聚类算法 clustering
无监督算法,通过输入数据集(x, y),让算法自己找数据集的特征并进行聚类
应用
- 搜索推荐
- 新闻推荐
- DNA识别
- 星系划分
K-means 聚类算法
k均值聚类法
猜测各类别的中心 - 将点分配给聚类质心 - 移动聚类质心
- 聚类质心 Cluster centroids 作为分类依据,通过选定质心,再分析各个点与其距离来进行分类
- 分配
- 移动质心 按照分配结果,对各类的点取平均位置,让后将质心移动到该位置,直到质心不再改变
具体步骤
- 选定质心
- 分配点,为点找到L2范数最小的质心
- 计算分配结果中,所有点x坐标,y坐标的平均值
- 直到质点不移动结束(如果质点没有分配到点,一般删掉该类,也可以重新初始化)
K-means算法对离群不充分的数据也有较好的聚类效果,可以理解为为这些数据找到了具有代表性的点(质点)
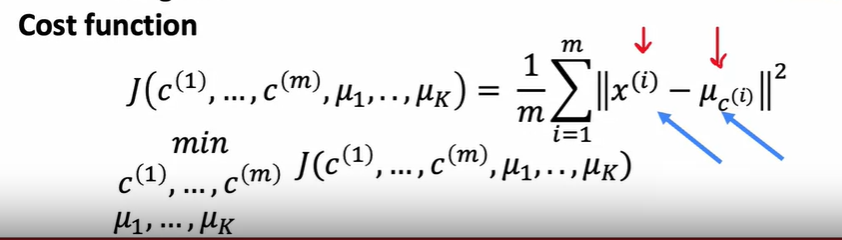
实际上K-means优化一个损失函数, 这个函数称为失真函数 distortion funcion
当损失函数几乎不变时聚类完成
初始值选取
随机选择数据中任意k个点作为初始点 多次选取计算来选择最优的局部最优解
K值选取
肘部法则
- 改变k值进行聚类,绘制失真函数曲线,找到曲线拐点作为k值的取值
- 缺陷 实际上不一定有明确的拐点,且k值变大很可能失真函数一直变小,通过k值变化来找到k值不是一个好的方法
下游需求
- 通过算法的下游需求来决定k值,例如为下游计算方便或为求解结果符合成本限制等
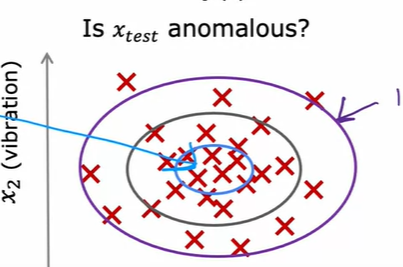
异常检查 Anomaly detection
首先在非异常的情况提取一些特征,在对新的要检测的情况提取相同的特征来判断这个新情况是否与之前的情况相近。
实际实现上通过一种算法来计算当前情况在之前的数据中是否出现次数少(认为出现概率低),当低到一定程度时低于阈值时就认为异常
应用
- 欺诈监测
- 制造业(物品异常)
- 计算机/数据中心
正态分布
高斯分布/钟形分布
均值 标准差 最大似然估计
通过正态分布来拟合
对于向量x出现的概率 用其各个元素出现的概率的乘积来作为其出现的概率
这有个前提,要求各个元素独立,但事实证明就算不独立这种表示方式也不会出错
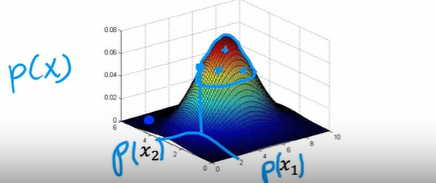
每个概率值都拟合高斯分布
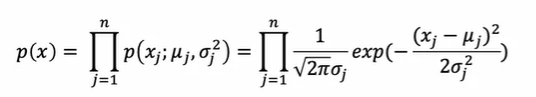 当乘积结果小于设定的eps值时,认为其为异常
当乘积结果小于设定的eps值时,认为其为异常
分布的平均值与方差值为所有向量 X 的计算值
模型评价方法
real-number evaluation
划分数据集,将其分为
- 训练集(无异常 有一点也没关系
- 验证集 有异常
- 测试集 有异常
用训练集训练,验证集用来调整eps和特征数量等参数来提高标记异常的正确率(异常标记异常,正常标错异常),最后在测试集上测试
但是这是无监督学习,实际上训练集只是假设异常与否,由于数据集中异常的数量本就不多,所以影响不大
当数据集很小时,可以:
- 设置训练集
- 设置验证集
- 没有测试集
这样存在过拟合风险,但是是数据量少时最好的选择
同时也可以做偏斜数据集召回率、精确度等的计算
与监督学习
-
非监督学习从概率的角度入手,可以做到从异常样本较少的数据中找到异常,因为是概率的,所以对即使没训练过的异常也可以通过其出现概率来判断是否是异常
-
监督学习是拟合的,对出现过的数据拟合程度高,即训练过的异常就可以较为精确的发现,如果没训练过则难以发现
如果目标是异常样本很少的数据,且可能出现从未见过的新异常形式,使用非监督学习:机器工艺
如果目标数据量适中,几乎不会有新异常出现,使用监督学习:垃圾邮件
特征选择
非监督学习的特征选择要重要过监督学习,因为监督学习实际上通过参数调整来选择放大或缩小特征,而非监督学习不是
在异常检测中,往往更符合高斯分布的特征拟合效果越好
如果不是高斯分布可以转换为高斯分布:
- (加上常数)取对数
- (加上常数)指数变化(开方等)
# 使用
plt.hist(x, bins)
#实时查看是否高斯特征增加
查看一些目前的算法无法检测出的异常,研究其存在哪些特征使得其为异常
增加这个特征来分辨这些类型的异常
组合旧特征为新特征 通过比例等组合具有实际意义的新特征