什么是聚类
在 “无监督学习”(unsupervised learning)中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础
聚类则是试图将数据集的样本划分为若干个互不相交的类簇,从而每个簇对应一个潜在的类别。
聚类直观来说就是将相似的样本聚在一起,形成一个类簇(cluster),因此如何度量相似性(similarity measure)将作为首要问题,这又称为距离度量,而性能度量为评价聚类的好坏提供了一系列有效性指标
距离度量
几类常用的度量方法
一般的,距离度量方法要满足一些基本性质:
- 非负性:
- 同一性:
- 对称性:
- 直递性:
其中,直递性同时也是三角不等式,两边之和大于第三边
常用的距离度量方法是:闵可夫斯基距离(Minkowski distance)
当p=1时,闵可夫斯基即曼哈顿距离(Manhattan distance)
当p=2时,即欧式距离(Euclidean distance)
属性分为连续属性和离散属性,对于训练值的属性,一般可以被学习器所用,有时会根据具体的情形做相应的预处理:例如归一化等,离散值则需要进一步处理:
- 如果属性之间存在序关系,则将其转化为连续值,例如
高、中等、矮可转换为{1, 0.5, 0} - 如果不存在序关系,则转化为向量形式,例如:性别可转换为
{(1, 0), (0, 1)}
连续属性和离散属性都可以直接参与计算,其反映一种程度关系,称为有序属性,而对于不存在序关系的离散属性,称为无需属性
对于无需属性,一般采用VDM进行距离的计算,其定义为:
其中:
- 是某个离散属性
- 是类别总数
- 是属性取值为的样本总数
- 属性取值为且真实类别为的样本数
就是经验概率
所以VDM可以写为:
通过经验概率将离散属性改为连续属性,度量 a,b在所有类别分布上的距离
于是,计算两个样本之间的距离时,可以将闵可夫斯基距离和VDM混合一起计算
对于聚类而言,这些距离的度量方法可以被用于度量相似性,此时就不一定满足上述四个基本性质,这种方法也称为非度量距离(non-metric distance)
性能度量
聚类算法有两种聚类性能度量指标:外部指标和内部指标
外部指标
将聚类结果与某个参考模型的结果进行比较,以参考模型的输出作为标准,评价聚类的好坏
定义
其中:
- 代表聚类结果, 代表参考结果
- 代表聚类结果属于同一类,参考结果也属于同一类
- 代表聚类同类,参考不同
- 代表聚类不同,参考相同
- 代表聚类不同,参考不同
基于这四个值可以计算出一些常用的外部评价指标
- Jaccard系数(Jaccard Coefficient),简称JC
- FM指数(Fowlkes and Mallows Index),简称FMI
- Rand指数(Rand Index),简称RI
m是样本数
其范围均是 ,取值越大越好
内部指标
簇内高内聚,簇间低耦合
分别是:
- 簇内平均距离(越小越好)
- 簇内最大距离(越小越好)
- 簇间最小距离(越大越好)
- 簇中心距离(越大越好)
基于上述四个距离,可以得到一下常用的内部指标
- DB指数(Davies-Bouldin Index),简称DBI,越小越好
- Dunn指数(Dunn Index),简称DI,越大越好
另外几类外部评价指标
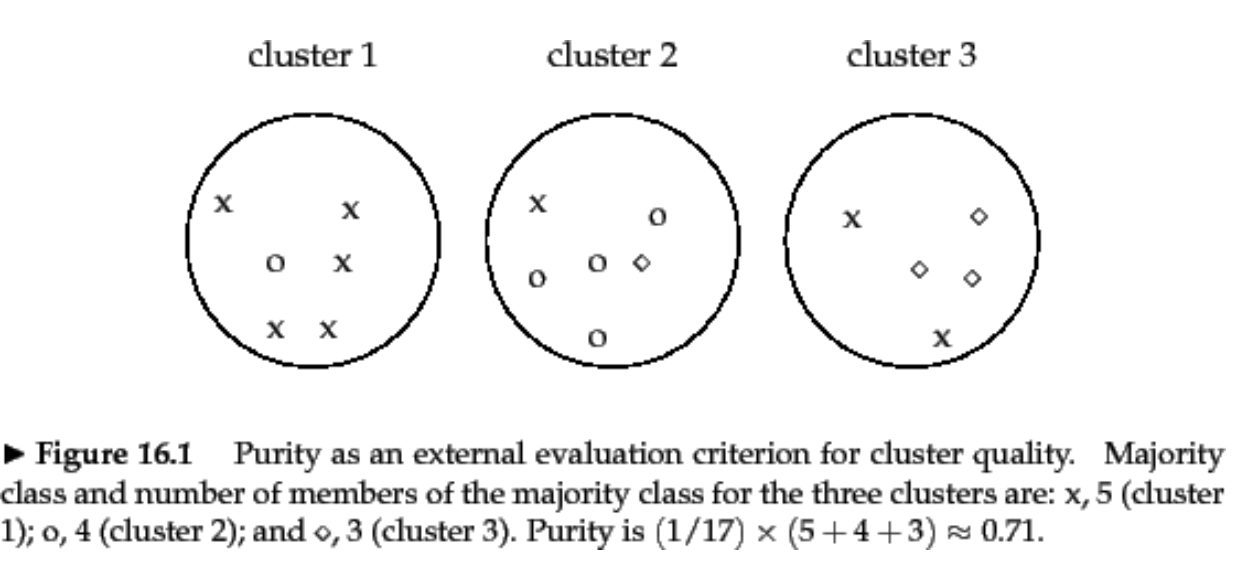
纯净度(Purity)
其中,表示总的样本个数,表示聚类簇的划分,表示真实类别的划分
- 给每个聚类簇分配一个类别,这个类别的样本在该簇中出现的次数最多,然后计算K个聚类簇的这个次数之和,再进行除以 归一化
- 无法用于权衡聚类质量与簇个数之间的关系
NMI(Normalized Mutual Information)
归一化互信息
其中, 表示互信息,H为熵,当 取 2 为底时,单位为 bit,取e为底时单位为nat(熵值定义见 信息熵)
其中,, , 可以分别看作样本属于聚类簇,属于类别 ,同时属于两者的概率,并依据概率的极大似然估计推导,得到第二个式子
互信息表示给定类簇信息 ,类别信息 的增加量,或者说不确定度的减少量
可以直观的写为:
- 互信息的最小值为0,当类簇相对于类别是独立随机的, 对 没有带来任何有用信息
- 与 关系越密切,那么 越大,如果 完整重现了 ,则互信息最大(熵值为0)
- 当 时,即类簇数和样本个数相等,MI 也能达到最大值。所以 MI 也存在和纯度类似的问题,即它并不对簇数目较大的聚类结果进行惩罚,因此也不能在其他条件一样的情况下,对簇数目越小越好的这种期望进行形式化
而NMI则可以解决上述问题,因为熵会随簇的数目增大而增大,当 时, 会达到最大值 ,使得 保持比较低
Note
为什么采用
因为它是 的 紧上界,保证NMI 归一化
计算步骤
- 计算联合概率分布
- 计算边际分布
- 计算熵和互信息
- 归一化计算NMI
ACC
用于比较获得标签与数据提供的真实标签
其中, 表示数据 对应的标签和真实标签,n为样本数, 表示指示函数
map时最佳类标的重现分配,保证统计的正确,一般最佳重分配通过匈牙利算法(Kuhn-Munkres or Hngarian Algorithm)实现,在多项式时间里求解分配问题
Note
为什么重分配?
因为得到的聚类结果和真实标签的 数值 可能不一一对应,可能同一簇但标签不同,需要重映射来做对比
原型聚类
基于原型的聚类
通过参考一个模板向量或模板分布的方式来完成聚类,例如K-Means基于簇中心来实现聚类,混合高斯聚类则基于簇分布来实现聚类
K-Means
先随机指定类中心,根据样本与类中心的远近划分类簇,再重新计算类中心(属于一个簇的算一个中心点),迭代直到收敛。迭代过程并非主观想象,事实上若将样本的类别看作“隐变量”(latent variable),类中心看作样本的分布参数,这个过程实际上就是EM算法的两步走策略,其根本的目的就是为了最小化平方误差函数E

学习向量量化(IVQ)
LVQ也是基于原型的聚类算法,使用样本的真实类标记辅助聚类,首先LVQ根据样本的类标记,从各类中随机选出一个样本作为该类的原型,组成一个原型特征向量组,再从样本集中随机挑选一个样本,计算其与原型向量组中每个向量的距离,选取距离最小的原型向量所在的类簇作为划分结果,再与真实类标比较
- 如果划分结果正确,则让原型向量离这个样本近一些
- 如果划分不正确,让原型向量离这个样本远一些

高斯混合聚类
高斯混合聚类采用高斯分布来描述原型,假设每个类簇中的样本都服从一个多维高斯分布,那么空间中样本可以看作由k个多维高斯分布混合而成的
对于多维高斯分布,其概率密度函数如下:
其中, 表示均值向量, 表示协方差矩阵,看出一个多维高斯分布完全由这两个参数决定,定义高斯混合分布为:
称 为混合系数,这样空间中样本的采样过程可以抽象为:
- 选择一个簇(高斯分布)
- 根据对应的高斯分布密度函数进行采样
此时采用贝叶斯公式:
此时只需要选择 最大时的类簇并将该样本划分到其中。
Note
这一步是贝叶斯吗?
实际上不是,这一步开始就是EM算法,朴素贝叶斯无法解决这个问题是因为似然函数中存在一个隐变量,其含义是当前数据点属于哪个分布,这在式子中没有显示指明(只是要求归属那一类时最大),所以此时使用EM算法,先引入 ,计算E步(上述公式),再计算M步(最大化)
从贝叶斯分类角度来看,这里其实 就是类先验, 就是类条件。但这里没有真实类标信息,对于类条件概率,并不能像贝叶斯分类那样通过最大似然法美好地计算出来(见贝叶斯分类器),因为这里的样本可能属于所有的类簇,这里的似然函数变为:
其中 是遍历样本, 是遍历类簇
最大似然法计算不出所有的参数,应该用EM算法,对高斯分布的参数进行随机初始化,计算各个 ,再最大化似然函数(对分别求参数的偏导),迭代更新

密度聚类
密度聚类从样本角度考察样本之间的可连接行,基于可连接性拓展疆域(类簇),最著名的算法时 DBSCAN 算法
- -邻域: 对 ,其 -邻域包含样本集 中与 的距离不大于 的样本,即 ;
- 核心对象 (core object): 若 的 -邻域至少包含 个样本,即 ,则 是一个核心对象;
- 密度直达 (directly density-reachable): 若 位于 的 -邻域中,且 是核心对象,则称 由 密度直达;
- (必须在邻域中)
- 密度可达 (density-reachable): 对 与 ,若存在样本序列 ,其中 且 由 密度直达,则称 由 密度可达;
- (即为传递性,并不一定要在邻域内)
- 密度相连 (density-connected): 对 与 ,若存在 使得 与 均由 密度可达,则称 与 密度相连。
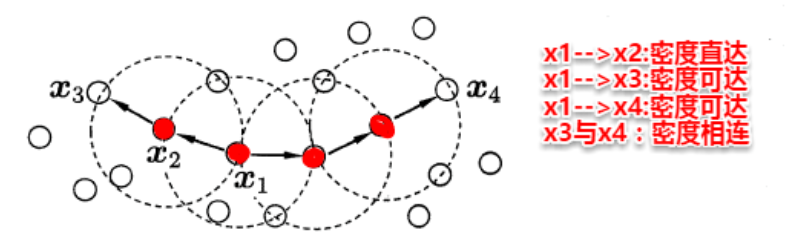
DBSCAN是找出一个核心对象所有密度可达的样本集合形成簇,找到一个核心对象A,找到所有密度可达的样本集合,形成一个密度相连的类簇,直到所有的核心对象都遍历完。

层次聚类
树形结构的聚类方法,自底向上结合策略(AGNES算法),其基本步骤是:
- 初始化,将每个样本归为一类,计算两类之间的距离,也就是样本之间的相似度
- 寻找相似度最大的两个类,归为一类
- 重新计算新产生成的这个类与各个旧类之间的相似度
- 重复2,3直到样本都归于一类
衡量相似度有多个方法:
- 单链接(single-linkage),取类间最小距离
- 全链接(compelte-linkage),取类间最大
- 均链接(average-linkage),取类间两两平均距离
