Decision Tree
决策树,深度学习算法
当数据特征是分类值(categorical values) ,即特征为 0 1 值或离散的少数几个代表类别的数值(例如有无胡须,有无花纹)
每一步判断基于某个特征值是否满足分类,满足就往下继续判断,直到算法认为决策完成
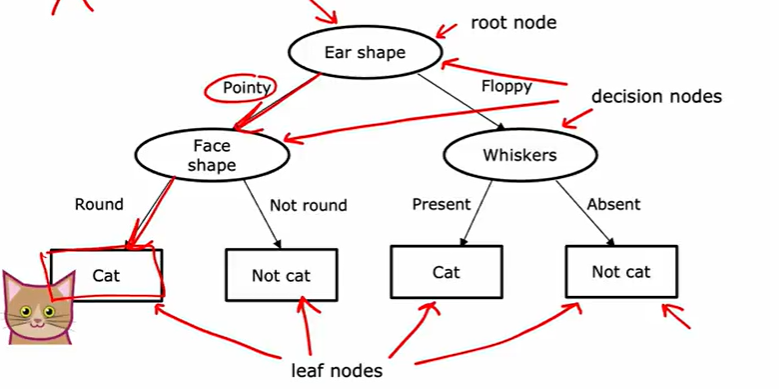
最上方为根节点,决策点为决策节点,最下方为叶子节点
不同的决策方法有不同的精度,决策树算法就是要选出一种决策树使得精度最优
节点选择
如何选择在哪个节点用哪个特征做分割?
最大化纯净度 purity 纯净度为分类中属于主类的占比 选择当前能最大化该值的特征进行分类
什么时候停止?
-
超过最大决策深度 节点的深度被称为跃点数
-
百分百确定决策结果
-
阈值达到要求 纯净度要求 数量要求
树深度小,有利于缓解过拟合
熵与纯度测量
以熵 (Entropy) 来测量杂度(impurity)
熵准则定义为:
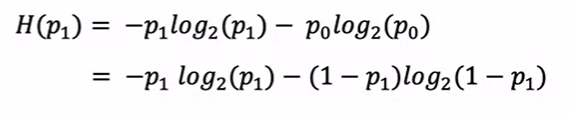
其中,取2为底的对数是为了让曲线最大值为1,取其他值只是会上下拉伸曲线而已,具体曲线如下:
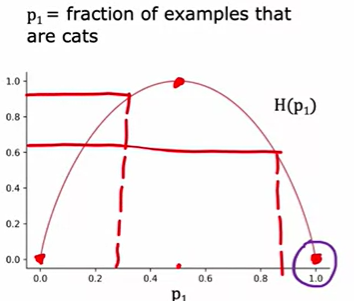
可以看到当两个类别为 1:1 时,熵值最大,两端只有以类时,熵为0 为方便计算
除了熵准则外还有基尼指数等确定杂度的方法
在决策树中使用熵准测
熵值的减少称为信息增益 (information gain)
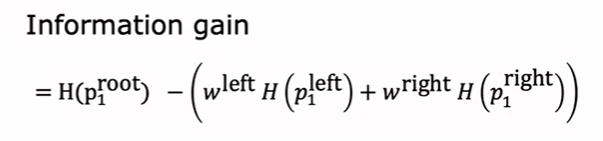
其中 H函数时熵值计算函数,w是决策后分支中数据数量的占比, 是决策后分支中主类的占比
通过信息增益确定决策结点,信息增益越大的决策结点越早出现在决策树中,利于减少深度,加快纯度增加,防止过拟合
类递归实现
确定一个决策树逐步分解为确定一棵决策树,因此确定决策结点的顺序应为树的DFS遍历顺序
One-hot encoding
独热编码
当出现一个特征对应多个类别时,可以拓展决策树为多结点,也可以采用热编码的形式实现
one-hot encoding 将一个特征的多个类别分为多个特征,以0 1 区分有无该特征,其特征值之和为1。
例如现有三种耳朵,尖耳,圆耳,椭圆耳,与其分为三个决策树分支,可以分为三个决策树结点,分别判断是否尖耳,圆耳,椭圆耳来确定耳朵形状,其互斥,判断的结果之和为 1
one-hot encoding 不止可以应用于决策树,实际上在logic 回归,线性回归等也可以应用
连续值的决策
连续值的决策关键在于选定一个阈值使得分类的结果中信息增益最大
以数据间的阈值(在连续值中,以一类区分作为尝试),不断尝试不同的阈值,直到找到最好的信息增益
阈值是指两个数据间的值,看图理解:
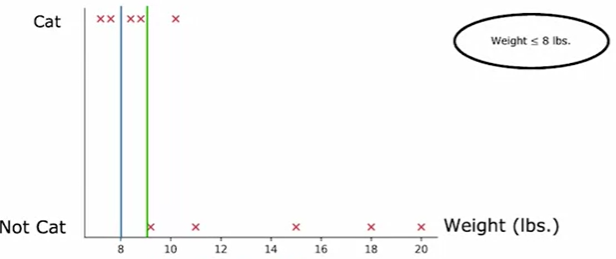
选定两个点之间的值,每次计算信息增益,再改变所选值,至少改变一个点的位置(在线的左边或右边),再计算信息增益
决策树的泛化
当预测值是一个数值时,需要将决策树分类问题泛化为回归问题
将决策依据——纯度 转为 方差的插值
计算不同分类结果的方差,选择最大的信息增益(方差的差值最大)
一直分裂,一直到无法在区分,计算叶节点的均值作为预测值
树系 Tree ensembles
指多种决策树的组合
一种给定决策树在数据微小的变化下可能不再是最佳的决策方案(信息增益不最大),其鲁棒性不佳
为实现算法更强的鲁棒性,可以采用多决策树的方案,让不同的树进行投票,预测值占多的作为最后的预测结果
有放回的抽样 sampling with replacement
每次随机取出一个数据,放回,再随机取出,直到数量满足,来构成一个新的数据集
随机森林算法
依照有返回的抽样方法,反复多次抽样构建决策树,来建立决策树树系
实验证明:当决策树数量不超过100时,其算法精确度都一直随数量增加而增强,超过100,增加数量获得的精度回报开始递减,所以决策树数量不宜过多
这种算法称为:bagged decision tree 因为是虚拟袋子做随机有放回的抽样
但是这样的算法很有可能无法改变最先的几个决策结点,因为它们的信息增益大
为了更好的实现,提出在大的数据集中挑选一定量的子集来构成数据集,这样一来,小的变化可以被探索到,算法的鲁棒性进一步增强,对于预测数据集的变化适应性更强。
当 数据集总量 n 很大时,子集量 k 可以为
XGBoost
在上述的决策树中,决策树每次随机采样的概率是均等的,每次都是在样本中随机的抽取子集,Boosted trees intuition算法旨在刻意练习
刻意练习 例如练钢琴,对于不熟悉的乐章应该多练,而不是每次练习都全部练一遍
算法在每次新采样前对之前的预测结果做一次评估,增加之前预测错误的数据被选中的概率,再采样子集,以此重复多次
但是要增加多少概率是一个复杂的数学问题,在此不做详细探讨
XGBoost eXtreme Gradient Boosting 极端梯度提升
- 开源算法
- 高效
- 默认的拆分条件选择与停止拆分条件
- 正则化防止过拟合
XGBoost 对数据赋予不同的权重,也因此其实不需要多少数据就可以实现不错的精度
# 分类
from xgboost import XGBClassifier
model = XGBClassifier()
model.fit(X_train, y_train)
y_pre = model.predict(X_test)
# 回归
from xgboost import XGBRegressor
model = XGBRegressor()
model.fit(X_train, y_train)
y_pre = model.predict(X_test)决策树与神经网络
如何做选择:
决策树优势:
- 表格形数据(结构化数据) 类别的,连续有值的特征 即分类与回归
- 快 相比神经网络的训练更快
- 可解释 当规模较小时可以理解是如何做到分类或回归的
神经网络:
- 文本,音频,图像等(非结构化数据)同时结构化数据与混合数据也可以实现
- 迁移学习
- 更易于多个组合起来一起训练