推荐算法
定义
r(i, j) -- user j has rated moives i
y(i, j) -- rating user j give movies i
w(j), b(j) -- Parameters
x(i) -- feature
m(j) no of movies rated by user j- 特征x表示这个电影在不同类型的得分
通过调整 w,b 与 x的线性方程: 来做预测
对单个用户:
 定义如上损失函数(只对r(i, j) = 1学习),学习参数w,b
定义如上损失函数(只对r(i, j) = 1学习),学习参数w,b
加上正则化:

注意到m(j)不过一常数,去除掉也可以得到同样的w,b
对多个用户:
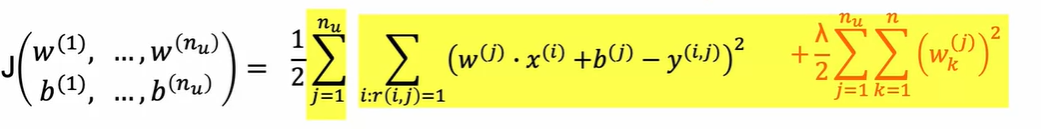 去掉m后多个损失函数相加
去掉m后多个损失函数相加
当特征值未知时
已知参数,逆推特征
定义损失函数
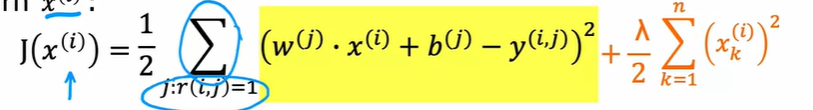
含义为通过变换变量x,来最小化预测值与真实值的方差,再加上一个正则化来缩放
对所有特征
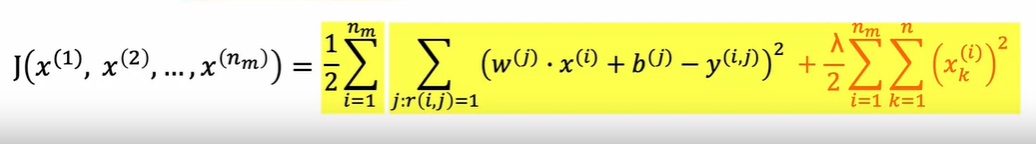
含义为已知权重的情况下得到特征
协同过滤算法
组合上述的两个模型,可以得到新损失函数
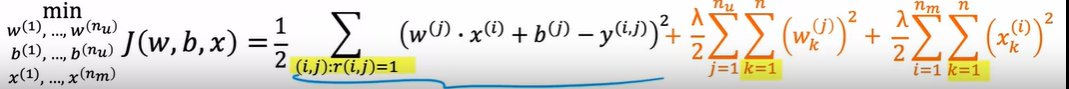 同时调节w,x,b使得方差最小
同时调节w,x,b使得方差最小
这称为协同过滤算法(CF)
其梯度下降为:
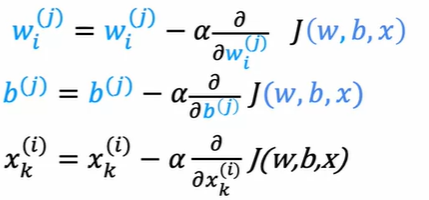
协同过滤,多个用户共同评价多部电影,其评价结果可以用来推测电影的特征,电影特征又可以推测各自的喜好,进而可以预测其他没有评价过某部电影的用户会如何评价这部电影
二进制标签
如果只有二进制的标签,例如点击与否,喜欢与否,看完与否等数据,那如何使用协同过滤算法?
类似逻辑回归,利用logistic函数(Sigmoid函数)将y值变化到(0,1)之间
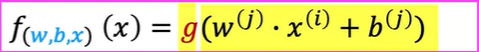
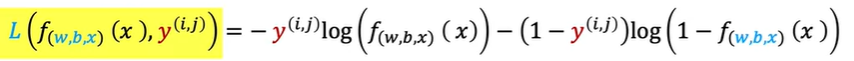 损失函数也与逻辑回归相似
损失函数也与逻辑回归相似
总体的损失函数
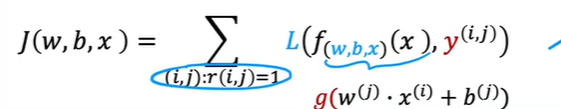
平均值归一化
还在回归型的协同过滤算法
假设存在一个用户没有对任何电影(商品)进行过评价,那么在我们的设计中,正则化 很可能会最小化该用户的参数 w,因为这个参数对最终结果几乎没影响
通过均值归一化可以优化这个问题
按行(每部电影)取评分的均值 ,再用 y - 作为新的y值,用新的y值来学习参数w,b,x
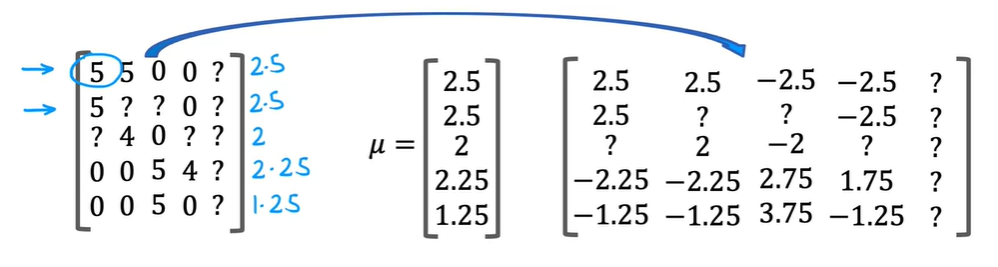 这种情况下,新用户的w值依旧可能会是0,y值计算结果也接近0,但是在有正负的y值中,y=0有意义
这种情况下,新用户的w值依旧可能会是0,y值计算结果也接近0,但是在有正负的y值中,y=0有意义
最后的预测结果加上 ,恢复原来的值域,新用户的预测值就是平均值,这比0值更有意义
这是极端的现象,归一化之后算法的预测会更快,同时对只评价了少数电影的用户,其预测值也更准确一些
TensorFlow实现
Auto Diff
自动求导,求微 TensorFlow提供自动求导的功能,指定参数变量与损失函数,在训练过程会自动求导进行计算
相关产品
找相似的商品、电影、书籍等,可以通过特征的L2距离计算,即同类特征的方差
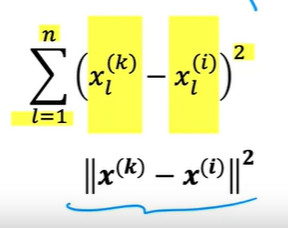
用于构建更强力的推荐系统
缺点
Cold start problem
对于新产品,新用户的评分存在缺陷,算法通过评分来训练,对于没有评分的产品预测效果差
没有使用其他的侧面信息
不同的侧面信息可能可以更好的预测,但是算法只基于评分信息,没有合理利用
Content-based filtering
学习匹配
用户特征:用户信息,对哪些电影的评分,地址等
电影信息:制作组,属于那类电影等
通过学习二者的匹配关系进行评分预测(推荐)
实际上两种特征的数量可能差距很大,在预测时学习的模型是: 改参数w·x为两个向量相乘,去掉参数b(不影响)来学习用户(u)与电影(m)的匹配关系
这个模型中向量值为特征转化的数字,但是特征数量不同,但是v的数量却要求相同(点乘)
要对x做一定的计算来得到v
计算向量v
通过神经网络计算
以x为输入,经过几个隐藏层得到一个向量v 这将构建两个神经网络,计算出两个向量,然后进行向量的点乘
合并神经网络为一个,利用同个损失函数来学习向量v与最终的结果
 选有标记的评分值来计算预测与结果的误差,后面是正则化
选有标记的评分值来计算预测与结果的误差,后面是正则化
找相近的产品
向量v就是对产品的描述,两个向量之间的相似度可以用L2距离来描述
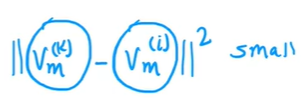 这可以找到相近,同类型的产品
且可以预处理,在用户访问之前归类好相似的电影(商品),在访问时进行推荐
这可以找到相近,同类型的产品
且可以预处理,在用户访问之前归类好相似的电影(商品),在访问时进行推荐
对巨大数量的优化
当商品数量极大,推荐算法的计算开销巨大,需要对推荐的商品进行一定的筛选
分两步:
-
Retrieval 检索 生成较多数量的用户可能喜欢的物品,例如最近看的10部电影相似的电影等
这要保证覆盖面广,确实覆盖到用户会喜欢的商品
去除重复项,用户买过用过等
-
Ranking 排名 将检索出来的商品进行训练学习,得到向量v,计算用户会给高分的商品
更具分数进行排名
处理过的v存储下来可以让计算得更快
检索的数量需要实验来确定 多少数量可以让检索结果与用户需求更相配(在评分时更高)
道德问题
更强的公司带来更强大的推荐系统,更多的资金进行宣传,如果公司本身业务对用户有剥夺性,危害性(例如烟酒,贷款,媒体),那可能导致更大的危害,获得更多利益,形成负面的循环