与监督学习
强化学习常用于机器人控制、规划等
实现在现状x找到一个函数映射y来调整状态 实际上特征x很多,例如机器人行动的参数,环境的参数等特征数量巨大,而正确行动,即标签y实际上很难获取,监督学习难以实现
强化学习通过奖励机制(定义奖励函数)来让模型自己学会调整,当行为符合预期给予奖励,否则给予惩罚(负面奖励)
强化学习例子
假设现在在训练火星车进行土壤采样
其所在的位置等信息综合起来称为一个状态(state),其采取的前往下一个状态(next state) 的 行为(action),并获得这个行为的奖励(reward),行动的**策略(policy) **
Return
给奖励打折扣,建立奖励与行动之间的关系
设定一个(0-1)的权重,为每一步的奖励乘上步数的幂数的权重
这表现了行动对奖励的影响,反映了对开销的考虑
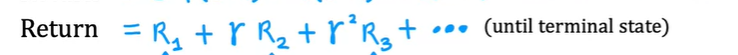 第一个的幂数是0
第一个的幂数是0
Return指的是这种计算下的数值 行动不一样Return的结果不一样
Return用来指导行动,不同行动产生不同的结果,用最大的可能性代表在该状态下的行动指导,做出奖励最大的行动
当存在负面奖励的时候,Return的引入可以将负面的奖励尽可能的往后推迟
决策
Markov Decision Process(MDP)
马尔科夫决策过程
未来只决定于当前状态,而不受之前状态的影响
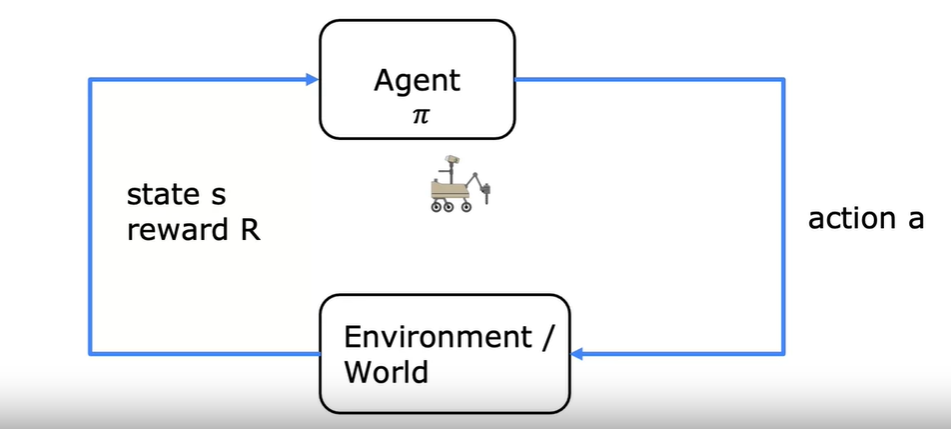
从当前状态出发,判断一个行动后到达的状态和获得的奖励
State action value function
定义Q(s, a)作为状态行动评价函数,其内容为:
- 从某个状态开始
- 采取一个行动
- 之后采取最好的行动
- 获得奖励,计算Return
计算得到的Return就是这个状态下这个行动的评价
最好的行动就是之前遍历过的不同行动的Return值中最大的行动
这种算法也称为 Q* 算法和Q函数
Bellman Equation
贝尔曼等式
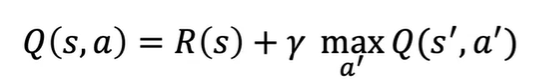
此处的 是之前所提到的每步的折扣
maxQ(s’, a’)在含义上代表最佳的一系列行动带来的奖励,实际上在状态 s’ 做出最佳行动的Return的和
实际上是第一步行动a,到达状态s‘,获得return r 之后最佳行动,获得 就是Q(s’, a’)
Random(stochastic) environment
实际上机器人的行动并不总是遵循指示,可能在往右走的时候因为环境因素往其他方向滑行,这种情况就成为随机环境
在这种情况下,要计算的Q值就不是Return的最大值,而是期望值(平均)的最大值
在马尔科夫决策的背景下,这称为随机马尔科夫决策
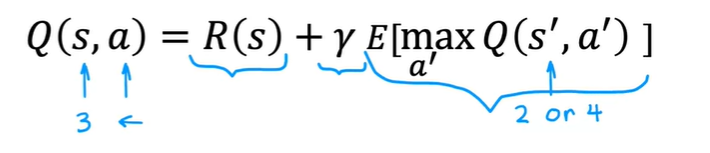
所以Bellman方程变为 立即奖励 + 最大期望奖励
连续马尔可夫决策
continuously MTP
实际中的状态是连续的,其状态为一个向量值,包含空间位置,角度位置等,根据实际意义的不同存在不同的考虑
模型学习
计算Q
Q的计算通过监督学习实现
- 初始化一个参数随机的监督学习模型
- 构建元组(s,a,R(s), s’)记录状态,行动与该状态的Return,下一个状态
- 存储最近的一定数量(例如10000)的元组
- 其中状态s与动作a组成模型输入x,这个状态下计算得到的到达s’的贝尔曼方程组成预测y
- y值就是猜测,用深度学习拟合参数计算Q,计算之后将Q值替换原本的Q值,再次重复进行训练
其中,存储最近的样本进行训练称为——Repaly Buffer,这种数据存储的好处是:
- 动作总是以某种方式影响状态s,如果将获取的到数据之间参与训练,那会形成一种时间序列的关系,如果先将数组存储起来,再随机采样,就可以打破动作之间的联系
- 同时,一个元组可以被多次利用,意味着可以多次学习这一个元组代表的经验
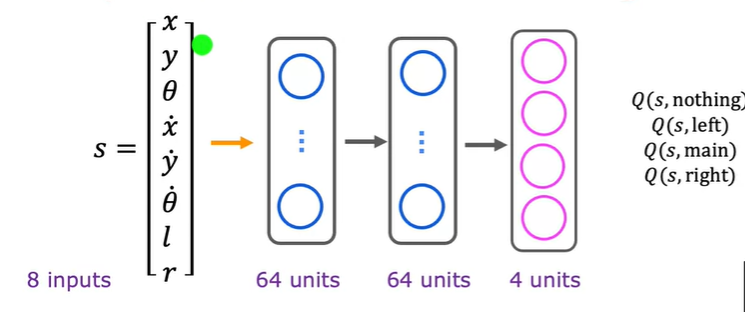 同时输出4个行动导致的4个状态,效率更高
同时输出4个行动导致的4个状态,效率更高
如何求得元组? exploration verus exploitation
可以选择每次采取行动a使得当前猜测的Q最大,但是这样其实并不够好,实际上采用的更多是exploration verus exploitation,即在充分利用当前猜测Q的基础上以小概率进行随机的探索行动,这样可以减少智能体的先入为主,尽可能地多做尝试
这称为 - greedy policy 是采取随机行动地概率 随训练变小,刚开始需要更多的随机性,当Q的估计越来越好,随机性就可以越来越少
Mini-batch and soft update
所谓mini-batch就是将数据划分为较小的batch逐个进行计算,每个batch更新一个预测函数,会使得梯度下降变得嘈杂(挑选出来的batch梯度方向不一定就是全局梯度下降的方向) ,但是速度快
soft update 在更新Q的时候 不直接用新训练的Q_new更新Q,而是选用一定占比的Q_new与Q混合进行更新(例如0.9Q+0.1Q_new),这事实上使得Q的收敛更可靠,减少振荡或转移等