概念
输出Distribution(分布)的神经网络,就成为Generator
一般由输入x,输入的简单分布,经过Network之后生成复杂分布
x在不同分布的影响下输出的y是更加复杂的分布
为什么实现Genertor
- 对同样的分布提供不同的答案,实现创造力
- 让输出成为一种与几率相关的,而不是对各种情况都讨好
GAN
Generator 与 Discriminator 相互影响进化的模型
以图片为例:
- Generator初始随机给定参数,利用参数与一个简单分布产生的低维向量产生高维向量,也就是图片
- Discriminator利用数据集与生成的图片进行训练,学习分辨图片是真是假(是否是生成的),此时要固定Generator
- 在更新Generator时只调整其参数,不修改Discriminator的参数(否则神经网络可能修改其参数来达到不合理的高数值)
- 反复迭代训练
原理
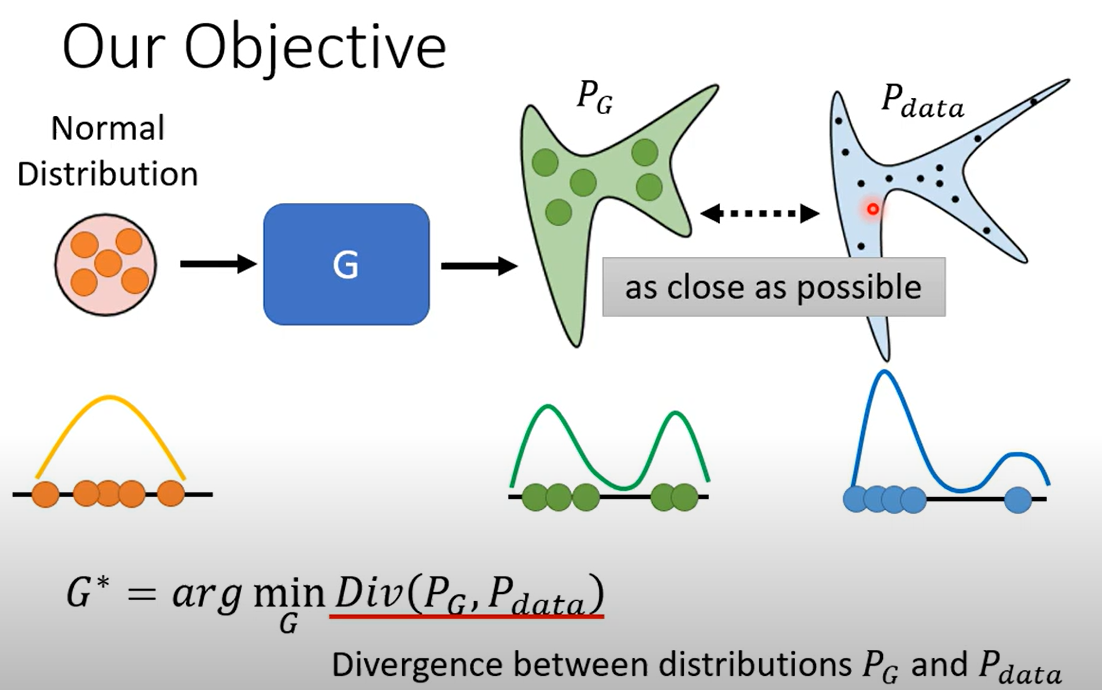
输入一个分布,经过一个生成网络后生成一个新的分布,希望这个分布与现实期望分布越接近越好
通过 表示找到一组参数G实现最小化发散,其中Div表示两者的Divergence(发散程度)
但是发散是难以计算的,应该说其梯度等数据是难以计算的,GAN所解决的就是如何计算发散的问题
利用计算,从原本的数据中取样出一部分,再从原本的分布中取样(分布足够简单)出一部分给Generator生成,得到两组数据
这两组数据作为Discrminator的输入,其看到真实图片给出高分,看到生成图片给出低分,类似于二元分类,即找到参数
定义Loss如上,之所以这么定义是因为要贴近cross-entropy(就是二元的cross-entropy加负号)
那这个值与发散程度有什么关系呢?
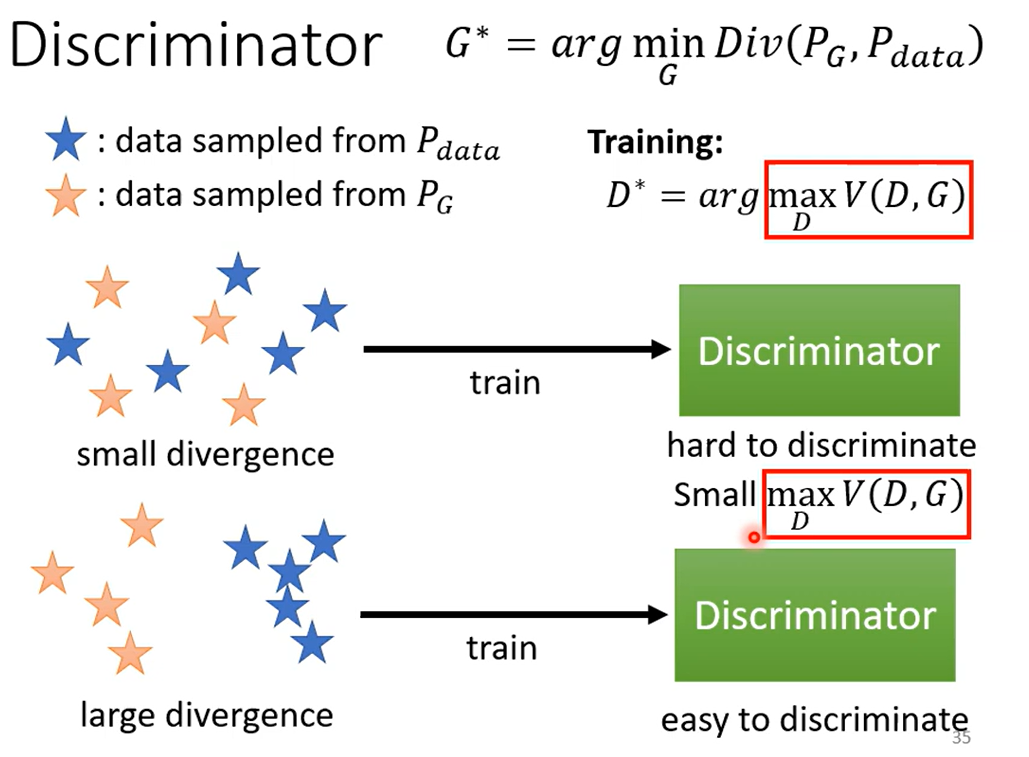
当二者不发散时,maxV计算结果会小,因为分不开 相反,当二者发散时,maxV计算结果大
用 ,可以得出如下训练过程和结果

Using the Divergence you like(什么样的Loss对应什么样的Divergence) https://arxiv.org/abs/1606.00709
难以训练
- 取决于数据特点,一个二维的分布中很少一部分分布可能构成图片,更少能构成所需的图片,即 低维流形(monifold) 在 高维 空间的映射,例如地球仪上的点在现实世界的映射
- 取样导致数据实际的重叠没有被充分体现,也就是取到的样本都恰巧没有表现出重叠的性质
使用JS divergence 训练
JS divergence (Jencon‘s Shannon)
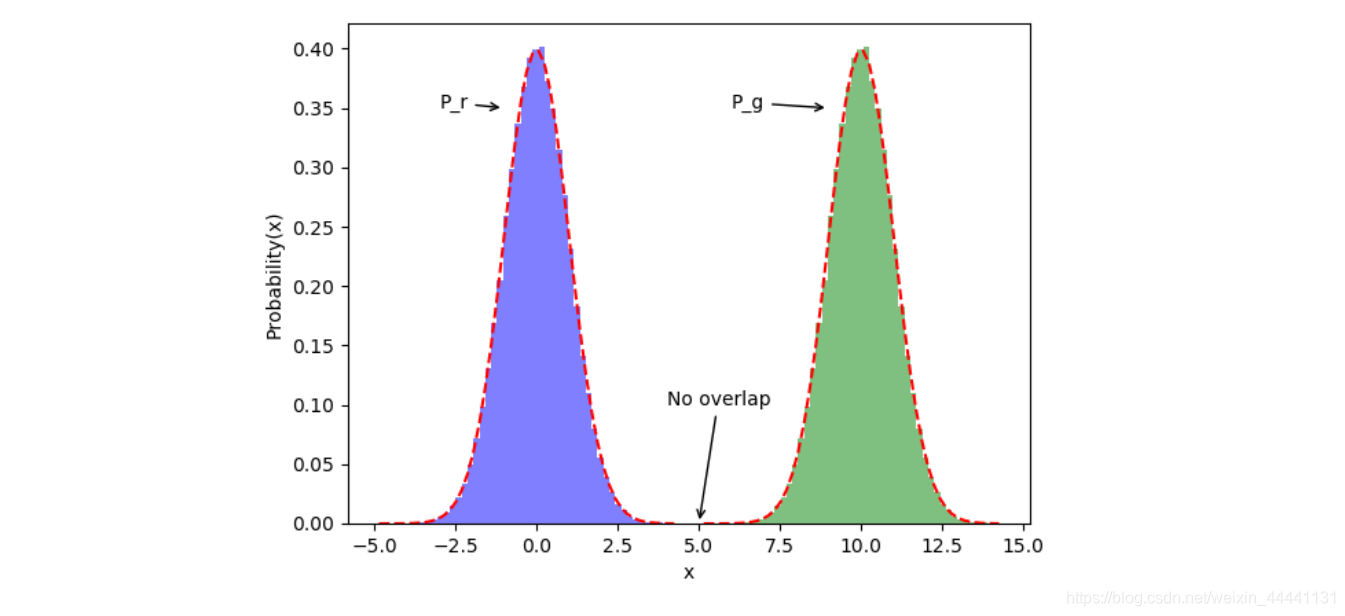
可以看到当没有重叠时,Div值没有意义 这就是说,即使模型训练结果越来越好, 越来越接近,在重合之前都,其Loss值都一样,无法告诉神经网络往二者接近的方向训练
使用其他Loss训练
Wasserstein distance 将分布p移动到分布q的平均距离,当然存在多种移动的方法,选择使得平均距离最小的移动方法作为计算结果
实际上W也难以计算,所以依旧是使用代替的Loss函数
其中D需要是一个1-Lipschitz的函数(足够平滑),防止无限大(小)
如何实现平滑?
- 范围约束
- 梯度惩罚函数
- spectral normalization 谱归一化
其中效果最好的是Spectral Normalization GAN (SNGAN)

Quality of Image
衡量Generator可以使用影像分类系统,当一张分类集中,则说明生成的结果好
模型坍塌 Mode collapse
从定义上看,其实是数据经过两次非线性计算后,结果收敛到一个点上
如果依赖图像分类,那么会有一个问题: 如果生成的只有一种满足要求的图片,那么其分类结果就会十分精确。
其实就是Generator学会重复生成一种图片来满足Discriminator的要求,达到损失函数的降低
Mode Dropping
生成器的多样性低于训练集的多样性
多张图片影像分类分类结果多样
Inception Score(IS)
高质量,高多样性
FID(Frechet Inception Distance)
做Inception Score一样的图像分类,将分类之前的最终向量拿出来 再将真实图片的该向量计算出来,两个分布当成高斯分布计算距离,作为得分
Condiitional Generator
有条件的生成器 例如输入一个确定条件,输出符合条件的y
-
Text to Image 随机到不同的seed,生成不同的图片 此时Dis需要有两个输入,一个生成的图片,一个是文字要求
-
Pix 2 Pix 像素to像素,图生图
Unpaired data
不成对的资料(unlabel)
需要Unsupervised Learning
例如:
- 影像风格转换 真实图片转二次元之类的无法简单做出x y标记的目标
Cycle GAN
以影响风格转换为例
输入为真人照片,输出为动漫图像
可以更改输入的Gaussian sample为简单的图像sample,即从多个真人图像里选一个出来,输入给Generator
将Discriminator的工作改为对比动漫图像和真人图象,动漫给高分,真人给低分就可以实现对真人图像对动漫图像的转换
但是这并没有对Generator做限制,只要其生成任意一张动漫图像,结果就是高分,与输入几乎无关
所以需要再训练一个Generator,做Cycle GAN
这个Generator将图像从动漫转为真人,让前后的图片越相近越好(还原)
这就限制了第一个Generator的输出必须与原来的真人照片有关系
虽然理论上这样并没有给定转换关系(例如可以真人与动漫图片完全不像,但是有一定转换逻辑,这并不能达成风格转换的目的)但是实操时却会发现实际上网络的工作偏向于输出与输入相近的图片
Cycle GAN同时可以做另一个方向的训练,动漫-真人-动漫,使用已经定义的两个Generator
其他风格转换的任务也可以用Cyle GAN的逻辑做,例如文字积极消极转换(但是注意Discriminator训练文字会有问题,要用RL硬train)
例如:
- 摘要总结 Unsupervised Abstractive Summarizaton
- Unsupervised Translation
- Unsupervised ASR(Audio — Text)