Key Issue
- 红外的特性没有被挖掘(更长的波长,更低的敏感性),现有方法对红外的增强只是次优
- 神经网络的前传会导致高频细节丢失
Motivation
- 高频细节丢失,那就特化一种图像处理变换来专门提取,多尺度的做特征学习
- 提升红外图像的深度特征学习能力,可以用CLIP这种大模型来做
Method
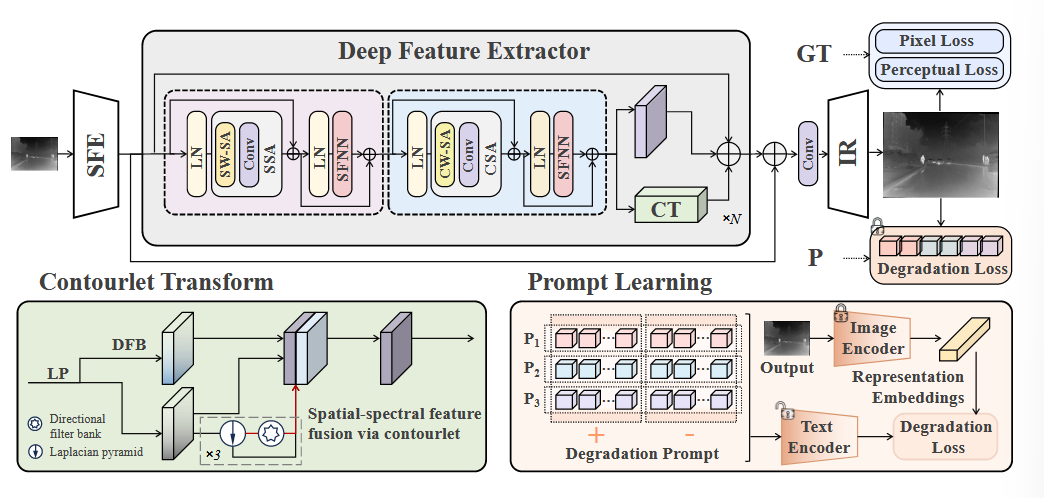
- 浅层特征提取模块
- 基础卷积
- 深层特征提取模块
- Contourlet 变换 + 残差多尺度卷积
- 高分辨率重建模块
Contourlet Residual
- 空间自注意力
- 不重叠窗口做局部自注意力
- 通道自注意力
- 不重叠窗口做通道自注意力
- 空间前馈网络
Contourlet Residual
将特征进行拉普拉斯金字塔分解(Laplacian Pyramid decomposition),得到高频信息
其中,公式含义是做一次高斯滤波下采样(可逆的下采样变化),然后得到一个下采样结果,再上采样到原来的尺寸,并于原来的图像相减,得到没法在上采样时恢复的高频细节信息(因为模糊)
高频部分每一层取出来经过后续处理,低频部分(即每次高斯滤波的结果)继续往下做分解
再将高频信息通过多方向分解(DFB)得到多尺度的特征
通过这个卷积网络得到细节特征,用于后续的重建
Pixel Shuffle
像素重排,先通过卷积上采样倍,通道数提升到,然后进行重排,的得到 的最终图像
- 轻量高效
- 有学习有采样
重建之后的图像用于后续的Prompt学习
Prompt Learning
利用CLIP来生成正负对,逻辑上是
- 先训练得到一个向量输出,与图像特征相近,也就是Prompt
- 再用这个Prompt来训练重建模块,让重建的特征与这个相近
Prompt是通过设置两个encoder,其中图像encoder是固定的,文本encoder是非固定的,输入一个文本向量,得到一个特征向量,并期望这个特征向量与图像特征向量相似,即得到正向(优质的)、负向(模糊的)的文本描述prompt
再让SR图像与正向的文本向量特征接近,与负向的远离
Conclusion
方法新颖,挖掘了图像特征,效果显著
但是论文混乱,或者行文逻辑差,应该是两种新方法叠一起,前后不搭