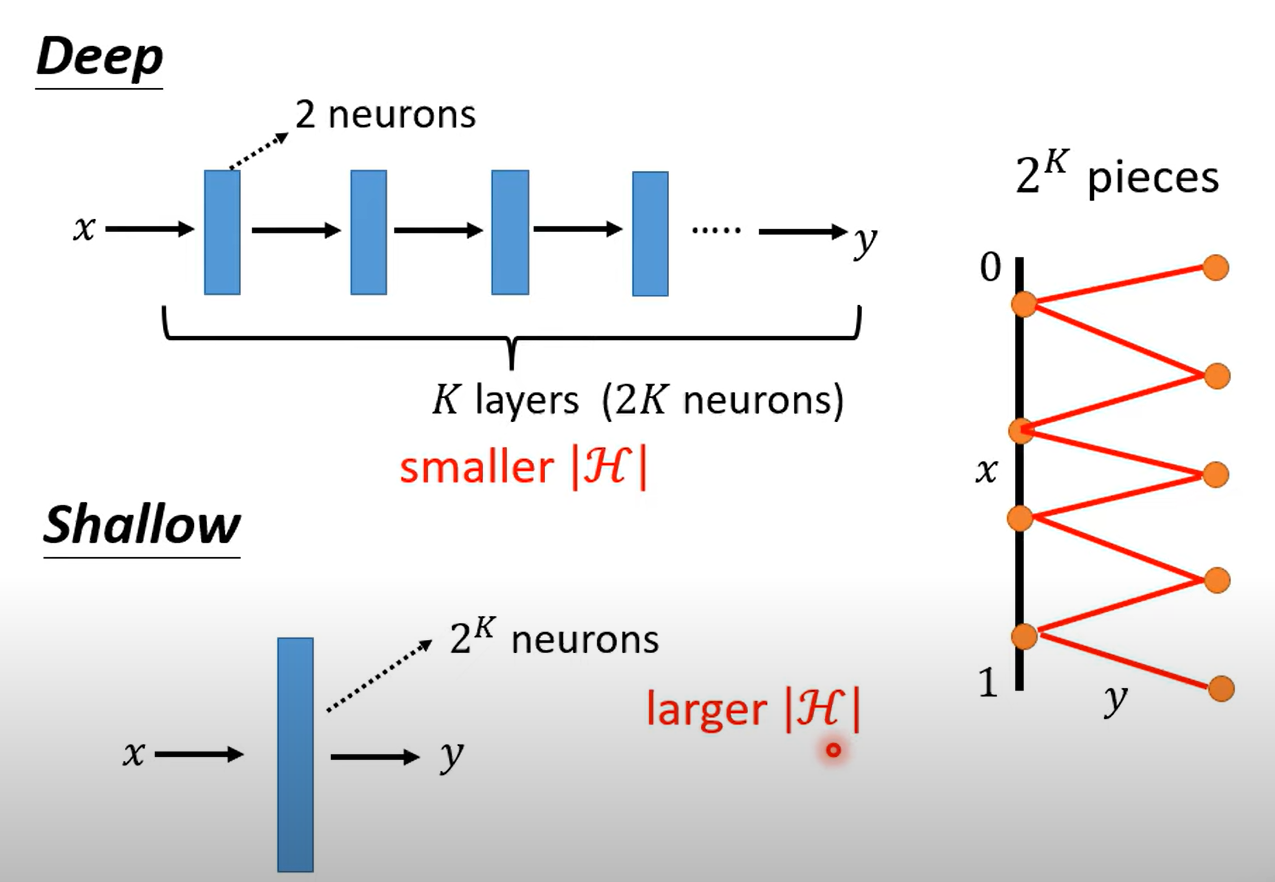
深度学习模型在隐藏层构造复杂函数的是指数级别变化的,在很少的隐藏层与神经元下就可以构建出复杂的函数
而只有一层(shallow)则需要大量的神经元来实现
也就是在复杂函数(也不一定很复杂,一般是有规律的函数)深度学习所需的参数量,数据量会少于shallow的学习
CNN
Convolutional Neural Network
处理图片,实际上将图片转化为三维张量(tensor)【高,宽,channels】的像素值(pixel)组成的
将这些像素值拉直为一维向量,可以作为模型的输入
在全连接层(每个特征值都和每个神经元有连接)的意义下,直接输入一维的向量会有如下问题:
- 参数过多,弹性大,容易过拟合
- 实际意义可以理解为全部特征都进行计算,但是其实人认知一个图象是从局部的特征进行理解的,并不需要全部的特征
感受野 receptive field
一个神经元并不需要观察全部的特征,或许给定一定范围的特征就可以了
定义一个神经元接收的特征的范围为 感受野
感受野可以重合,甚至重叠来对一个区域提取多次特征
感受野的范围可以各种各样,体现每个实际问题的需求
典型的情况下:
- 考虑全部的channels
- kernel size (高,宽)3x3,卷积核大小
- 每个感受野有多个神经元
- stride = 2,移动卷积核的步长
- Padding,补充图像面积,填充卷积核走到底出界部分,补均值或0等
参数共享 parameter sharing
一个类别物体的图片,其重要特征的位置可能不一样,例如猫的耳朵可能在图片的右上角,也可能在左下角
如果用具特定功能(例如检测耳朵)的神经元遍布整张图片显得有些冗余,所以提出参数共享
将不同感受野的神经元的参数进行共享,这样一来每一个神经元都可以实现检测特定特征的功能,由于感受野不一样,神经元之间的输入就不一样,输出不会相同,也就是参数共享不会影响模型的输出
典型情况下: 不同感受野的不同神经元对应着共享参数 这样的一个个(组组)神经元称为filter,或者说这些对感受野共用的参数就成为filter
pooling
pooling就是对图片做subsample,操作是固定的,没有参数一类的需要学习的数值
pooling的方式多种多样,经过一次pooling可以减小图片的大小但是不影响其主要特征
往往与convolution交替使用
主要是为了减少计算量
卷积层
使用感受野与参数共享的层称为卷积层(Convolutional Layer)
其模型的偏差较大,因为: 模型弹性小,因为感受野和参数共享限制了模型的复杂度
特定处理图像与类似结构的数据
具体怎么工作的呢?
- 卷积核(filter)具有一些未知的参数值,其大小为 3x3xchannels
- 覆盖在其感受野上,对数据tensor对应位置的数据做参数与数据的相乘运算,运算结果(一个值)作为新tensor的对应位置的数值,也就是特征提取
- 以一定的stride移动,再重复运算
- 不同的filter扫一遍得到不同的数值,全部扫过之后得到的矩阵称为feature map
- 新矩阵的channels就是filter的个数
- 对新矩阵再做卷积,实际上就是对提取到特征再做特征提取,也可以做到对初始图像的一个大的范围的特征提取
- 有需要就convolution后做一次pooling
- 最终Flatted后送进全连接层计算出分类值
CNN处理文字,语音,AlphaGo
缺陷: 无法处理影像的放大缩小,因为数值完全不一样了,一般情况下会将数据的图片放大缩小来实现预测
尺寸如何变化
参数说明:
H_in/W_in: 输入特征图的高度/宽度K: 卷积核尺寸(kernel size)P: 填充值(padding)S: 步长(stride)⌊ ⌋: 向下取整符号
池化层的计算与卷积层一致
参考文章:卷积层设置及输出大小计算 - 码我疯狂的码 - 博客园
同时,通道数与上述参数无关,和卷积层的过滤器数量有关,也就是卷积核的数量
Spatial Transformer Layer
CNN做不到变换图像的识别,对放大缩小的图片识别结果可能不同,其不具备这样的特性
可以训练一个Transformer layer,于CNN连接起来保持端对端的特性,但是将图片(或feature map)转化到CNN看过的形式,保证CNN的效果
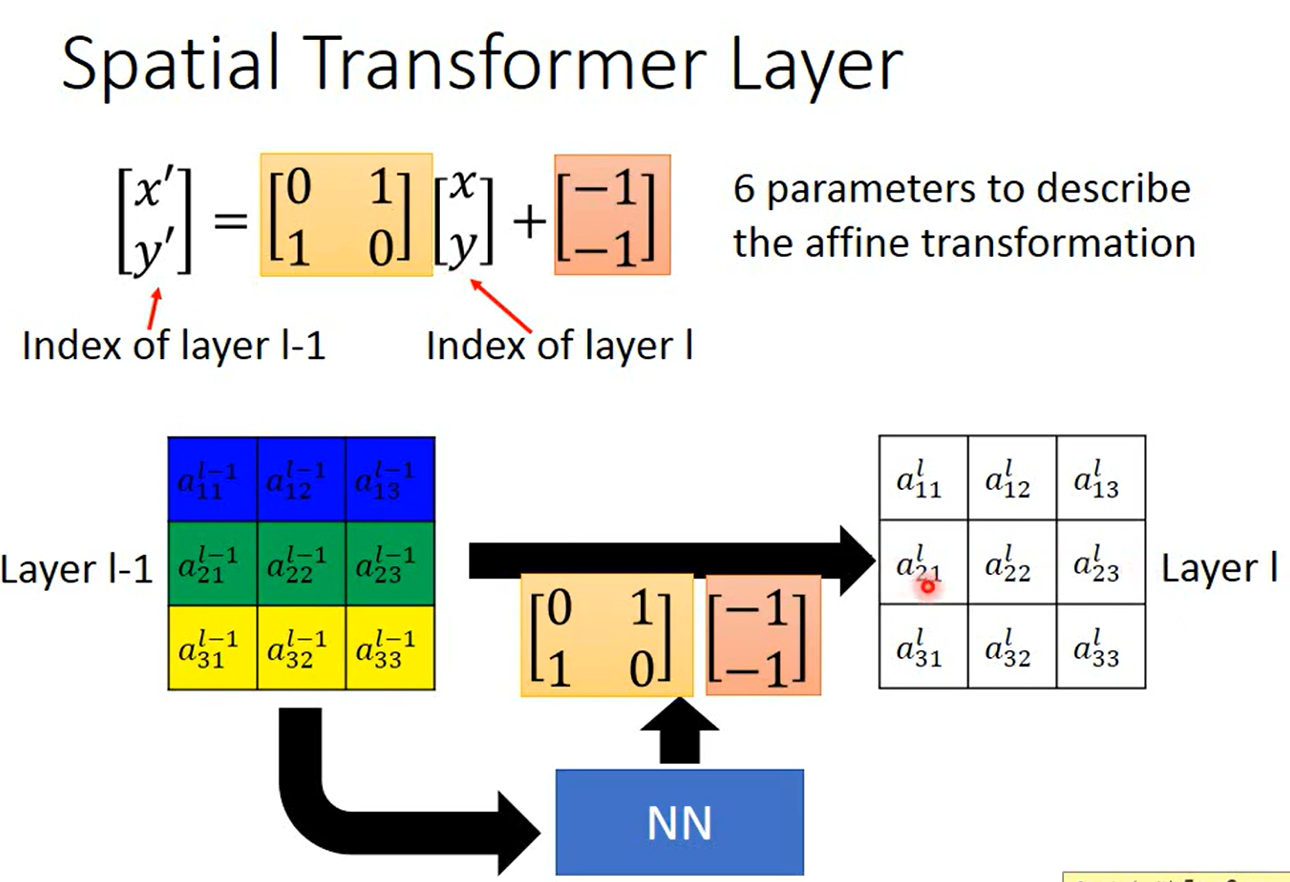
通过式子
含义为当前layer矩阵上一个位置的数值等于上一个layer矩阵各个位置值加权之和
可以通过控制这个方程实现平移、旋转等功能,这种变换称为 仿射(Affine)
将x轴和y轴区分,代表x轴和y轴组合的 元素,乘上加权的矩阵(旋转、缩放矩阵),再加上一个平移,做线性组合就可以实现平移与旋转功能
可以利用一个NN输出这六个参数,但是存在一个问题,如果出现小数无法计算,原本就是离散的数值,出现小数再微分的话可能存在微分结果为0的情况
所以对于小数的结果要使用 插值(Interpolation) ,用x,y与上下左右四个点的距离计算插值
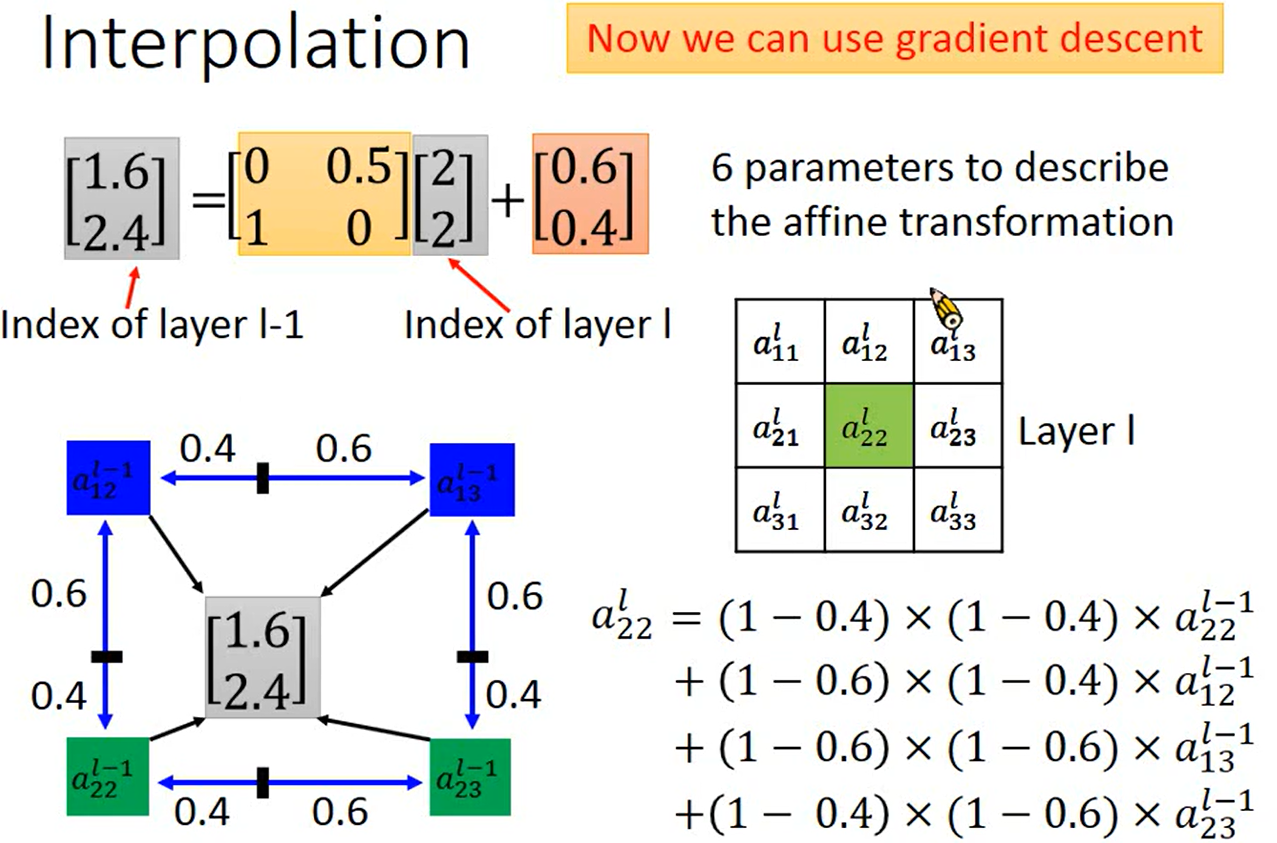
这样一来就可以做微分,因为数值插值之后变得连续
GNN
Graph Neural Networks 图神经网络
图神经网络实际上是处理图的神经网络,这里指的图并非是图片的图,而是图这种数据结构
可以应用在一些可能不会注意到的地方
- 化学分子
- 地图
- 蛋白质等
- 图生成(分子等)
Spatial-based Convolution
用与当前节点相邻的节点来更新当前节点,称为Aggregate
所有节点的特征集合起来代表整张图,称为Readout, 可以将这个值来作为分类或预测的基准
怎么做?
计算Aggregate
NN4G将相邻节点相加再做一次transform(乘上权重),再加上该点的输入x
DCNN第k次更新,将相邻k的节点(可以重复往回走,例如该点与自己的距离可以是2)相加求平均再乘上权重
GAT(Graph Attention Networks) 增加邻接点的权重设置,同时使用attention机制让模型自己学习权重
计算Readout
NN4G 各层的节点值相加取平均,再各自transform,相加得到 y
DCNN 将每层的每个节点的值拿出来组成一个矩阵,再将这些矩阵组成向量,进行一个transform后就是输出 y
Spectral Convolution
复变函数等等一堆东西没听懂 之后有需要再听一次
关键: localized 上述推出了一个g函数,输入是L(laplacian),为filter对每个点的信息进行过滤,但是出现提个问题,在多层模型中,过滤的效果会失去,更多层下L矩阵使得每个点的信息被计算到,这不合理,不满足localized
库: —Deep Graph library
RNN
Recurrent Neural Network
对一般的模型而言,同样的输入就有同样的输出,前后的不同的特征无法影响到当前特征的输出
但是对于语言等具有前后联系的输入来说这种前后联系的体现是至关重要的
RNN,Recurrent Neural Network 通过设置记忆力类似的机制实现前后联系的体现
机制
将中间层的输出存进memory来影响每次的输出,又回过来影响memory
这明显于输入的顺序有关,先输入不同的特征会影响memory的值
叠加多层后,每一层对应一个memory,每个memory在该层中变化,同时不同时间点对应的值在下次输入的同一层派上用场
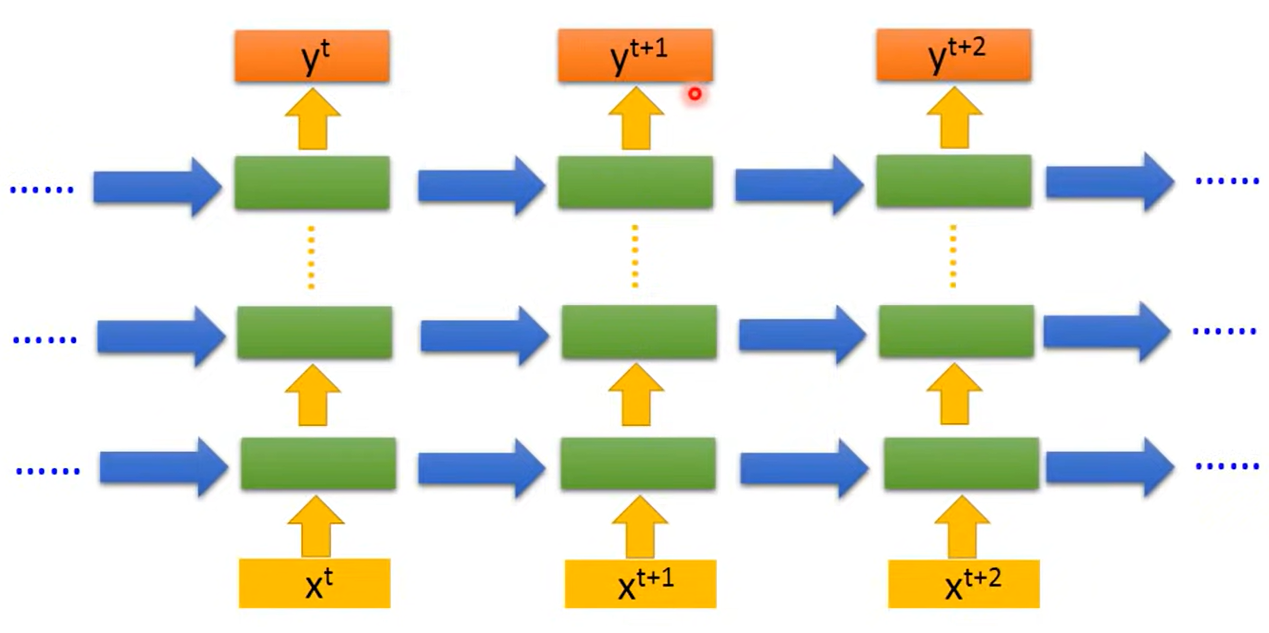
这种RNN结构称为Elman network
还有一种结构为Jordan Network 其将每层的输出作为memory给下一个时间点同一层使用
这种结构可以有较好的表现,因为memory的值被前一时间点的输出约束,在实际上更有意义
双向RNN bidirectional RNN 将输入逆向输给RNN,得到两种参数值,利用两个参数值同时对y做预测
Long Short-term Memory(LSTM)
长的 短期记忆力机制
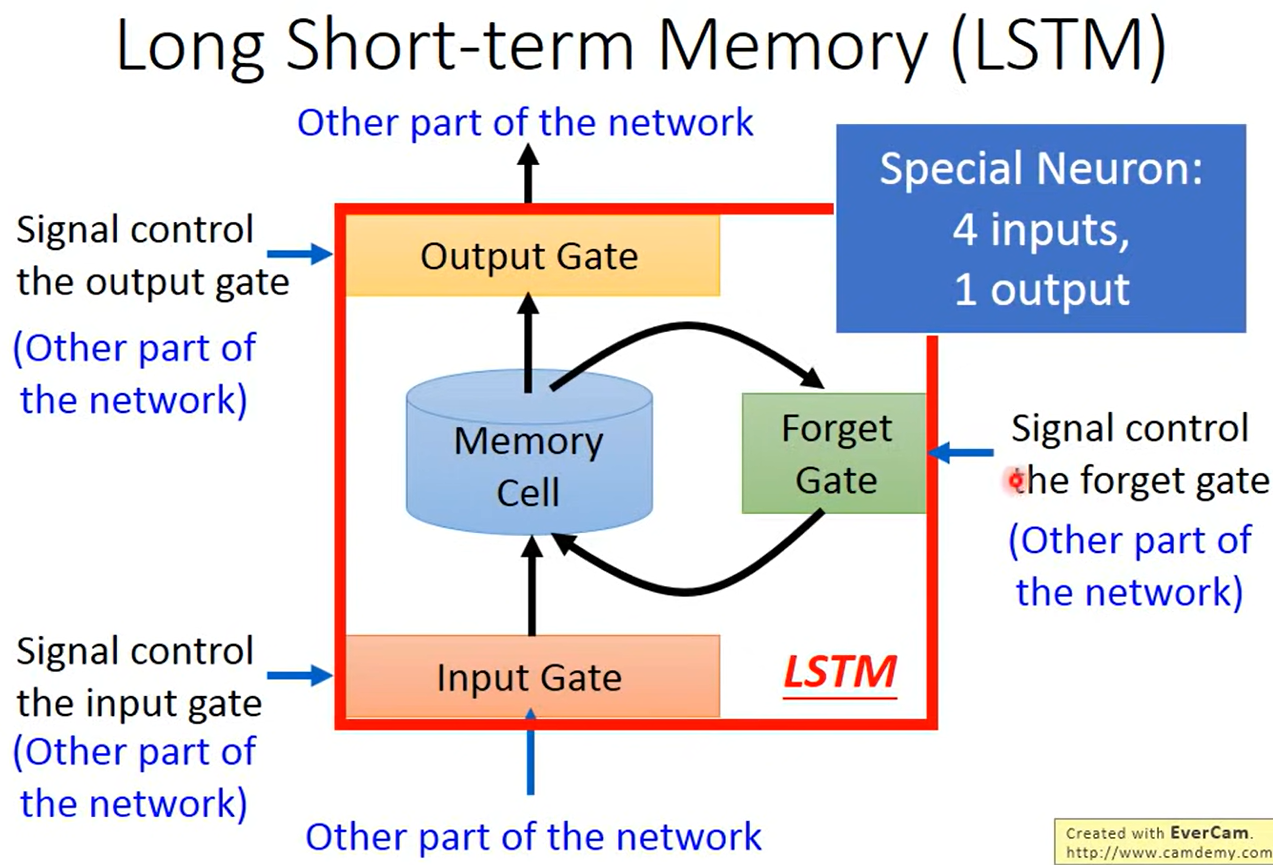
- 输入门 决定哪些参特征可以输入
- 输出门 决定哪些特征可以读出这个记忆
- 遗忘门 决定哪些可以遗忘
这些门的开闭参数,权重参数等都是在训练中学习的
普通的RNN,每次有新的输入都会更新之前的Memory,会有梯度消失(gradient vanishing)等问题 long short-term则对更新进行一定的筛选,达到更好的效果
具体机制
- 输入x,通过激活函数
- 输入门控制参数经过激活函数判断门的开闭程度,对输入做筛选
- 两者相乘
- 同时遗忘门激活后判断当前存储的内容的遗忘程度,相乘遗忘掉一些东西
- 遗忘后的存储,与新进来的输入相加称为新的memory
- 输出门同样进行计算,衡量输出的程度
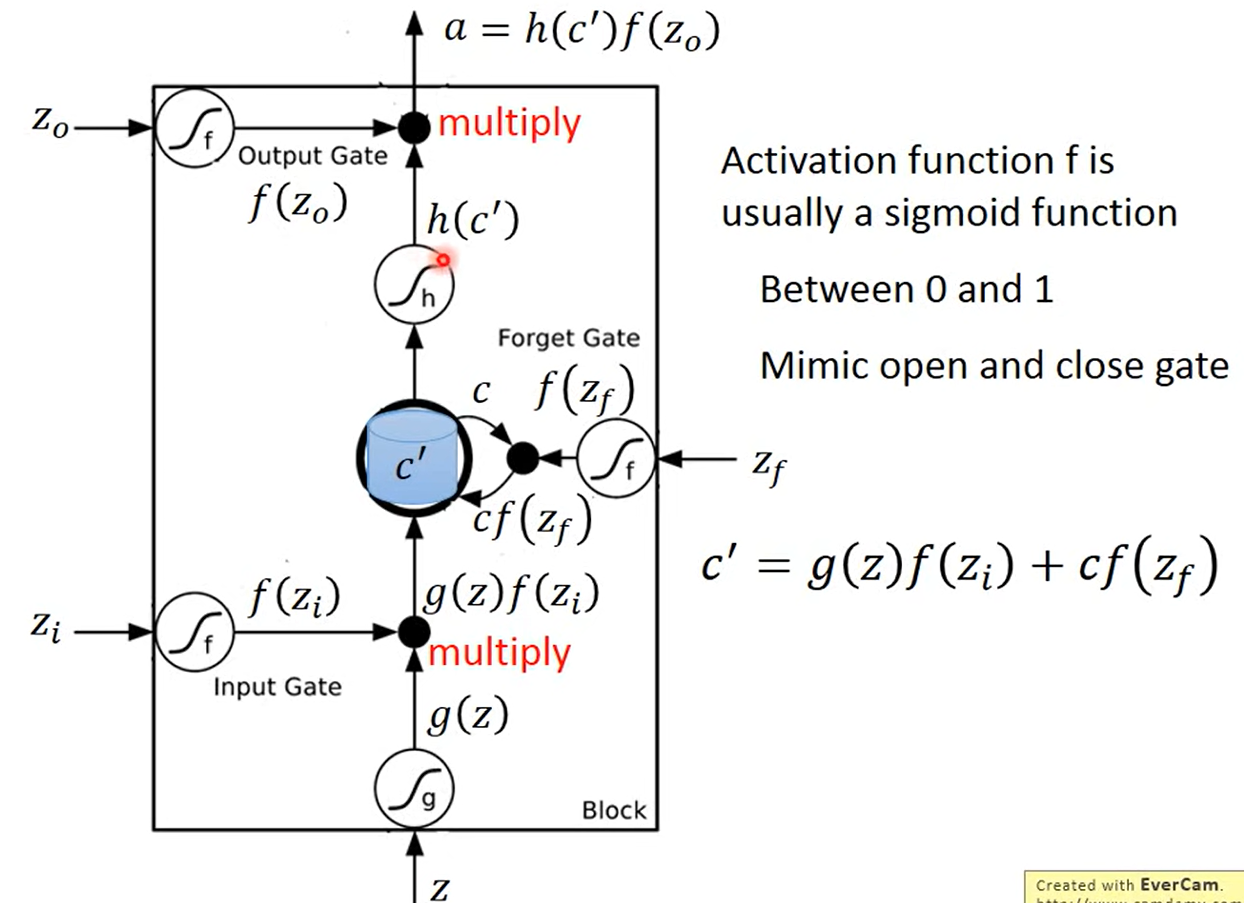
激活函数一般选用sigmoid,因为其输出的绝对值在(0,1)之间
实际实现时,这一个时间点的输入不只是这个时间点对应的x,还有上个时间点计算出来的输出
实际训练
首先假设进行词性分类
RNN也是使用梯度下降法进行训练的,但是不同于一般的反向传播,RNN使用的是进阶的Backpropagation through time(BPTT) 其适用于时间序列的梯度下降
实际上在早期RNN训练的时候存在一个问题:损失函数震荡剧烈

为什么?RNN的结构中每一个时间点的memory都参与运算,其在当前时间点的运算结果作为memory的更新给下一时间点的同一层使用,而且计算时做的是乘法操作
如果时间很长,那么其参数w会参与很多次乘法,变化是指数级别的,这就存在了上图中存在的问题——梯度变化明显,而且不确定
使用LSTM
实际上解决上述问题的一个方法是解决梯度消失,因为这种变化中存在一些地方梯度变化不明显
LSTM有筛选的记忆与遗忘,可以将一些特征较为长期的保存(每次更新为加法),而不是RNN一样直接替换掉memory
GRU
LSTM的简化版,只有两个门,参数少,鲁棒性强,过拟合概率低
将input gate 和 forget gate 联动,一起开启
RNN应用
-
sentiment analysis 情感分析
-
key term extration 关键事件提取
-
CTC(input 长,output 短) 语音识别
实际上每个特征都是很短的语音序列,这样在很短的时间内就算辨识出每个序列对应的文字,文字也会重复出现在好几个序列
可以增加null作为标签替换被多次辨识的字段,把所有可能的分配结果作为正确的标签输给模型让模型学习
这样一来模型可以学习到词汇的信息,甚至可能识别出没有学习过的词汇
-
Sequence to Sequence 输入输出的长短不知,例如机器翻译
增加一个终止的标记,作为可能的输出,当输出该标记,输出就终止
实际上效果不错
-
Audio Segment vector 将声音讯号划分成一段一段的时间序列向量,不需要做语音对文字的识别,就可以利用这段声音的讯号做出例如翻译、相关内容搜索等预测
encoder与decoder
将声音讯号输入RNN进行训练,最后保存在memory的值就代表了这段声音的信息,作为Encoder
再训练一个Decoder,将memory的值作为输入训练,希望输出值与输入尽可能接近
RNN vs Structured Learning
RNN
- 不一定考虑整个序列
- 损失函数不一定与误差有相关性
- 可以进行深度学习
HMM,CRF,Strutured Perceptron/SVM
- 考虑整个序列
- 可以简单的增加所需约束条件
- 损失函数是误差的上限
- 难以deep
实际上却是可以deep的RNN效果会更好
可以结合 将RNN的输出作为Structured的输入
Self-Attention
解决的问题
输入向量尺寸问题
文字输入 每一个句子长度都可能不一样 例如将句子中的词汇以向量来表示的话,会有如下的编码形式:
- one-hot encoding 01串表示词汇的有无,体现不了词汇的关系
- word embedding 语音输入
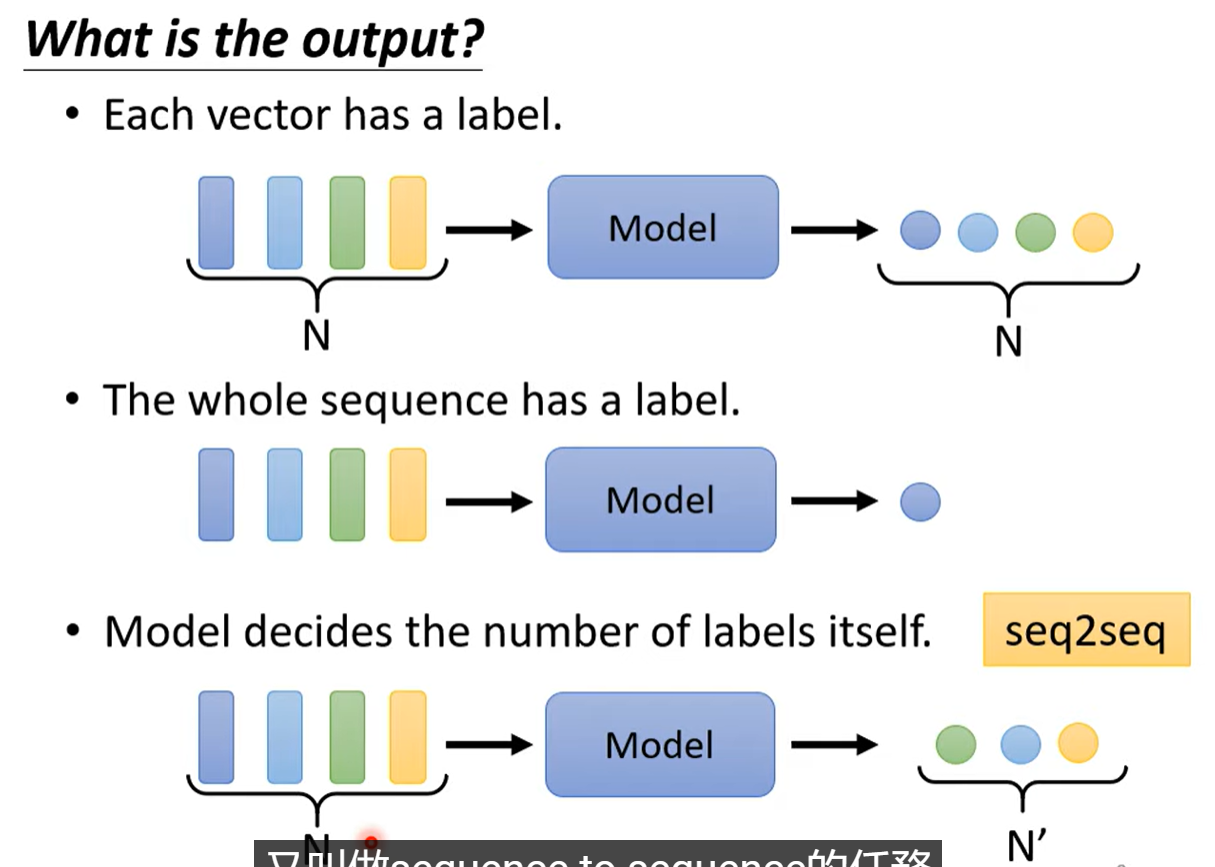 不同输出类型
不同输出类型
输入输出数量一致的称为:Sequence Labeling 暂时只考虑这种类型
如果只是用全连接层做预测,对于同样的输入无法要求模型有不同的输出(例如预测词性,同一个词在一个句子可能有不同的输出)( 参数一致)
使用一个窗口将前后的一些向量覆盖,都传给一个神经元做预测呢?这样一来考虑到了前后向量的联系,但是如果联系一直到sequence的整体长度呢? 运算量大,不同的序列空间可能冗余,容易过拟合,为解决这个问题,Self-Attention应运而生
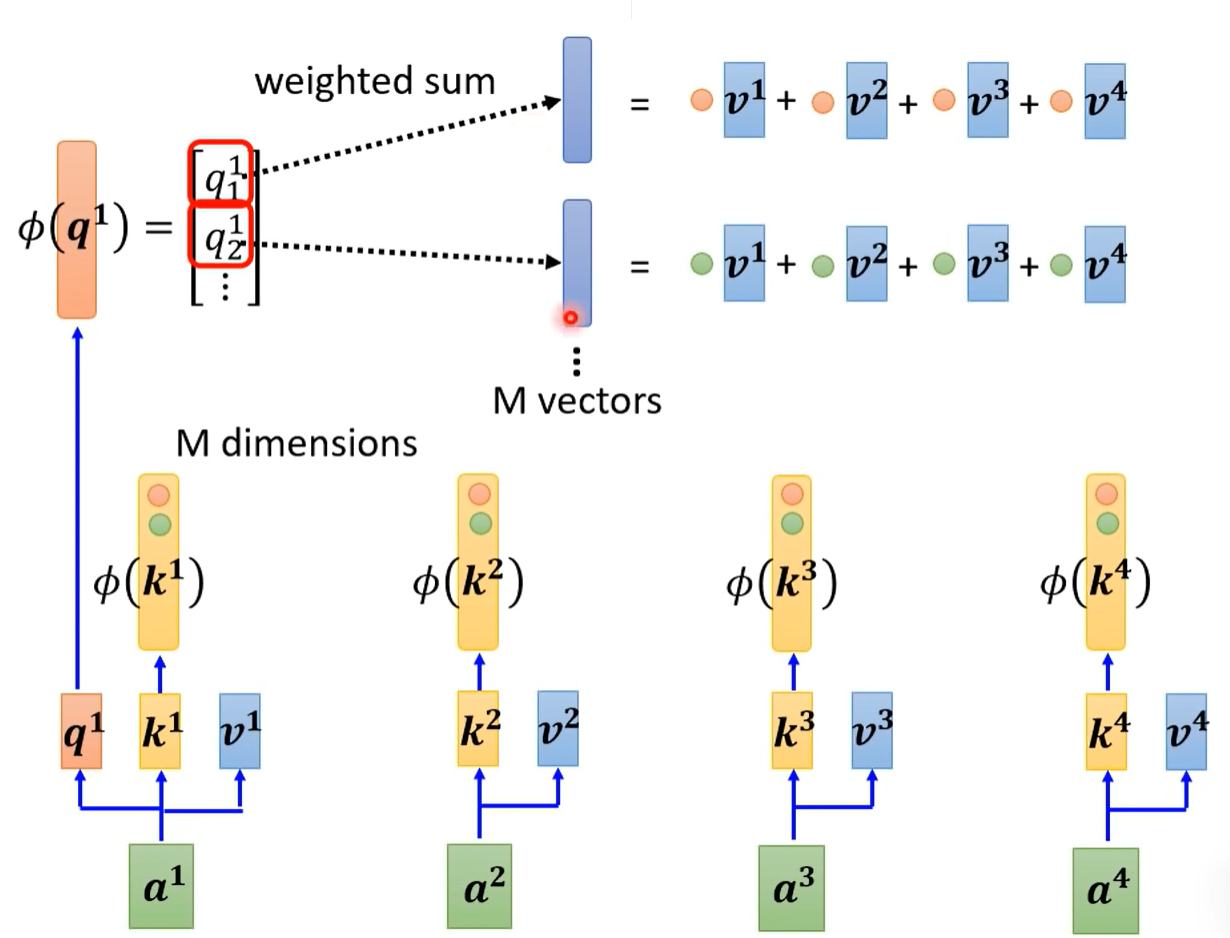
Self-Attention输入全部向量,通过一个计算attention的机制计算两两向量之间的关联 通常采用如下的方法:
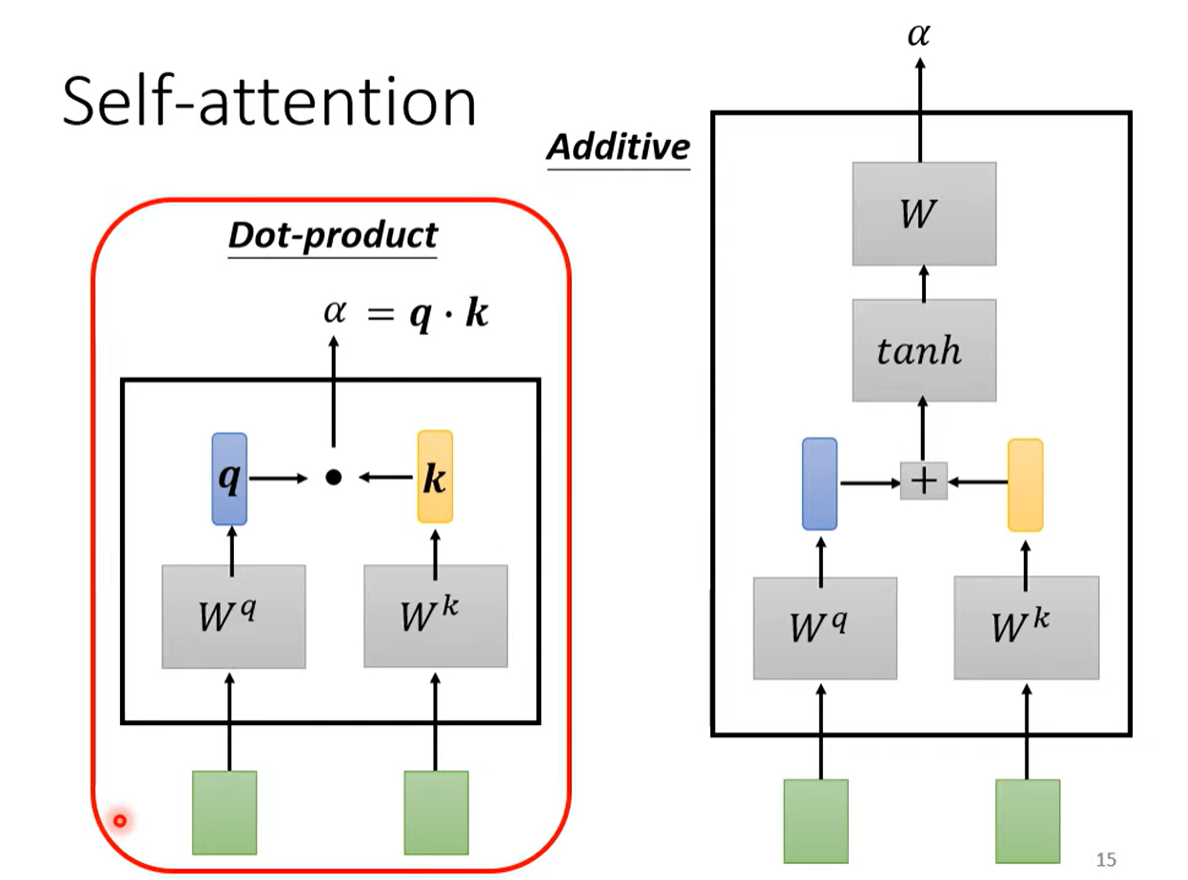
主要使用左边的方法:
- 输入两个向量值,通过两个矩阵() 分别做加权,再点乘得到 ,称为attention score
具体实现是:
-
每个向量有对应的两个矩阵,计算关联性时,当前的q矩阵与其他(包括自己)的k矩阵点乘得到 ,得到向量数量相同的各个 ,再通过softmax 计算得到 ,将值缩小到1以内(softmax不是唯一的选择)
-
对每个向量再乘上一个矩阵V,结果乘上 ,再相加得到b,这样一来相关性大的向量在b中的占比就大
-
对每个向量都做一样的处理,得到(1,2)(1,3)……,(2.1)……等的相关性,然后计算得到等
其中,矩阵 是各向量共享的矩阵 ,其作为参数需要学习
q为query,k为key 相当于一个向量向其他的向量进行查询,得到回复 v为value,就是输出值矩阵
- 从输入值a乘以矩阵Wq、Wk和Wv(这三个矩阵是模型参数,需要通过训练数据来学习),获取查询(Q)、键(K)、值(V)
- 通过计算查询(Q)与键(K)之间的点积Q,来衡量查询与其他词语之间的关联程度,然后,通过对这些关联程度进行归一化处理(一般采用softmaxl归一化),得到每个词语的注意力权重。
- 最后,根据这些注意力权重,对每个词语的值(V)进行加权求和Q,得到一个新的表示,该表示会更加关注与查询相关的信息。
Multi-head Self-attention
多头注意力机制
多头是什么意思?
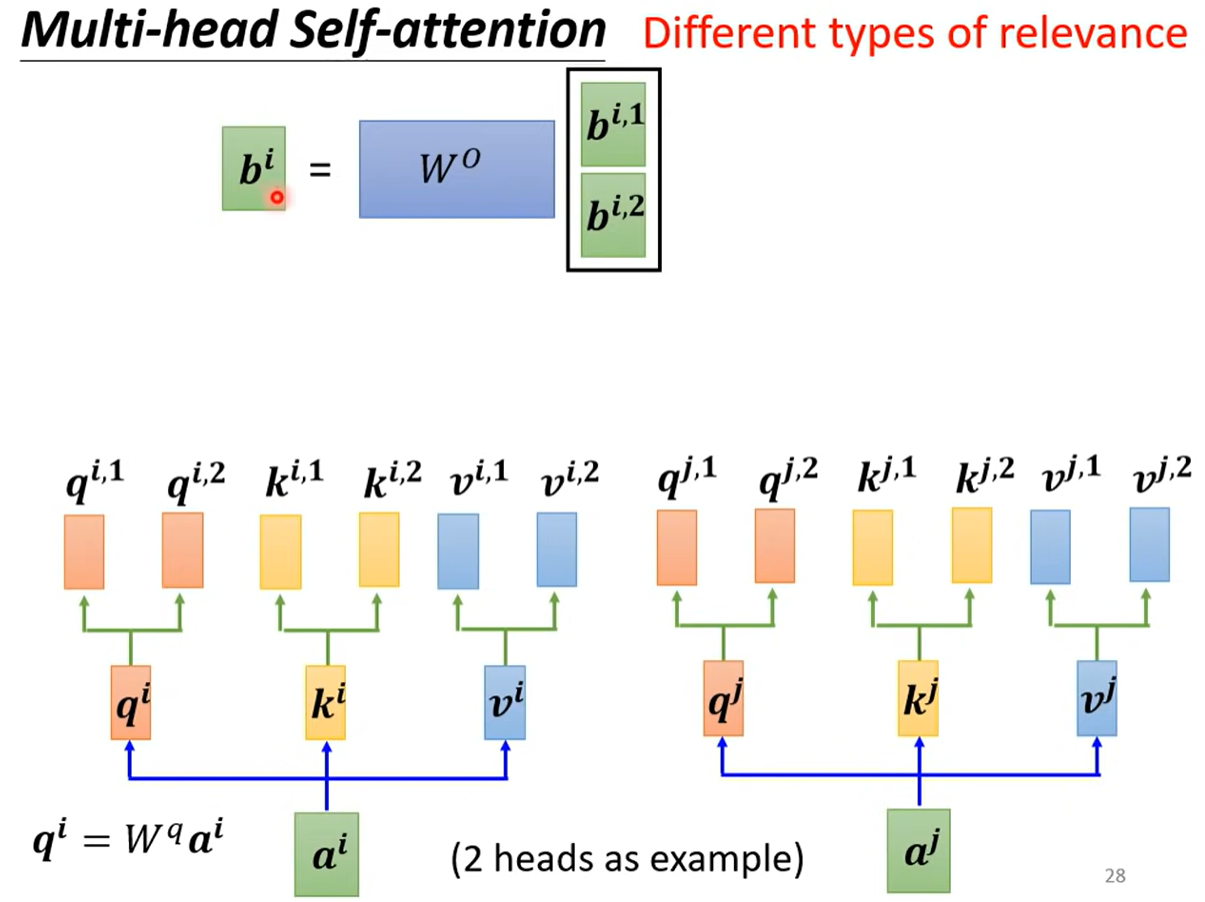
实际上两个特征之间的相关不一定只有一种,可以有多种相关,多头就是实现对多种相关性的考虑
实际实现上就是原本计算出q,k,v矩阵(乘上W矩阵后)后再乘上多个W矩阵分出,分别计算,再经过一个transform得到结果b
补充
位置信息? 目前为止的实现中,attention机制没有关注到位置信息,但其实可以加上相关的参数
positional encoding
增加位置向量,直接加在输入特征上 告诉attention机制位置的信息
e的值如何确定?
- 人为设置,在attention is all you need中使用一个cos sin的函数确定e
- 学习,通过深度学习学习出positional encoding
应用
-
NLP bert模型
-
语音辨识 一段语音的向量长度的是不确定的,且由于其是采样来获取信息,实际上采样的范围很小,也就是说一段录像需要极大的输入向量才可以描述,计算量很大
提出Truncated Self-attention(截断的注意力) 认为对输入的相关性每次只看一部分就好了 因为语音的前后相关性很强,但距离较远相关很快降低
-
影像 图像也是多向量集合
可以认为CNN是简化版的self-attention 因为二者都是考虑一个范围的咨询,attention是考虑全局的信息,CNN是考虑一个感受野的信息
也可以认为self-attention是在训练中自己学习感受野的形状和权重
RNN 比较
相同点:
- 输出sequence
- 多输出为FC
- RNN其实可以双层
不同点:
- 深层对数据联系的考虑不同,RNN将信息存储,且不能忘记,一直带到最后的层级,才考虑这个信息
- attention则全局获取信息
- RNN无法平行处理向量,因为有时序关系
各种attention
当序列很长时,self-attention的计算量就很大,这时的时间消耗主要就集中在attention的计算 此时需要计算query和key的乘积矩阵,规模是n
例如影像处理
-
local attention/truncated attention 当目标明确为,每次只需要关注周边信息就可以的情况时,就可以只计算周边的attention,减少计算量
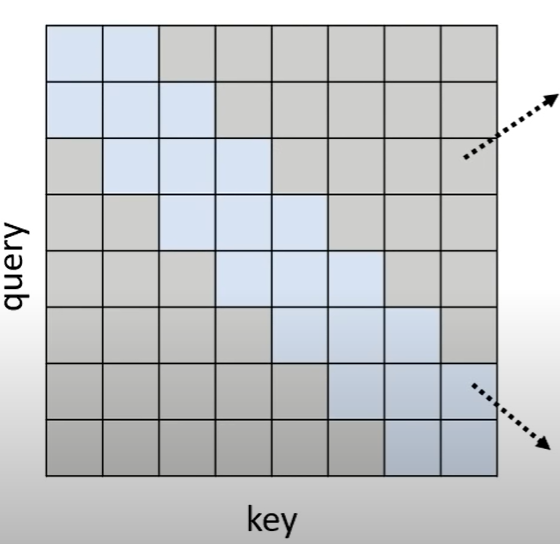
只计算蓝色区域(周边)
-
Stride Attention 只看一定距离的attention
-
Global attention 设定几个特殊的token
所有的其他token都被这几个token attend 到 其他的token也attend到这几个token attend就是参与attention的计算
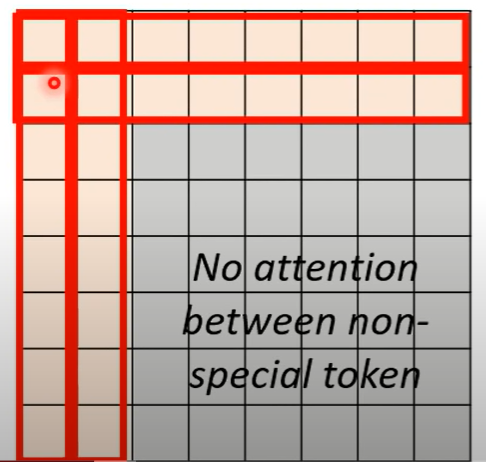
选定前两个为token,前两行意味着这两个token与所有的token做attention,前两列表示所有的token与这两个做attention
那要怎么做呢?
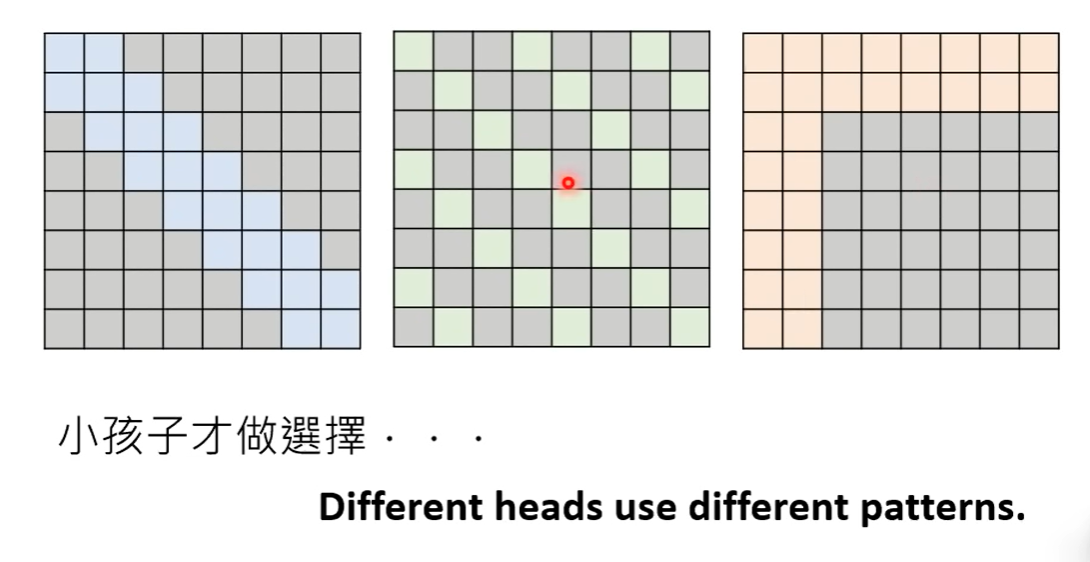
多头直接全部用(big bird)
但是这样人工决定真的没问题? 如果用科学计算的方式决定呢?
-
可以只计算attention会显著大的attention,接近0的直接认为是0 如何快速估计attention?
聚类(clustering) 将q和k用聚类划分,同类的参与计算attention
Sinkhorn Sorting Network 训练一个神经网络学习选择哪些位置需要计算attention
-
attention中其实存在一些较为重点的位置,这些位置的attention计算会重复出现,那就可以只计算其中代表性的attention矩阵
选择具有代表性的K个key和K个value,query的尺寸不变,每行和k计算再与value相乘相加得到第一行的attention,以此类推
为什么不用q? 因为输出可能变少,如果每个输入都要有输出,那么减少q的尺寸会使得输出结果不正确
因为是选出query,和key计算attention
做法:
- CNN扫过Key获取代表性的key(Compressed attention)
- 线性组合(矩阵乘法)减少矩阵的尺寸(Linformer)
-
更改计算顺序 线性代数方法改变矩阵乘法的顺序
原本是q与k相乘再与v相乘,做softmax
但是其实化简后可以发现,可以构造:k的每一维与v的每一维相乘再相加,最后将结果合并为矩阵
这和矩阵每一列与转换后的q矩阵的每一行相乘,可以得到与原始算法一样的值,但是被乘的矩阵却只构造了一次,减少计算量
q的转换是讲其转为exp的转换 ,实现softmax
-
Synthesizer 直接用输入产生attention,甚至attention当作网络的一部分,进行学习
Transformer
sequence to sequence Seq2Seq
输入一段序列,输出一段序列,并且长度都不一定
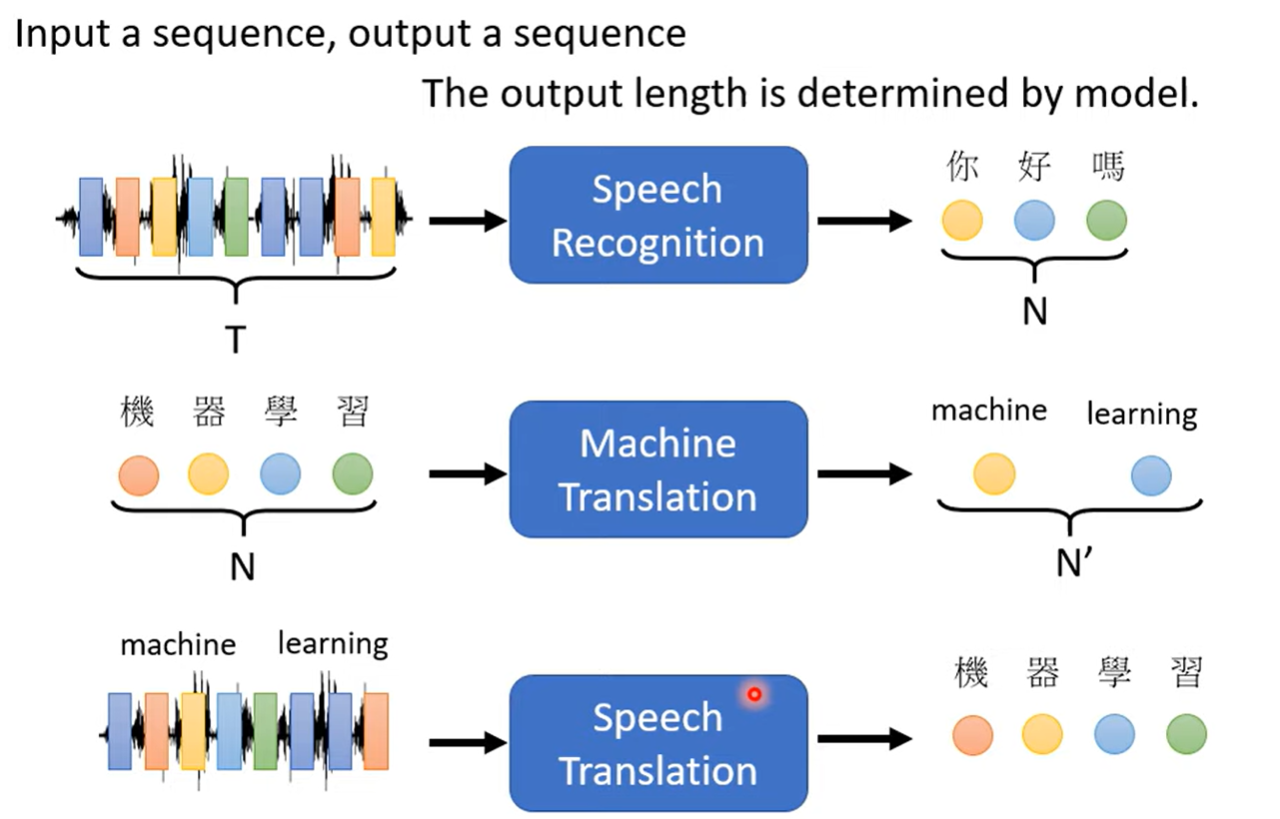
- 翻译
- 语音识别
- 实时翻译(直接翻译,不记录)
- 文法树分析
- Multi-label Classification(一物多标签分类) 机器自己决定输出的类别数量
- Object Detection
Transformer是Seq2Seq架构
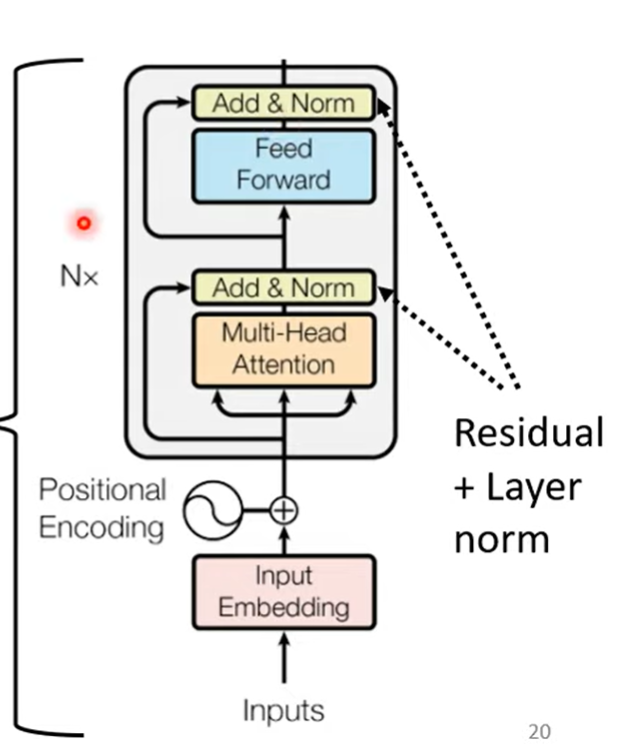
Encoder
给定一排向量,输出同样长度的向量
Transformer中,给定的向量经过一个个block,最后输出同样长度的向量
每个block的组成:
- Multi-Head Self-attention考虑整个序列输出同样长度的向量 再加上原来的输入(残差residual connection)
- 经过Layer Norm 计算均值和标准差,将向量标准化
- 经过FC(全连接层)输出 也有残差结构,得到最终输出
- 最后再做一次norm
同时输入还有Positional Encoding,因为只有注意力其实没有位置的信息
Decoder
解码器,对译码器的最终输出做处理
实际上会识别第一个开始标识(begin),是一个one-hot的串,其中一位是一
模型有预置的可能输出,例如中文会使用方块字(几千个),英文使用字母,单词或subword(词根词缀)
模型输出其中概率最高的值,作为下一个输入,Decoder再读取到输入的全部信息,输出下一个值
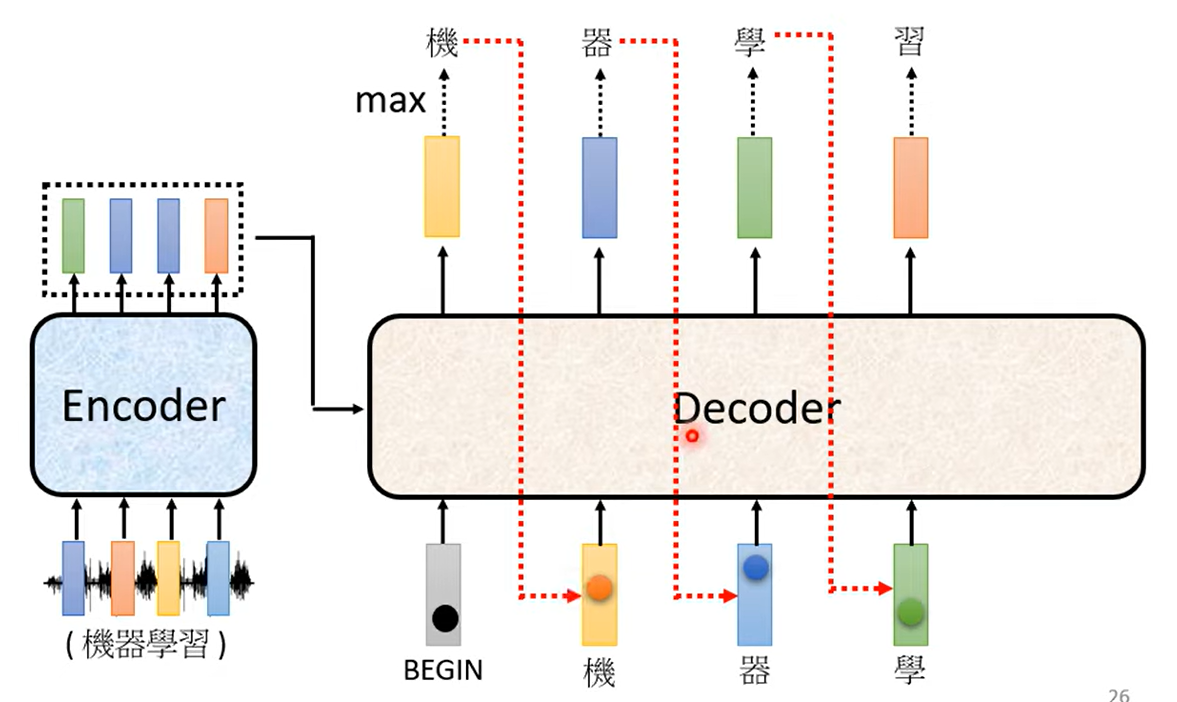
设置”断“符号(end),最后输出end实现模型自己学习输出的序列长度
Transformer的decoder中第一个注意力机制强调masked,是因为每次将输出当成下一次的输入,实际上无法考虑到没有产生的那部分输入,所以使用masked
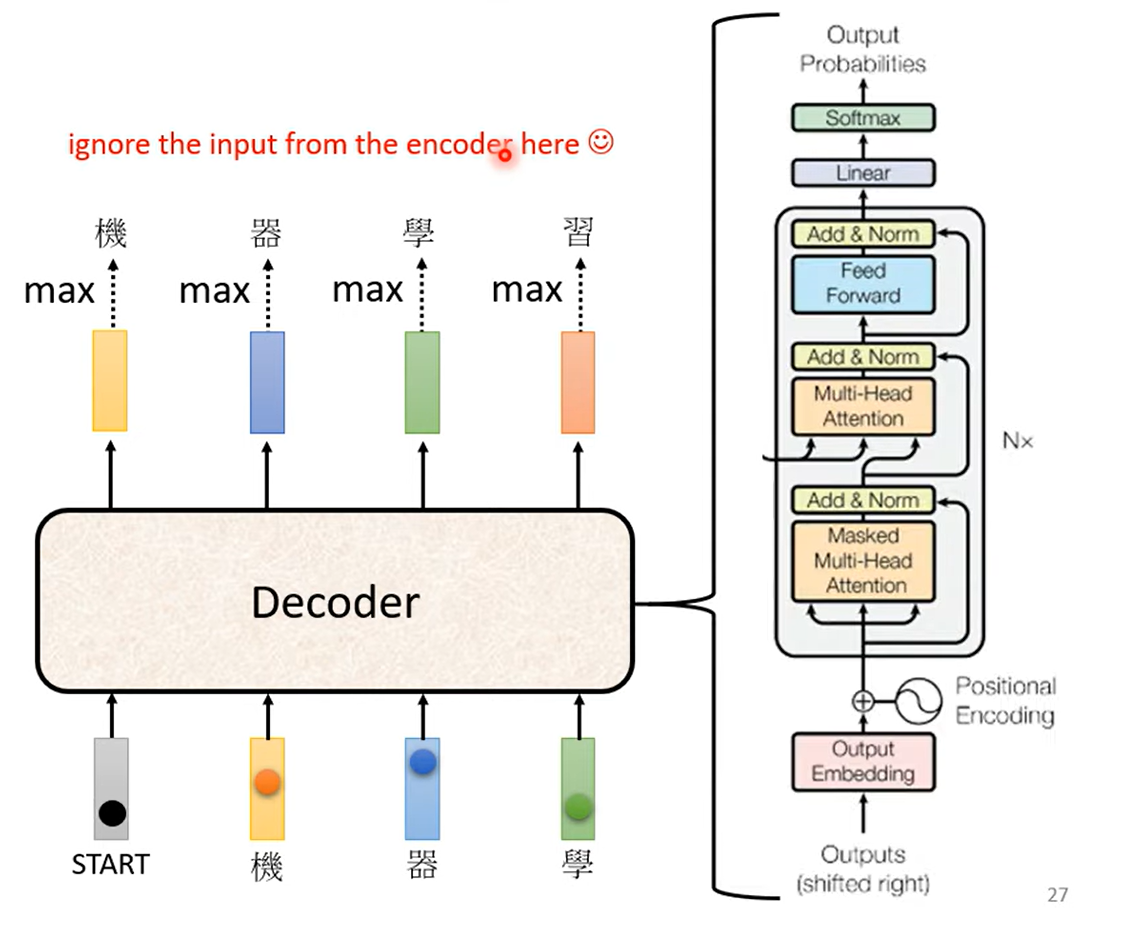
这称为Autoregressive,自回归模型
Non-Autoregressive NAT
输入一堆begin,输出一整个句子 那要输入多少begin?
- 使用classifier来对encoder的input做分类,输出一共输出多长的序列
- 使用end,当出现end,其后的数据去掉
如何处理encoder的输入
cross attention
quary来自decoder,k和v来自encoder
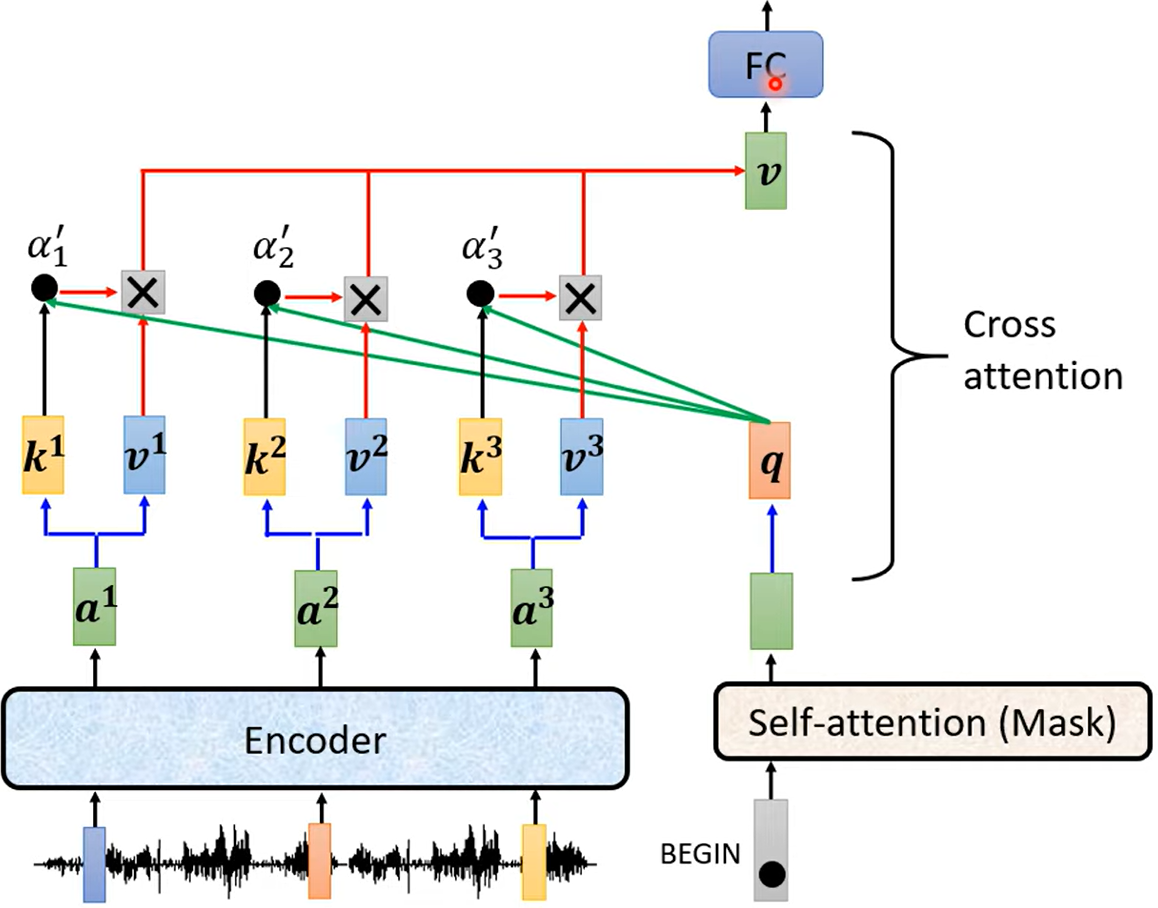
通过这种方式输入encoder的输出
FFN
关于FFN的研究有很多,说是FFN实现了Transformer的记忆功能,FFN引入了非线性变换,事实上,FFN去掉的话,Transformer就什么都学习不到
原论文里说到:FFN可以看成一个1 x 1的卷积,用于升维或降维,实际上,FFN就是一个两层的MLP,先变大再变小,接在注意力之后
那就有问题:注意力本身就有非线性,为什么需要FFN
- 实际上,注意力确实有非线性,但是对Value没有
- FFN实现了对特征的非线性变换,就像是Relu引入之后的神经网络,非线性使得Transformer得以学习大量的特征信息
Training
Teacher Forcing 将encoder的输出给decoder做cross attention,同时decoder的输入使用的是正确答案作为输入(GroudTruth)
也就是输入时不用自己的输出作为下一个字符的输入,而是直接看正确答案进行预测
loss是每次分类后cross-entropy值,训练输出正确的答案和end标识的预测误差
这样的话会有一定的mismatch,解决方法是在输入时偶尔加上一点错误的输入,称为——Scheduled Sampling
Exposure bias 曝光误差,就是Seq2Seq模型中训练与预测的输入不同导致训练与预测的结果误差
应用上是将teacher forcing的输入与模型的预测混合作为训练的输入,这样就混合了一些错误数据
Tips
-
Copy Mechanism 复制一段输入直接作为输出,例如出现了难以理解的词汇,机器学习很难预测到对于这样的输入要输出这样的结果,就可以直接复制过来当作输出
例如:人名,专业词汇,摘要等
-
Guided Attention 在已知attention正确分布的情况下,规定训练中atttention的分布
例如:语音辨识,合成
-
Beam Search 波束搜索
不是每次都搜得分最高的值,而是走其他其他值来达到全局最优
例如:当结果很确定时,例如语音辨识
有时不一定好,多一点随机性会更好一些,像语音合成需要一点随机性
-
BLEU score bilingual evaluation understudy 双语互译质量评估辅助工具
对于特定领域的模型,选择最优的模型时不一定要选loss最小的,而是选择在该领域评分标准得分最高的
-
Scheduled Sampling 计划采样
