Key Issue
以往的网络都依赖于大数据集,而医学等任务数据集很少,需要有一种方法来解决
滑动窗口方法通过平移窗口得到大量patch,弥补了数据集问题,且可以定位,但是又以下缺陷:
- 很慢,因为patch存在很多冗余,计算效率低
- 定位精度与上下文之间的平衡,大patch提供上下文,但是降低定位精度,小patch提供精度,但是没有上下文
文章关注于提出一种新方法,在小数据上实现高精度分割
Motivation
- 密集预测:分割任务属于密集预测任务,上采样可以保证端对端,且可以利用下采样中间过程的结果
- 数据量少:解决小数据集依旧要从构建训练数据下手,如果图像少,那就通过patch分出多个数据,但是要想办法保留原始数据的上下文
- 计算量:全卷积网络可以输入整图,而且显存有限,可以尽可能用大图代替大批次
- 特征学习:解码器和编码器,编码过程中的中间层输出可以用于提供细节信息,解码器则提供抽象语义信息,两者结合可以充分学习到特征
Method
Overlap-tile
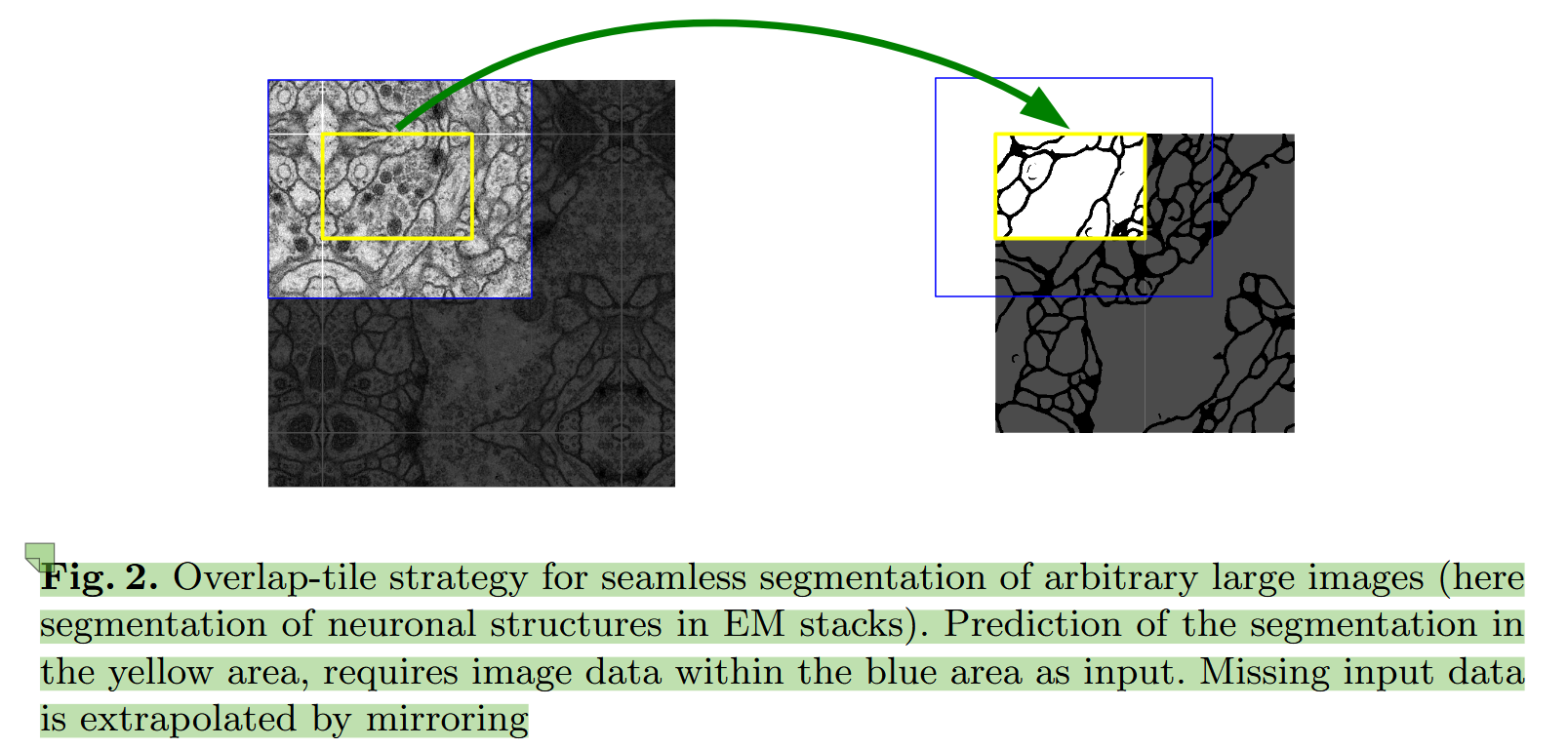
右边是原图(有效的图),左侧是镜像拼接之后的图片,使用大卷积核时,可以扫过拼接的镜像部分,得到这部分上下文(平移不变性),用于预测
上图描述了这个重叠切片方法,这个方法是在无法整图输入的情况下,配合分patch机制,保留空间上下文的方法,同时每次只保留中间区域的预测,去除了部分冗余计算
Model
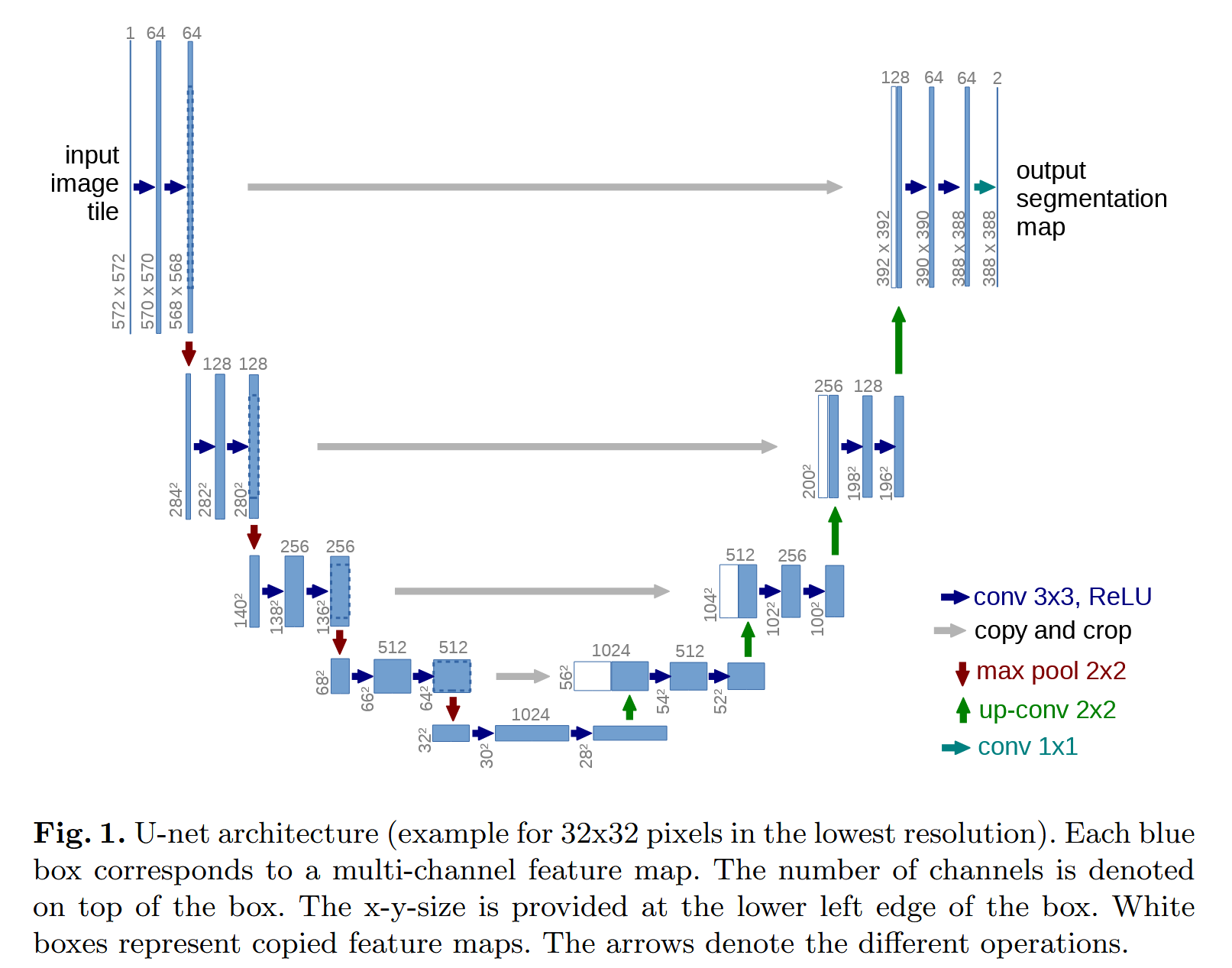
编码器使用3卷积x2+ReLU+2采样,解码器与对应层的编码器中间结果裁剪后拼接,采用2卷积上采样,再3卷积x2
编码器往下逐层学习,其中间结果为解码器提供细节信息,裁剪是因为每次卷积都会在边界引入无用信息
拼接是通道拼接,通过卷积将通道转化为尺寸,实际上就是结合两种信息做特征融合
Training
提出加权交叉熵方法
因为背景远大于前景,如果直接学习,模型会偏向于预测背景来实现更低的损失,所以提出要对每个像素加权,像素权重由类别出现的频率来定,出现少的权重高
同时,还需要加强边界的权重,d1是像素和最近边界的距离,d2是次进的距离,当距离越近,权重越大,强调边界学习
数据增强
做了很多的弹性变换,灰度变换,平移变换等等来增加数据量
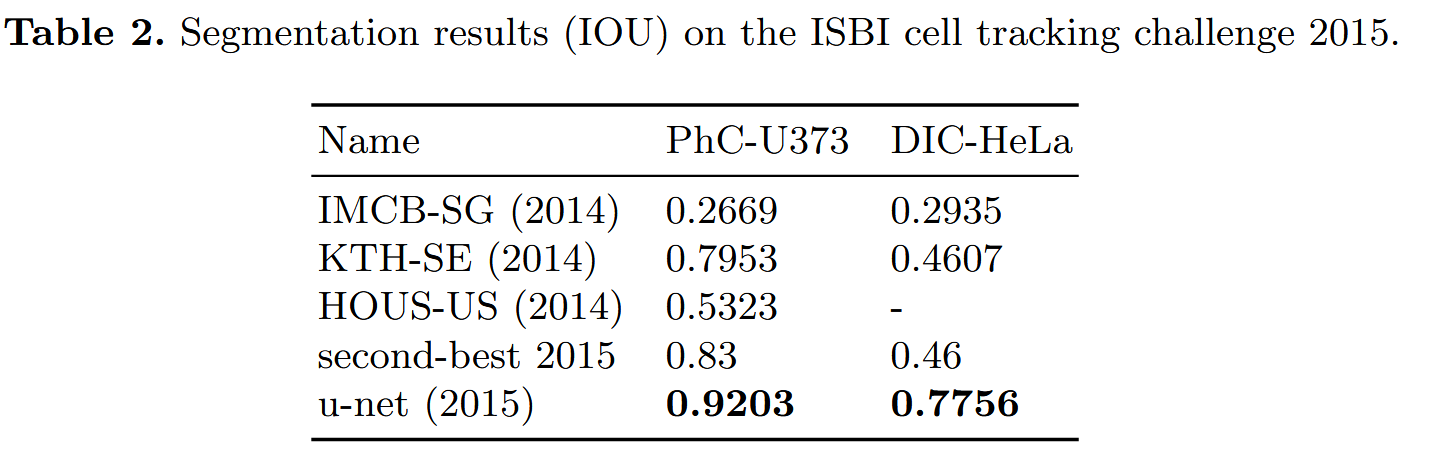
Result
Conclusion
U-net提出了一个不完全对称的U形结构,通过编码解码过程的跳跃连接,overlap-tile策略等,训练了一个端对端的卷积网络,解决数据少,计算量大,预测慢等问题,取得卓越成果,且适用于很多下游任务
Refer
【代码】
- Mastering U-Net: A Step-by-Step Guide to Segmentation from Scratch with PyTorch | by FernandoPC25 | Medium
- UNet for Building Segmentation (PyTorch)
【参考】