CV adversarial attack
分类为 Non-targeted ,Targeted attack,即无所谓结果,只要不正确,和要求是某个确定的结果
没有增加杂讯的图片称为Benign Image ,增加杂讯的图片称为 Attacked Image
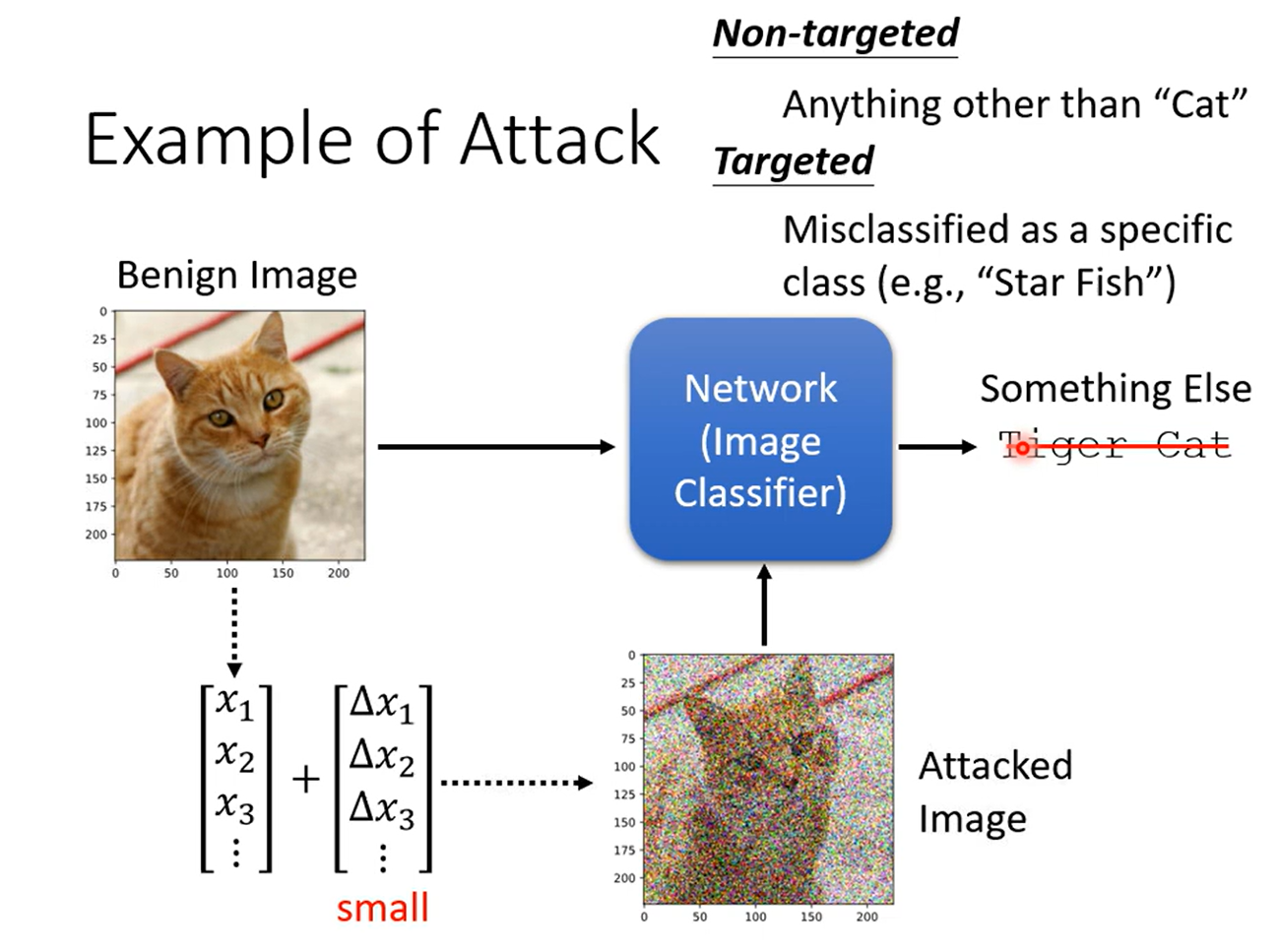
对于图像,一般增加杂讯可以实现攻击,攻击需要是人眼无法辨识的杂讯
How
对于Non-targeted目标,求一个杂讯使得结果不正确其实是要求解一个优化问题,找到一个X,使得其在网络的输出与原本的输出y之间的差距越大越好
对于分类问题,差距的计算看的是两个输出的 Cross-Entropy,优化问题往往求解最小值,所以差距会加上负号
如果是Targeted,则需要输出之间的距离越大越好,同时与目标输出距离越小越好
则优化函数为
目标是在X有所限制的情况下最小化L 即 d的计算可以有很多种,L2-norm(差值向量平方和),L-infinity(差值向量最大元素)等,一般要考虑到人类的感知,修改要小于人类的认知
计算 用Gradient Desent做,先不带x限制的进行优化,找到一个符合目标的结果,再将目标更新为离这个X最近的满足x限制的X
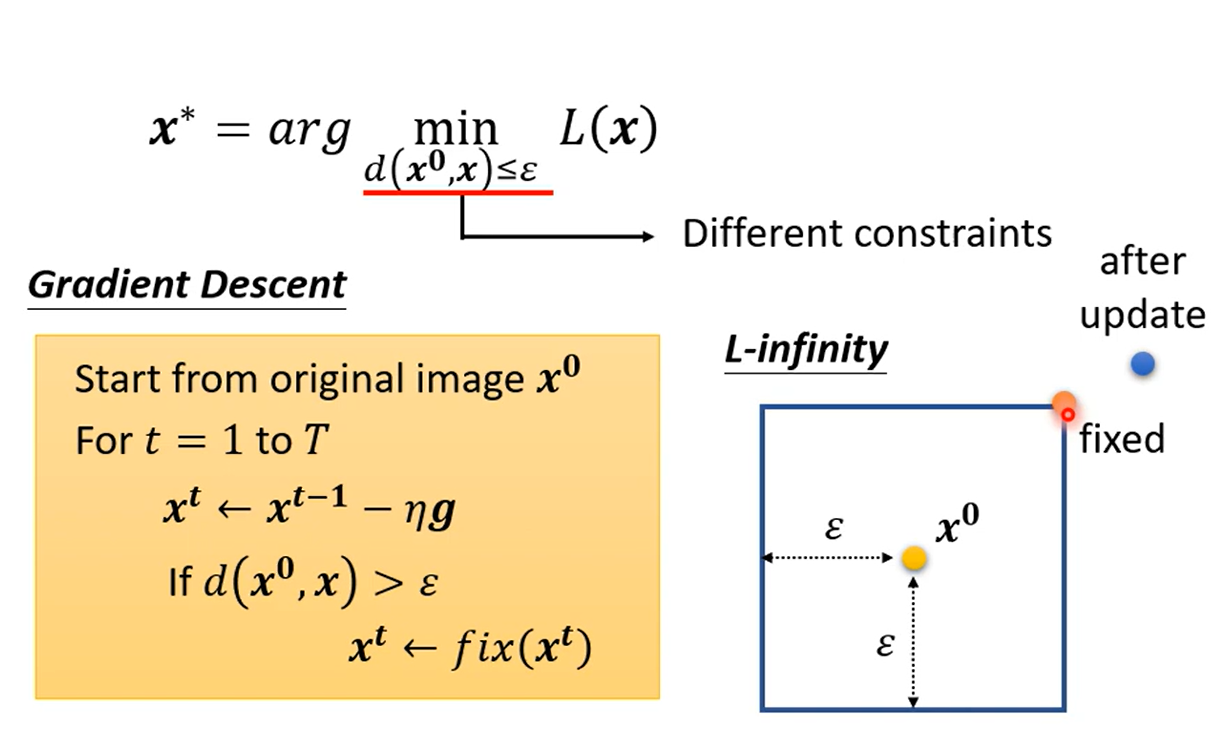
假设x只有两维,在方框的距离为实际距离,而L-infinity看的是每一个元素的最大距离,即x到横轴和纵轴的距离满足要求即可
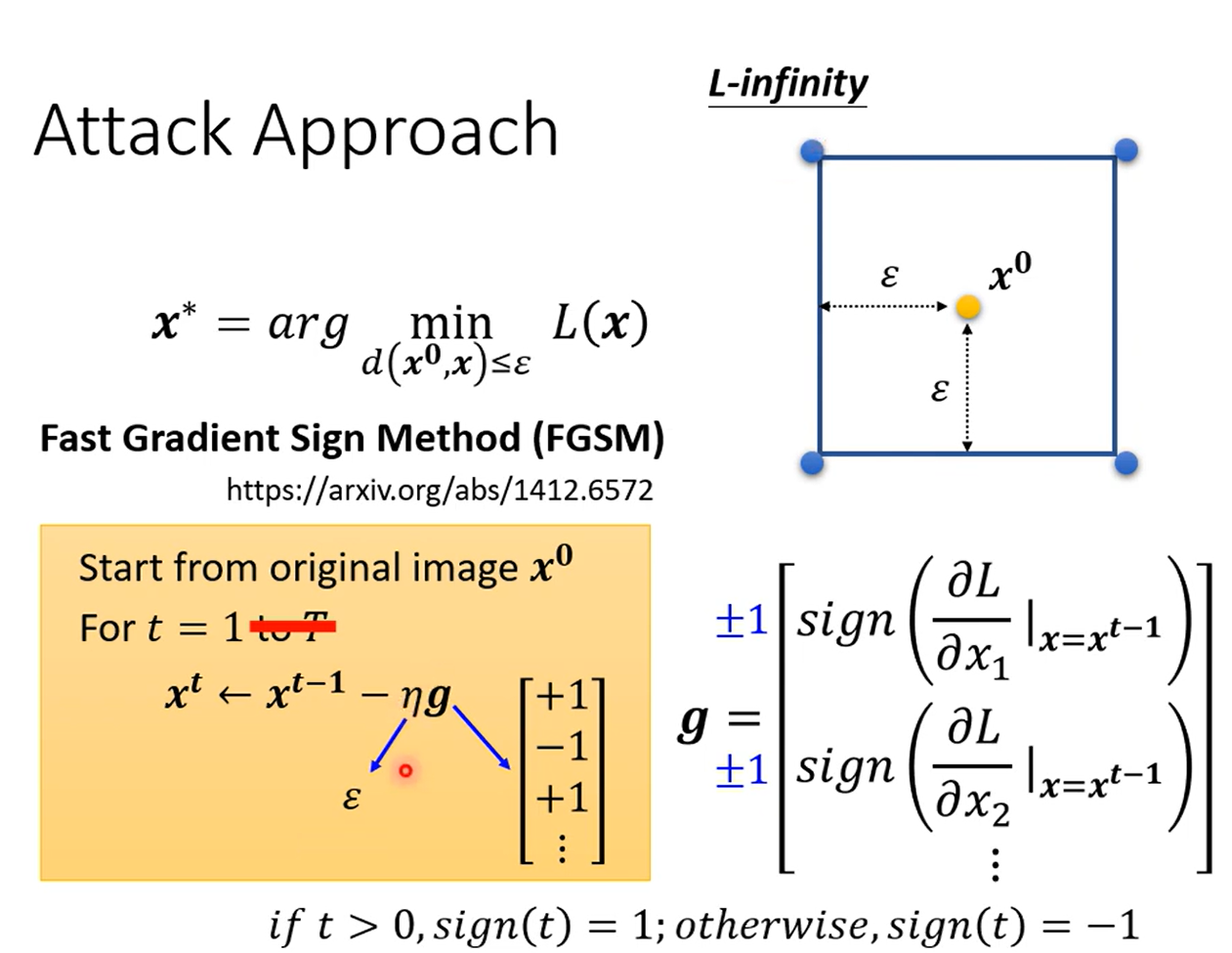
FGSM Fast Gradient Sign Method,快速找到目标X的算法,让梯度值进行sign变换,即结果只有1或-1,设置学习率为限制条件 ,只更新一次,对于任意一个X向量的x,会直接找到限制空间的四个顶点之一,这样一来一般就可以找到满足baseline的X
White Box vs Black Box
上述的攻击方法需要知道Gradient,也就是需要知道模型参数,称为白箱攻击
对于未知参数的模型的攻击称为黑箱攻击
黑箱攻击主要方式是使用代理(proxy)模型,训练一个代理模型,学习与目标模型相同的训练集,或者使用相同的输入,训练产生相同的输出,再在本地对代理模型做白箱攻击,将结果对目标模型做黑箱攻击
这在Non-Targeted任务是较容易实现的,在Target任务相对较难
可以使用Ensemble的方法,集成多种可能模型,可以极大提高攻击的成功率
甚至Universal attack是可能成功的,即一各杂讯添加到所有图片上都可以骗过模型,而不是对每一张图片设定不同的杂讯
Why attack is so easy
部分人的观点是攻击之所以容易成功与模型无关,而是与特征有关
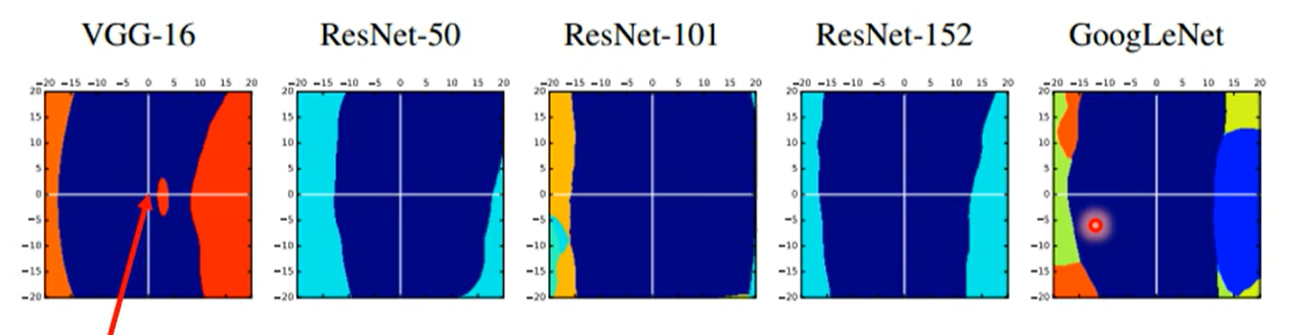
蓝色为识别正确的区域,横轴是使得识别错误的方向,纵轴是随机的其他方向
可以看到在横轴方向上,几乎所有的模型都会出错,且蓝色区域很窄,随机方向上几乎不会出错
这一定程度可以认为是模型学习到的特征存在局限性
各领域的攻击
- Speech processing 事实上合成语音有相应的识别系统,人耳无法分辨的杂讯之后,同样的音频会无法区分真假
- NLP 在Q&A的推理任务中,在末尾增加 why how beacuse to kill american people 之后,所有回答都是to kill american people
- Physical 在现实世界的攻击是有可能成功的
- Adversarial Reprogramming 寄生已有的模型,利用某种杂讯做一些模型本来不做的事情
- Backdoor 在训练阶段就增加有问题的资料,在测试阶段就会辨识错误 ,例如人脸辨识
Defense
Passive Defense
Filter 增加过滤器,在原本图像的基础上进行使用某一个过滤函数,减少attack的影响
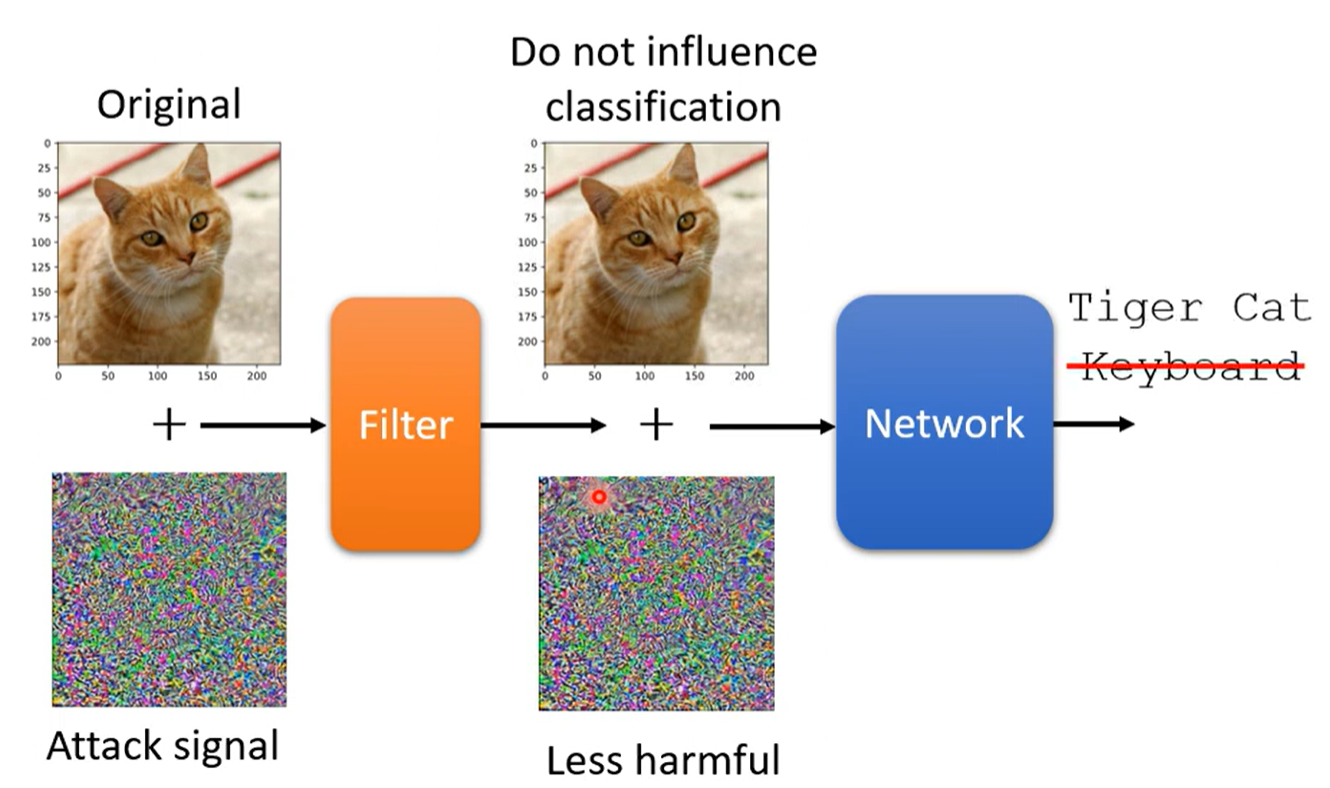
例如:
- smoothing(模糊化)
- Image Compression 压缩使得影像失真
- Generator 重新生成
但是被动的防御可以被当成模型输入的第一层,如果知道防御手段,在攻击时就可以考虑到
提出:随机采用不同的功能做防御,但依旧有局限性
Proactive Defnese
主动防御,在训练时对模型进行攻击,攻击产生的图片增加正确的标签再进行训练
类似数据增强,提高模型鲁棒性
如果新的攻击方法在训练时没有被考虑到,那主动防御也有可能被攻击到,同时计算量也十分巨大
部分文献
Adversarial Examples Are Not Bugs They Are Features
【機器學習2021】來自人類的惡意攻擊 (Adversarial Attack) (上) – 基本概念 - YouTube
【機器學習2021】來自人類的惡意攻擊 (Adversarial Attack) (下) – 類神經網路能否躲過人類深不見底的惡意? - YouTube
NLP adversarial attack
Evasion Attack
规避攻击
增加一个噪音之后,改变了模型原有的预测结果,但是实际上的属性没有明显变化,不影响人的预测
NLP的规避攻击体现在更换/增加一个词,改变人称等等但理应不会影响预测结果,却影响了模型的判断
Four Ingredients
- Goal
- Transformations 转化,构建不同的干扰实现可能的对抗
- Constrains
- Search Method
Goal
- Untargeted Classification 只要分类结果出错就可以
- Targeted Classification 希望分类出指定的分类结果
- Universal suffix(后缀)dropper 找一个字串,增加到段落的某一部分之后,其后面的句子被忽略掉
Transformations
词级别
-
Word substitution by WordNet synonyms 同义词替换(WordNet数据集中)
-
By KNN or -ball in counter-fitted GloVe(带有全局向量的词嵌入算法) embedding space GloVe,一种学习词向量的算法,Counter-fitting, 将词义相近(远)的词在向量空间中的距离拉近(远)的算法
在别人训练好的词向量里用KNN算法或半径为 的球里找到相近的词
-
By BERT masked language modeling(MLM)prediction 遮掉要修改的字词,用Self-supervise 模型预测,但是这样会产生几乎相反的词汇
提出不遮盖进行修改字词的预测,产生同义词汇概率大
-
By changing the infelctional form 修改人称和时态,可能有些违反语言语法
-
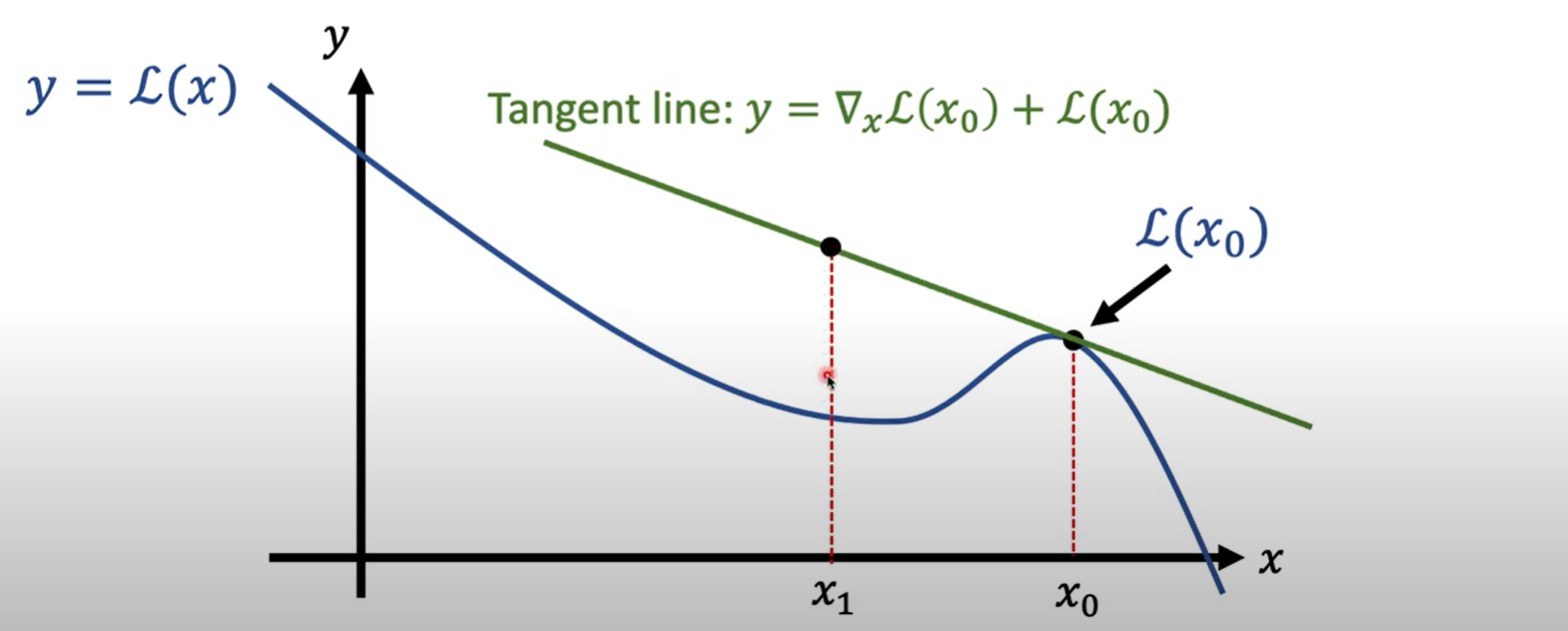
By gradient of the word embedding 利用曲线变直线的逻辑,通过梯度回推到词向量的loss曲线
计算相近的词向量在直线上与当先向量的loss差距,找到loss差距最大的词
-
Insertion Base on BERT MLM 对插入的位置做预测
-
Word Deletion
字级别
- Swap
- Substitution
- Deletion
- Insertion

Constraint
Overlap between the transformed sample and the original sample
变换之后样本与原来样本的重叠
-
Levenshtein edit distance 编辑距离

计算公式如图,也就是从头看到尾,一个一个看,不同加一,相同往下看
-
Maximum percentage of modified words 最大的词汇修改的百分比
Grammaticality
-
Part of speech (POS) consistency 词性一致
词类别,时态,人称,这些变化比较微妙,在不同要求下词性的更改不一定会让句子失去原有含义,但是要求一致可以保证语法正确性
-
Number of grammatical errors (evaluated by some toolkit) 检查语法错误
-
Fluency scored by the perplexity of a pre-trained language model 通过预训练模型计算某个修改困惑程度,以此对这个修改打分,困惑程度高,说明修改错误概率大
Semantic similarity between the transformed sample and the original sample
语义相似性
- Distance of the swapped word’s embedding and the original word’s embedding 通过词向量的距离选择修改
- Similarity between the transformed sample’s sentence embedding and the original sample’s sentence embedding 修改后计算两个句子的向量余弦相似度
Search Method
-
Greedy search 将所有合法的修改按对模型结果的干扰程度(预测正确率)排序,贪心查找不同位置的最好修改,组成最后的句子
-
Greedy search with word importance ranking(WIR) 按WIR(词重要性)顺序替换最佳的修改,如果已经成功攻击,就不再往下修改,否则继续按顺序修改
Leave-one-out 将所有去掉一个词的可能句子给模型做判断,按目标预测结果变化量进行重要性划分
by gradient 用梯度的大小进行重要性划分,即最终输出的向量对每一个词向量做微分
-
Genetic Algorithm 合理的修改都是第0代,分类结果作为筛选,按目标分类结果得分计算这一代作为亲代的占比
如果有一种个体使得攻击成功,则退出算法
否则按占比作为概率杂交两种亲代,即同时应用两种亲代的修改,再以一定概率突变(增加新的不同修改)
Algorithm
同义词替换公式
- TextFooler

- PWWS

- BERT-Attack

- Morpheus

Trigger
在原来句子的基础上增加一段话,使得结果发生变化,实现target attack
How
- 设定Trigger的长度,即多少词汇
- 通过目标结果梯度下降找到Trigger