2021年 google
优势
在21年所有的领域取得极佳的效果,得到只要预训练的数据集足够,在CV上并不一定要使用到CNN架构,而是使用一个NLP的标准Transformer
打破了CNN的壁垒,打通了多模态的研究
任务处理
Vit可以实现CNN实现不了的任务类型
- Occlusion 闭塞 图片严重遮挡,看不清楚内容
- Distribution Shift 分布偏移 纹理去除等改变图片原来分布
- Adverarial Patch 对抗性补丁 在关键部位进行遮挡(人脸等)
- Permutation 重排 图片分块打散排列组合
引言
Transformer应用
Transformer在NLP的应用已经是常态,但是在CV领域的应用却十分有限,其中一部分原因在于计算量
Transformer的计算需要输入一个序列,序列计算自注意力(),要求序列长度不要太长,但是倘若把图像直接当成Transformer的输入,其展开成一维的序列长度太大,无法计算
所以现有的应用都是对这个计算的优化,有CNN取得特征图后再进行计算;使用滑动窗口计算;轴自注意力,拆分长和宽两个维度,分别做自注意力等等
Vision Transformer的做法是: 将图片分成16 x 16 的patch(224),即分成14 x 14的长宽,相当于句子分成一个一个的单词,用序列长196 计算Transformer,进行有监督的训练
分析
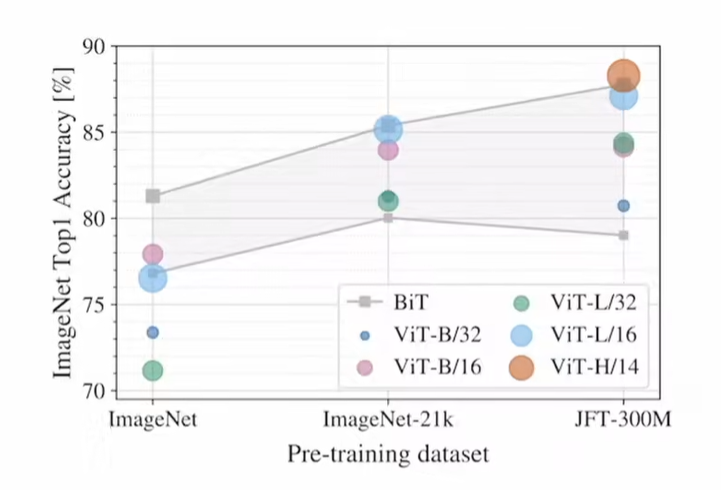
这里讲明了在不同规模的预训练集上,ViT的精度与原因
在规模较小的预训练集(ImageNet)上,ViT可以取得不错的效果,但是差于ResNet系列
因为CNN存在 归纳偏置(inductive biases),相对少的数据做训练效果优于不存在归纳偏置的ViT
最后指出在大数据集上取到了极高的精度
结论
方法只在初期使用了部分图像领域的知识(归纳偏置),例如patch划分,位置编码等,其余没有使用,好处是不需要有过多的图像领域专业知识,直接train,而且相对cheap
提出展望 为后面挖坑,提出为解决的问题和可能的方向
相关工作
分析Transformer在NLP的工作,基本原理 分析Transformer在CV的工作,基本原理
列举工作相近的论文及其成果
主体(Method)
方法
先对图片分patch,输入Linear Projetion of Flattened Patches 做编码,增加位置编码(因为图片的patch存在位置信息,如果位置不一样,则图片不一样)作为Transformer Encoder的输入
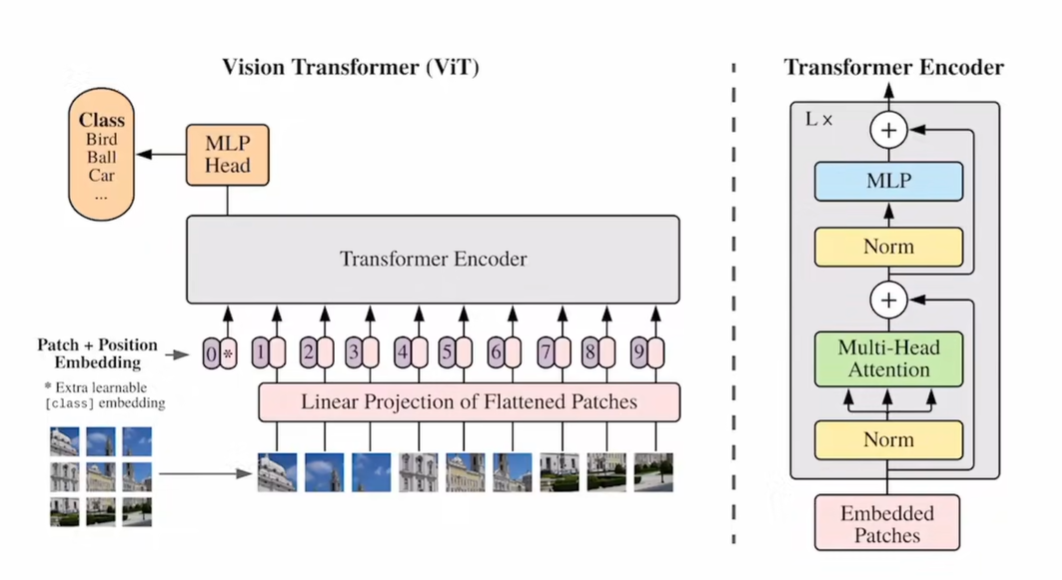
完整流程: 224图片分成196个patch,每一个patch 16 x 16 x 3,一共768,即Linear层的维度为 768 x 768,输出为 196 x 768大小,还需要一个CLS token 所以最后序列长度为197x768,最后加上位置信息(求sum)
- Encoder中的Norm是LN
- 先经过多头自注意力,例如是12个头,则经过多头后每个头输出 197x64
- 再拼接起来,恢复768
- 最后MLP放大,放大四倍,再缩小投射回768
- 由于输入输出一致,可以叠多层Encoder
多次经过Block后,CLS特征认为是全局的特征,经过MLP后实现分类
位置编码使用的是1D position embeddings
消融实验
传统CNN使用的是GAP(globally average-pooling)得到最后的全局特征,作为分类依据
Transformer使用的是CLS token作为全局特征
其实也可以将最后的全部输出作为全局特征,效果相似,但为了与NLP的Transformer接近,本文使用的是CLS方法
关于position embedding也做了消融实验
- 一维 1,2,3……
- 二维 11,12,13……
- 相对距离
但其实最后的结果并没有多少区别,原作者认为是因为因为patch维度不多,排列组合不难,不同类型的位置信息对模型的影响并不大
分析
实验分析归纳偏置对传统网络和ViT的影响,实践证明了小数据集下,ViT效果远不如残差网络,大数据集下开始有所超越
在冲点数的时候使用了训练的一些技巧,像是Dropout、weight decay等等,不利于研究模型本身的特性,所以重新做了few-shot evaluation
这种实验做起来速度较快,同时被论文中用于进行消融实验
利用这种实验可以体现出模型本身的特性,同时可以论证归纳偏置的论点