目前所了解的内容来看,行人搜索有两个方向,一个是ReID,一个是无监督方向
行人重识别(Person Re-identification)
简称ReID
在人脸识别技术失效的情况下,ReID技术要求做到在监控画面中识别出人像信息
表征学习(Repersentation Learning)
CNN可以提取表征特征,所以行人重识别问题可以看作是分类问题:
- 分类子网络,对图片进行ID预测
- 验证子网络,对预测结果进行验证,判断是否与原ID属于同一个行人
但是光靠ID信息不足以学习出一个泛化能力足够强的模型,通过对行人属性的标注,训练模型准确的预测出ID的同时,识别出行人的各项属性(头发,穿着等),可以提高网络的泛化能力
度量学习(Metric Learning)
旨在学习两张图片的相似度,在行人重识别这一领域上,关键在统一行人的相似度大,不同行人的相似度小,常用的损失分为:对比损失,三元组损失,四元组损失,难样本三元组损失,边界挖掘损失
对比损失(Contrastive loss)
训练孪生网络,输入一对图片,可以为同一行人,也可以是不同行人
定义损失函数
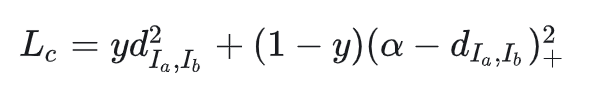
y为1则图片相同,称为正样本,为0则不同,称为负样本, 为根据实际设计的阈值,d为两张图片的欧式距离
当y=1,d应该越来越小 当y=0,d应该越来越大,直到超过阈值
三元组损失(Triplet loss)
三张图片,分为一对正样本,一对负样本,分别称为固定图片(Ahchor)a,正样本图片(Positive)p和负样本图片(Negative)n
损失表示为
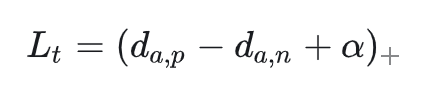
实现正样本对之间距离小,负样本对距离大, 为自定义参数
后续论文提出改进
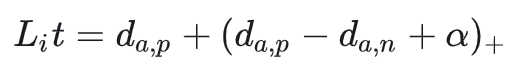
保证网络在特征空间把正负样本推开,保证正样本对之间的距离很近(原本的函数中可能只导致负样本距离很远,抽象认为正负样本对之间距离相互影响)
四元组损失(Quadruplet loss)
四张图片,固定图片,正样本,负样本,和负样本2(n2),两张不同行人ID的图片
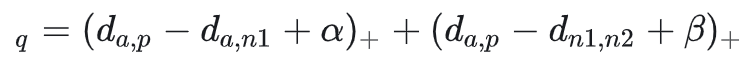
通常 小于 ,称前一项为强推动,后一项为弱推动。增加了第二项不共享ID,考虑了正负样本之间的绝对距离,使得模型可以学到更好的表征
难样本采样三元组损失(Triplet loss with batch hard mining, TriHard loss)
三元组改进,三元组是简单随机采样,但是这种采样如果大量样本都是简单样本,就不利于网络学习更好的表征,大量论文发现难样本能提高网络的泛化能力
例如提出TriHard Loss,基于批次的在线难样本采样方法
每个batch挑p个ID的行人,每个行人挑K张照片,每个batch有P * K张照片,对batch的每一张图片a,挑选最难的正样本和负样本组成三元组
损失函数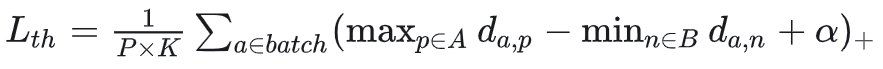
其中,A是与固定图片相同ID的图片集,剩下其他图片集为B,用欧式距离计算最不像的正样本p和最像的负样本n来计算三元损失
边界挖掘损失(Margin sample mining loss)
三元组只考虑了正负样本对的相对距离,为引入正负样本对之间的绝对距离,四元损失加入了另一个负样本
再将难样本挖掘的思想引入,得到
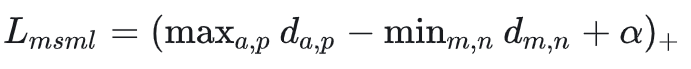
此时,因为挑出来的全部数据中最难的一个正样本对和负样本对,所以可以认为这两个距离是正对和负队的上界(小于)和下界(大于),所以称为边界样本挖掘损失
即兼顾了相对距离,绝对距离,还使用难样本采样的度量方法
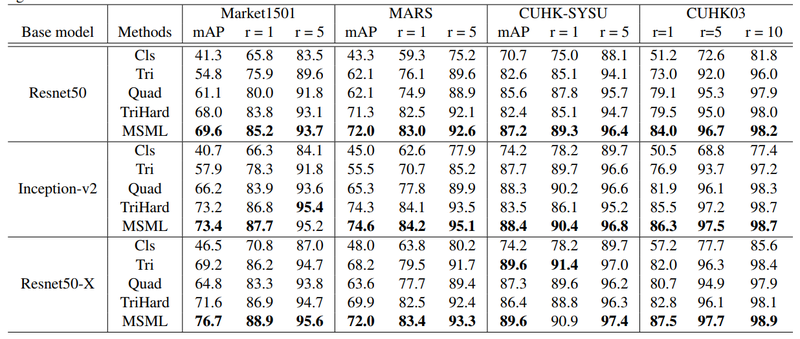
损失函数性能对比
局部特征(local feature)
简单来说就是全局特征遇到了瓶颈,于是研究起了局部特征
- 图片切块,局部特征提取方法,一般是垂直分割(横着切),切好之后送到LSTM网络进行特征提取,融合了局部特征
- 图像对齐,切块后提取局部特征进行识别时,如果图像没对齐,会出现例如上半身与头部做对比等问题,导致识别结果出错,所以提出图像对齐
- 使用先验经验,例如人体姿态,骨架关键点模型等,再使用仿射变换
- 或使用关键点技术后,利用关键点提取出感兴趣区域(ROI)
- 或者利用关键点将人体分为头,上身,下身三个部分 再将局部和全局一起丢给模型做特征提取,得到最终的特征
基于视频序列
单帧信息总是有限的,多帧相对之下可以考虑帧与帧之间的运动信息,在单帧CNN提取特征的基础上使用RNN来提取时序信息
传统方法是CNN提取单帧信息,再送去RNN提取序列信息
代表方法之一有累计运动背景网络,提取光流信息
提取图像信息的同时提取光流特征,融合后输入到RNN,可以得到融合了内容和运动信息的特征
另外,多帧也可以弥补单帧情况下图像遮挡等问题,
基于GAN造图
主要克服几个问题
- 数据量少,过拟合等问题
- 摄像头bias问题,生成摄像头转移(转移到另一个摄像头)图
- 环境bias问题,将行人转移到不同的环境
- 姿态不变,生成多种姿态