什么是集成学习
多个学习器有效结合,以投票等方式决定最后结果,使得总体的泛化性能优于任何一个学习器
个体与集成
集成学习实现为:先学习一组个体学习器,用某种策略将他们组合在一起
如果学习器属于同一类,那么成为同质(homogeneous),否则称为异质(heterogenous)
- 同质集成:个体称为基学习器(base learner),算法称为基学习算法
- 异质集成:个体称为组件学习器
如何实现泛化?
- 准确性
- 多样性
对于二分类,假设基分类器之间相互独立,且错误率相等为 ,可以将集成器的预测看作一个伯努利实验,当所有基分类器中不足一半预测正确时,集成预测错误,所以错误率可以计算为:
含义是每个弱分类器的预测加和来做为集成学习的分类器输出。
含义是:k从0到二分之一的总分类器个数,其中做二项分布计算,在T个分类其中选k个分类器,计算只有这k个分类器错误的概率
逻辑上认为分类器预测错误的数量不能超过半数(必须严格多数),同时算法给出一个上界(Hoeffding不等式或Chernoff界得到),用于简化分析
此时,集成错误率随基分类器的个数增加而指数下降,前提是分类器之间相互独立,而实际上对于两个不同的分类器,对于某个测试样本,有:
二者难以独立,因此,个体学习器的准确性和差异性本身就是一对矛盾的变量,如何训练 好,但彼此不同 的个体学习器正是集成学习研究的核心
Boosting
个体学习器的训练存在依赖关系,必须一步一步序列化进行。
基本思想:增加前一个基学习器在训练过程中预测错误样本的权重,使得后续基学习器更加关注这些打标错误的训练样本,尽可能纠正这些错误,一直向下串行直到产生需要的T个基学习器,Boosting最终对这T个学习器进行加权结合,产生学习器委员会
AdaBoost
定义基学习器的集成为加权结合,有
AdaBoost算法的指数损失函数定义为:
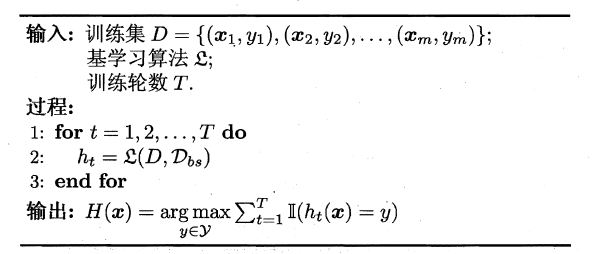
AdaBoost迭代算法:
- 初始化训练数据的权值分布,每个权重分为 1/N
- 训练弱分类器,如果某个样本点已经被准确地分类,那么其权值就降低,相反则提高,权值更新过的样本集用于训练下一个分类器
- 训练得到的弱分类器组合成强分类器,分类误差小的弱分类器的权重大

可以看到权重的分配是基于指数的,实际上这里定义了AdaBoost的损失函数,然后通过优化这个损失函数得到了权重的更新公式
Boosting算法要求基学习器能对特定的分布数据进行学习,也就是可以更新样本权重来学习,更新方法有两种:
- 重赋权法:对每个样本附加权重,样本的属性和标签都要加权?
- 重采样法:部分算法无法接受加权样本,此时应该根据每个样本的权重,对训练数据重采样,初始时样本权重一样,每个样本被采样的概率一致,从N个原始训练样本中按照权重有放回的采样N个样本作为训练集,然后计算训练错误率,调整权重,重复采样,集成多个基学习器
从偏差-方差分解来看,Boosting算法更关注降低偏差,每轮迭代都关注训练过程中预测错误的样本,将弱学习器提升为强学习器,从AdaBoost算法流程来看,标准的AdaBoost只适用于二分类问题。
损失函数
- 前向分步加法模型
AdaBoost其实是前向分步模型的一个特殊形式,每次学习一个基函数和系数
- 指数损失函数
Bagging
集成学习关键在于保证基学习器准确性的同时增加其多样性,多样性的实现基本在于 采样
Bagging是一种并行的集成学习方法,也就是说训练器训练之间没有前后关系,可以同时进行。
Bagging是有放回的采样,这样训练集中会有接近36.8%的样本没有被采样到,按相同的方式重复采样,可以得到T个数据集,训练得到T个学习器,对输出进行集成,得到
算法流程图如下:
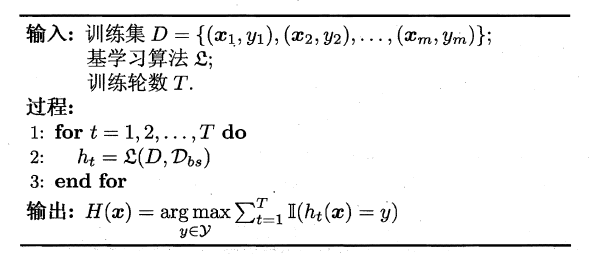
实际上Bagging通过样本的扰动来增强基学习器之间的多样性,因此适用于哪些对数据集比较敏感的学习:神经网络/决策树等,从偏差-方差来看,Bagging算法关注降低方差,提高稳定性。Bagging可以很简单的移植到多分类、回归等问题,也就是说AdaBoost关注于降低偏差,而Bagging关注于降低方差
Random Forest
是Bagging的拓展体,基学习器是决策树,组成森林
随机指的是划分属性是随机的,训练基学习器采用有放回的采样方法,引入属性扰动,在基决策树的训练过程中,选择划分属性时,RF先从候选属性集中随机挑选出一个包含K()个属性的子集,再从这个子集中选择最优的划分属性
相比一般的Bagging,随机森林多样性更大,集成时初始性能较差,准确度有所下降,随基学习器数目增大,随机森林会收敛到更低的泛化误差。
综合策略
学习好基础学习器之后,如何做集成?
平均法
直接平均或加权平均法,个体学习器性能相差较大就加权,否则简单平均法
投票法
- 加权投票:
分数加权,再进行投票
- 相对多数投票法
直接投票,找票数相对最多的
- 绝对多数投票法
可以拒绝,可靠性高,原理是对有一类的票数大于半数,把该类作为预测
学习法
学习一个预测器
将基学习器的输出和样本作为预测器的输入进行预测
多样性
- 数据样本扰动 不同增强数据训练不同学习器
- 输入属性扰动 随机从原空间拿子空间(子集)来训练基学习器
- 输出表示扰动 输出优化,例如提取特征,再拼接
- 参数扰动 不同参数